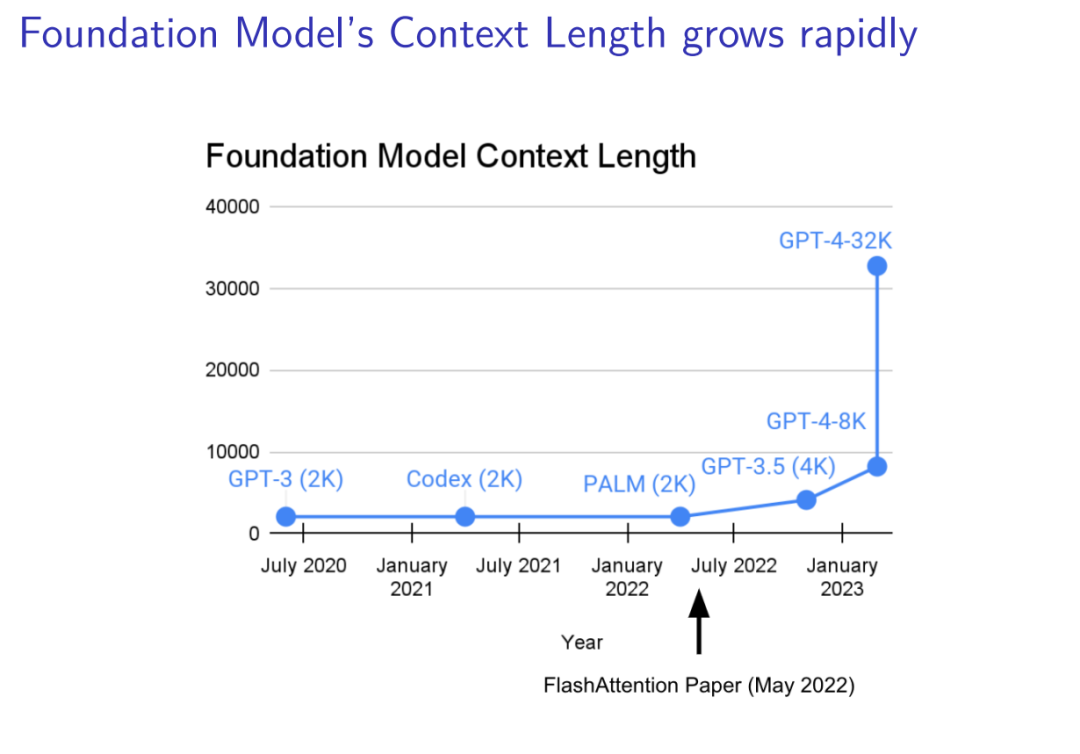
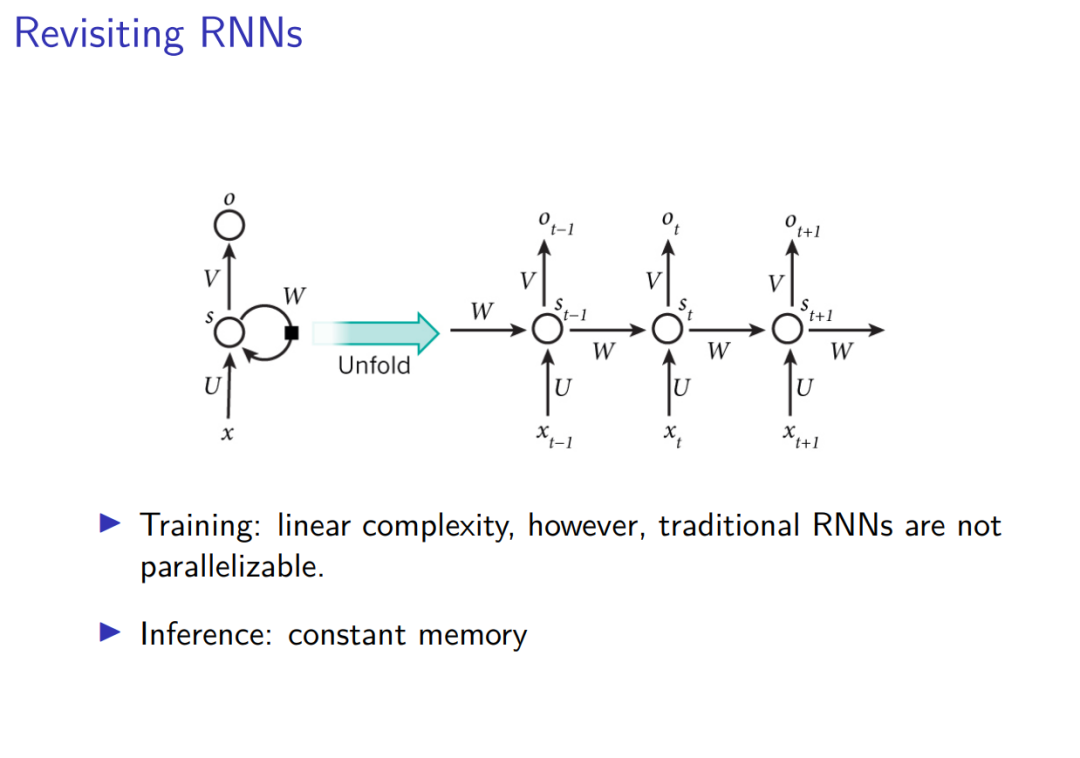
本报告探讨了现代线性循环模型在长序列建模中的表现,并提出了更高效的循环更新规则。随着基础模型的上下文长度迅速增长,传统的Transformer模型在处理长序列时面临训练和推理的复杂性挑战。Transformer的训练时间复杂性与序列长度的平方成正比,导致长序列建模成本高昂,而推理时需要存储每个token的键值缓存,导致高内存负担。相比之下,传统的RNN在训练时具有线性复杂性,推理时具有恒定内存需求,但无法并行化训练,限制了其在大规模应用中的效率。 现代线性循环模型通过线性递归实现了并行训练,包括门控线性RNN、状态空间模型和线性注意力模型。Mamba2更类似于线性注意力模型而非状态空间模型。混合线性和Softmax注意力模型在大规模和长上下文任务中表现出色,能够达到GPT-4级别的性能。这些模型通过结合线性注意力和少量Softmax注意力层,实现了高效的训练和推理。
