多模态学习是现在研究关注的热点。芝加哥伊利诺斯理工学院计算机科学系的学者最新《多模态机器学习》综述论文,从数据模态角度综述了最新多模态机器学习的进展。

我们以多感官的方式感知世界,与世界交流,不同的信息源经过人脑不同部位的复杂处理和解释,构成一个复杂而和谐统一的感知系统。为了赋予机器真正的智能,融合不同模态数据的多模态机器学习近年来随着技术的不断进步,成为一个日益热门的研究领域。本文从一个新的角度对多模态机器学习进行了综述,不仅考虑了纯技术方面,而且还考虑了不同数据模态的性质。我们分析了从视觉、音频、文本等各个数据格式的共性和独特性,然后以视觉+X的组合分类介绍了技术发展,其中视觉数据在大多数多模态学习工作中发挥着基础作用。我们从表征学习和下游应用两个层面研究了现有的多模态学习文献,并根据它们与数据本质的技术联系进行了额外的比较,例如,图像对象和文本描述之间的语义一致性,或视频舞蹈动作和音乐节拍之间的节奏对应关系。这种对齐的开发,以及数据模态的内在本质与技术设计之间存在的差距,将有助于未来的研究,更好地解决与具体多模态任务相关的具体挑战,并促进统一的多模态机器学习框架更接近真实的人类智能系统。
https://arxiv.org/abs/2210.02884
引言
我们通过一个多感官的人类系统,通过看物体,听声音,说语言,写和读文本,来感知和交流世界。来自不同来源的信息通常由人脑的不同部位处理[4],[17],[213]。例如,我们大脑中的枕叶是识别和解释视觉所见物体的距离和位置的主要视觉处理中心,而听觉信息通常由颞叶处理,以理解我们所听到的。大脑的语言区,也被称为韦尼克区,位于后上颞叶,主要负责理解书面语言和口语。其他信息处理,如触摸和动作协调,同样由大脑的不同部分处理,构成一个复杂但和谐统一的人类感知系统。人类神经处理的复杂划分意味着来自不同模态的信息应该具有内在的可区分性,但同时也有一些共性,这促使我们结合本文的数据来思考多模态机器学习问题。
在历史上,视觉、音频和文本数据通常被分为不同的研究领域(即计算机视觉、数字信号处理和自然语言处理)。人工智能(AI)的最终目标是为机器带来真正的智能,如今的研究已经远远超出了单一感知视角的开发,而是进入了一个像人类大脑系统一样,以协作方式研究多个感知系统相互作用的时代。随着多模态学习的研究近年来越来越受欢迎,本文提出一项综述,不仅研究了最近文献的技术发展,还详细阐述了数据特征,并检查了这种技术设计的逻辑与各自数据性质之间的联系。
