
GraphRAG研究进展
一、简介
近年来,检索增强生成(Retrieval-Augmented Generation, RAG)在解决大语言模型(LLMs)所面临的挑战方面取得了显著成功,而无需对模型进行重新训练。通过引用外部知识库,RAG能够改进LLM的输出,有效缓解了“幻觉”、缺乏领域特定知识以及信息过时等问题。然而,不同实体之间复杂的关系结构为RAG系统带来了挑战。为此,GraphRAG利用实体之间的结构化信息,使得检索更加精确和全面,捕捉到关系知识并促进了更准确、具备上下文感知的回答。鉴于GraphRAG的创新性和潜力,系统性地回顾当前技术显得尤为重要。GraphRAG 是一种将图神经网络(GNN)与大语言模型(LLM)相结合的推理框架,专为处理复杂的多跳推理场景设计。它通过 GNN 在知识图谱中建模节点及其关系,实现深层次的图结构推理,同时利用 LLM 处理自然语言查询,提升系统的语言理解和生成能力。GraphRAG 能在多层次节点间进行信息传递和推理,从而解决复杂的问题,特别适合知识图谱问答系统、推荐系统等需要结合结构化数据与非结构化语言处理的场景。GraphRAG的工作流程,包括图索引(Graph-Based Indexing)、图引导检索(Graph-Guided Retrieval)和图增强生成(Graph-Enhanced Generation)。随后,本文概述了每个阶段的核心技术和应用领域。最后,探讨了未来的研究方向,以激发更多的研究兴趣并推动该领域的进一步进展。
二、背景
随着LLMs如 GPT-4 和 LLaMA 的出现,自然语言处理(NLP)领域取得了显著进展。这些模型基于庞大的数据集进行训练,展示了卓越的语言理解和文本生成能力。然而,尽管 LLM 在处理自然语言任务时表现优异,但它们在处理领域特定知识、实时更新的信息以及复杂关系推理任务时仍存在显著的局限性。为解决这些问题,检索增强生成(RAG)被引入,通过结合外部知识库在生成过程中检索相关信息,增强了 LLM 的知识覆盖和准确性。然而,RAG 也面临一些挑战。特别是在需要理解实体间关系的任务中表现欠佳。为应对这些局限性,GraphRAG 作为一种创新的解决方案被提出。GraphRAG 结合了图神经网络(GNN)和 RAG 的优势,通过从预构建的图数据库中检索图元素(如节点、路径、子图等)来增强检索过程。这种方法能够捕捉到文本之间的复杂关系,使得模型在处理多跳推理、复杂实体查询时更加准确。
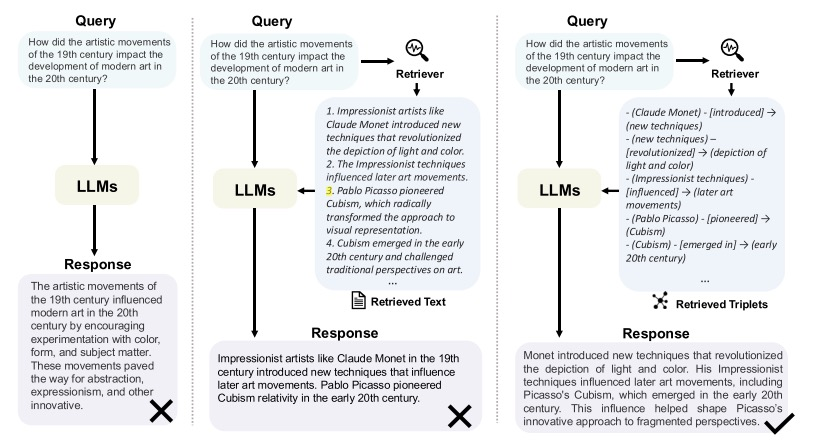
GraphRAG示例
三、相关技术
3.1 文本属性图
在 GraphRAG 中使用的图数据可以统一表示为文本属性图(Text-Attributed Graphs,简称 TAGs), 其中节点和边具有文本属性。形式上,文本属性图可以表示为, 其中 是节点的集合, 是边的集合, 是邻接矩阵。此外, 和 分别表示节点和边的文本属性。TAGs 的一种典型形式是知识图谱(Knowledge Graphs, KGs), 其中节点表示实体,边表示实体之间的关系,文本属性则是实体和关系的名称。
3.2 图神经网络
图神经网络(Graph Neural Networks,GNNs)是一种用于建模图数据的深度学习框架。经典的 GNNs,如图卷积网络(GCN)、图注意力网络(GAT)和 GraphSAGE,采用消息传递的方式来获取节点表示。
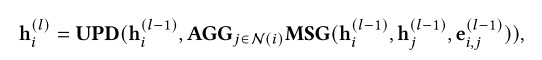
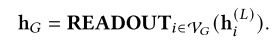
在 GraphRAG 中,GNNs 可以用于检索阶段获取图数据的表示,并用于建模检索到的图结构。
四、GraphRAG概述
GraphRAG是一个框架,它利用外部结构化知识图来提高对LM的上下文理解,并生成更明智的响应。GraphRAG的目标是从数据库中检索最相关的知识,从而增强下游任务的答案。GraphRAG的整个过程分解为三个主要阶段:基于图的索引、图引导的检索和图增强的生成。GraphRAG的整体工作流程下图所示,下面将详细介绍各个阶段。
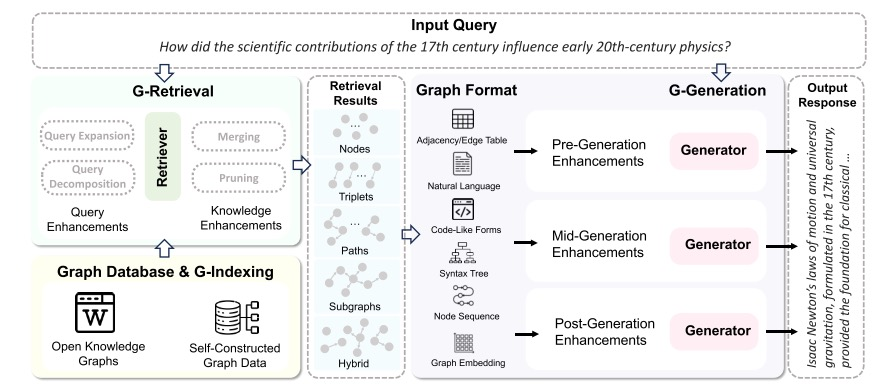
GraphRAG整体工作流程