线性注意力通过去除Softmax操作,简化了标准注意力的计算。然而,线性注意力在训练时仍然面临序列长度的二次复杂性,且由于缺乏矩阵乘法操作,GPU利用率较低。为了解决这些问题,提出了分块并行形式,将序列分成多个块,分别计算历史上下文和局部上下文。这种方法在硬件上具有高效性,成为现代线性注意力模型训练的标准。 为了克服线性注意力模型在语言建模中的表现不佳问题,引入了衰减机制。通过引入指数衰减因子或动态衰减项,线性注意力模型能够更好地控制信息的遗忘和记忆,从而提升性能。DeltaNet通过在线回归损失优化了模型的预测能力,增强了键值关联记忆。Gated DeltaNet结合了DeltaNet的Delta更新规则和Mamba2的门控更新规则,进一步提升了模型的性能。 在多个基准测试中,DeltaNet和Gated DeltaNet在上下文关联记忆任务中表现出色,但在实际语言建模任务中仍略逊于Mamba2。Gated DeltaNet在长上下文理解和零样本推理任务中表现优异,尤其在处理复杂模式时表现出更强的记忆能力。 未来的研究方向包括超越在线线性回归目标,探索非线性回归损失,以及结合梯度优化技术,进一步提升模型的表达能力和硬件效率。现代线性循环模型通过在线学习视角,结合衰减机制和硬件高效的训练方法,展现了在处理长序列任务中的潜力。未来的研究将继续探索如何更好地结合上下文元学习和RNN架构,以进一步提升模型的性能。