我们首先介绍主要的数据模态,视觉,包括图像和视频。以视觉为基本数据模态,进一步利用其他数据模态,包括音频、文本和其他数据形式,如运动。这些数据模态在数据性质、格式和具体评估标准的不同上既有共性,又有内在的独特性。例如,音频数据可以进一步划分为音乐、语音或环境声音。语音音频与语言和文本有直接关系,而音乐音频则更具主观性,与其他形式有隐性联系。在分析数据特征的基础上,进一步介绍了现有的各种多模态数据集及其适用领域。然后我们介绍了多模态表示学习的主题,根据它们的设置分为有监督和非有监督。该分类揭示了该领域的最新趋势,研究重点从使用人工标注数据的传统监督表示学习转向使用无人工标注数据的大规模预训练。
之后,我们继续讨论多模态学习的具体应用领域。在多模态应用的介绍中,本文按照两个主要方向来组织本文的综述:判别式和生成式应用。通过视觉+X形式的模态组合对每个方向进行分类,其中X主要代表音频或文本数据。我们使用视觉作为主要数据源,因为视觉数据通常在大多数计算机视觉文献的多模态学习工作中扮演着重要和基本的角色。多模态学习可以灵活而实际地应用于广泛的场景中。例如,类似于真实的人类多感官感知系统,将视觉和语言模态相结合是完成字幕任务的关键,该任务旨在提供视觉内容的文本描述,或人们可以很容易地将给定的视觉信息作为线索来想象伴随的声音。在总结了各种流行的多模式应用程序任务之后,我们强调,尽管数据模式和任务目标各不相同,但在这些感兴趣的方向中有共同的技术设计。通过分析和比较它们的技术细节,我们重新审视了数据特征,建立了内在数据性质和现有模型分解之间的联系,并就多模态学习领域的当前挑战和未来方向进行了讨论。
与其他多模态调查[14],[75],[96]相比,我们从数据的角度来处理问题。建立多模态数据本质与方法设计之间联系的新视角,促使我们从两个主要方面对多模态研究的未来进行了深入探讨。一方面,我们相信通过强调和利用某些数据模态的独特特性,将有助于解决与某些数据模态相关的更多具体应用问题。另一方面,了解它们的共性将有助于研究人员建立一个更加统一和协作的框架,最终类似于一个真正的人类智能系统。
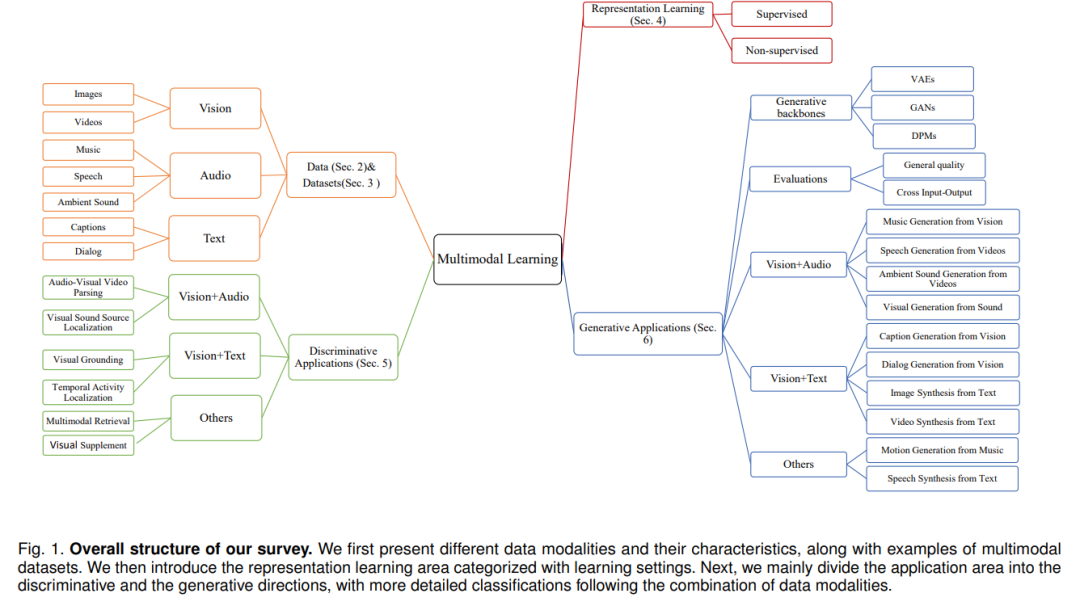
本文的总体结构如下: 在第2节中,首先从不同模态的数据特征方面进行了分析,包括视觉、音频、文本和运动表示。在第3节中介绍了多模态数据集,包括模态属性及其适用的多模态下游任务。然后,我们继续在第4节中介绍多模态表示学习,主要根据它们的学习设置进行分类。在第5节和第6节中,分别提出了具有判别式和生成式任务的具体多模态应用。除了任务和技术介绍之外,我们还做了额外的努力,将现有的文献与第2节中提到的数据特征联系起来,揭示在特定的方法和模型中处理和处理哪些数据属性。上述回顾构成了我们在第7节讨论现有挑战和未来可能方向的基础。第8节包括最后的评论和结论。其主要结构也如图1所示。
多模态数据集

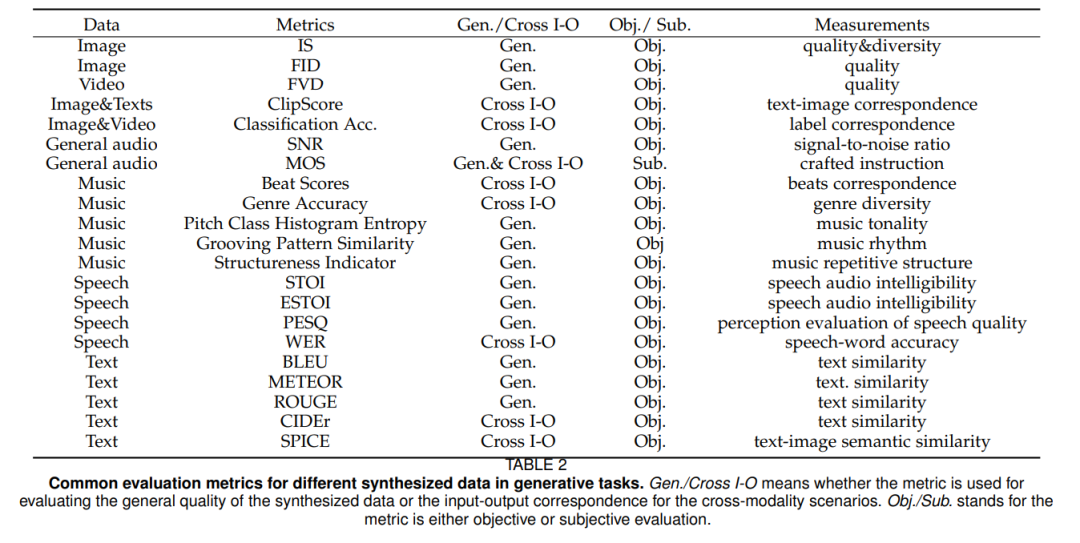
生成任务中不同的合成数据的共同评价指标