4.1 G-Indexing
基于图形的索引:基于图的索引构成了GraphRAG的初始阶段,旨在识别或构建与下游任务对齐的图数据库G并在其上建立索引。图数据库可以源自公共知识图,图数据,或者基于专有数据源构建,例如文本或其他形式的数据。索引过程通常包括映射节点和边属性,在连接的节点之间建立指针,以及组织数据以支持快速遍历和检索操作。索引决定了后续检索阶段的粒度,对提高查询效率起着至关重要的作用。
4.2 G-Retrieval
基于图形的检索:在基于图的索引之后,图引导的检索阶段集中于响应于用户查询或输入从图数据库中提取相关信息。具体地,给定以自然语言表达的用户查询,检索阶段旨在提取最相关的元素(例如,𝑞实体、三元组、路径、子图),其可以被公式化为:
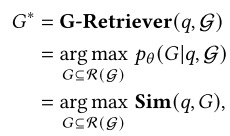
其中,最优检索图元素是最优检索图元素,Sim(·,·)是测量用户查询与图数据之间的语义相似性的函数。R(·)表示考虑到效率而缩小子图的搜索范围的函数。然而,检索图数据提出了两个重大挑战:(1)爆炸性候选子图:随着图大小的增加,候选子图的数量呈指数级增长(2)相似性度量不足:准确度量文本查询和图形数据之间的相似性需要开发能够理解文本和结构信息的算法。图引导检索的一般架构如下图所示。 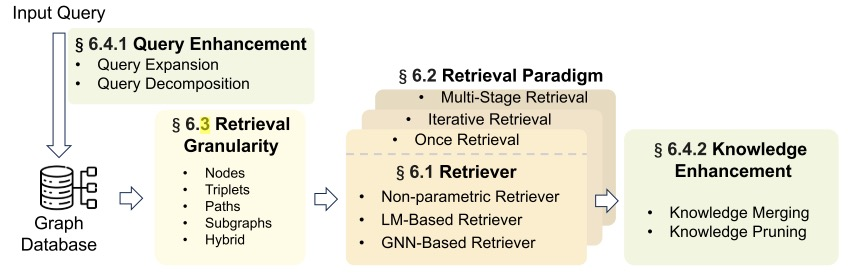
4.3 G-Generation
基于图增强生成:图形增强生成阶段涉及基于检索到的图形数据合成有意义的输出或响应。这可以包括回答用户查询、生成报告等。在这个阶段,生成器将查询、检索到的图形元素和可选提示作为输入来生成响应,该响应可以表示为:
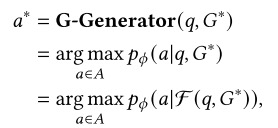
其中F(·,·)是将图形数据转换为生成器可以处理的形式的函数。
五、GraphRAG应用领域
GraphRAG 技术在多个领域得到了广泛的应用,帮助解决复杂的数据和推理任务。
- 电子商务:GraphRAG 在电子商务中被用于通过个性化推荐和智能客户服务来提升用户购物体验和增加销售量。通过分析用户与产品的历史交互形成的图数据,GraphRAG 能够提取用户行为模式和偏好信息,进而改善推荐系统和客户服务问答系统的表现。
- 生物医学:GraphRAG 技术在生物医学问答系统中得到了广泛应用,帮助改进医疗决策。研究人员构建了与特定疾病和药物相关的知识图谱,并使用开源知识图进行检索,优化检索和生成过程以提升问答系统的质量。
- 学术领域:在学术研究中,GraphRAG 被用于结构化学术论文、作者、机构之间的关系,帮助学者进行学术探索,如预测潜在的合作伙伴或识别研究领域的发展趋势。
- 文学领域:GraphRAG 还被用于构建文学知识图谱,将图书、作者、出版商和系列等节点相互关联,从而为智能图书馆等应用提供支持。
- 法律领域:在法律领域,GraphRAG 被用于处理案例之间的引用关系,帮助律师和法律研究人员分析案件和提供法律咨询,通过图结构化判决意见、案件群组等信息进行推理和分析。
- 其他领域:GraphRAG 还在情报报告生成和专利短语相似度检测等其他场景中得到了应用,通过构建事件图或专利图来辅助生成报告或判断短语相似度。通过这些应用,GraphRAG 展示了其在多个领域中捕捉复杂关系、增强推理能力的潜力。
六、未来展望
GraphRAG 技术虽然取得了显著进展,但仍面临许多挑战。以下是未来研究的几个重要方向:
- 动态和自适应图:目前大多数 GraphRAG 方法基于静态数据库,但随着时间推移,新实体和关系不断涌现。如何快速更新这些信息并进行实时集成是一个关键问题。开发有效的动态更新方法将提升 GraphRAG 系统的准确性和相关性。
- 多模态信息集成:现有知识图谱主要包含文本信息,缺乏图像、音频和视频等多模态数据的整合。然而,多模态数据的引入能够显著提高知识库的质量和深度。如何高效管理和维护这些庞大且复杂的数据是未来的一大挑战。
- 可扩展的高效检索机制:工业场景中的知识图谱可能包含数百万甚至数十亿个实体,但目前的方法多用于小规模知识图。针对大规模知识图谱的高效检索算法和基础设施建设是一个重要的研究方向。
- 与图基础模型的结合:最近,图基础模型在解决多种图任务方面取得了显著成功,将这些模型整合到 GraphRAG 框架中可以提高系统处理图结构信息的效率,从而增强整体性能。
- 无损压缩检索上下文:GraphRAG 需要将检索到的图结构信息转化为 LLM 能理解的序列,但长上下文会导致计算开销增加。无损压缩技术可以减少冗余信息,压缩长句以加速推理,然而设计有效的无损压缩方法依然是一个挑战。这些研究方向为 GraphRAG 技术的发展提供了广阔的前景。
七、参考文献
[1] Muhammad Arslan and Christophe Cruz. 2024. Business-RAG: Information Extraction for Business Insights. ICSBT 2024 (2024), 88. [2] Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary G. Ives. 2007. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web, 6th International Semantic Web Conference, 2nd Asian SemanticWeb Conference, ISWC 2007 + ASWC 2007, Busan, Korea, November 11-15, 2007 (Lecture Notes in Computer Science, Vol. 4825). 722–735. [3] Jinheon Baek, Alham Fikri Aji, Jens Lehmann, and Sung Ju Hwang. 2023. Direct Fact Retrieval from Knowledge Graphs without Entity Linking. In Proceedings ofthe 61st Annual Meeting ofthe Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023. 10038–10055. [4] Jinheon Baek, Alham Fikri Aji, and Amir Saffari. 2023. Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering. arXiv:2306.04136 [cs.CL] https://arxiv.org/abs/2306.04136 [5] Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic Parsing on Freebase from Question- Answer Pairs. In Proceedings ofthe 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, 18-21 October 2013, Grand Hyatt Seattle, Seattle, Washington, USA, A meeting ofSIGDAT, a Special Interest Group ofthe ACL. 1533–1544. [6] Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. PIQA: Reasoning about Physical Commonsense in Natural Language. In The Thirty-Fourth AAAIConference on Artificial Intelligence, AAAI2020, The Thirty-Second Innovative Applications ofArtificial Intelligence Conference, IAAI 2020, The Tenth AAAISymposium on Educational Advances in Artificial Intelligence, EAAI2020, NewYork, NY, USA, February 7-12, 2020. 7432–7439.