

论文标题:MeaeQ: Mount Model Extraction Attacks with Efficient Queries 论文作者:戴程威、吕民轩、李鲲、周薇 收录会议:EMNLP 2023 Main Conference 论文链接:https://arxiv.org/pdf/2310.14047.pdf 代码链接:https://github.com/C-W-D/MeaeQ
一、引言 模型窃取攻击是指攻击者在无法访问受害者模型的结构、参数、训练数据的场景下,通过反复调用开放的API来窃取受害者模型。最近的研究主要关注有限的API查询预算设置,并通过随机策略或者基于主动学习的策略在公开可用的未标注数据源上采样Query(查询)。然而,这些方法通常会导致所采样的Query缺乏任务相关性和数据多样性,具体表现为采样的Query呈现出严重倾斜的类别标签。
为了解决这些问题,我们提出了一种通过高效查询来执行模型窃取攻击的方法MeaeQ(Model extraction with efficient Queries),利用一个零样本序列推理分类器和一种基于聚类的归约技术来采样任务相关且多样的数据作为最终用于攻击的Query。
二、方法 本节介绍所提出的方法,如图1所示MeaeQ包含了三大模块,分别是任务相关性过滤器、基于聚类的数据归约、模型提取攻击。
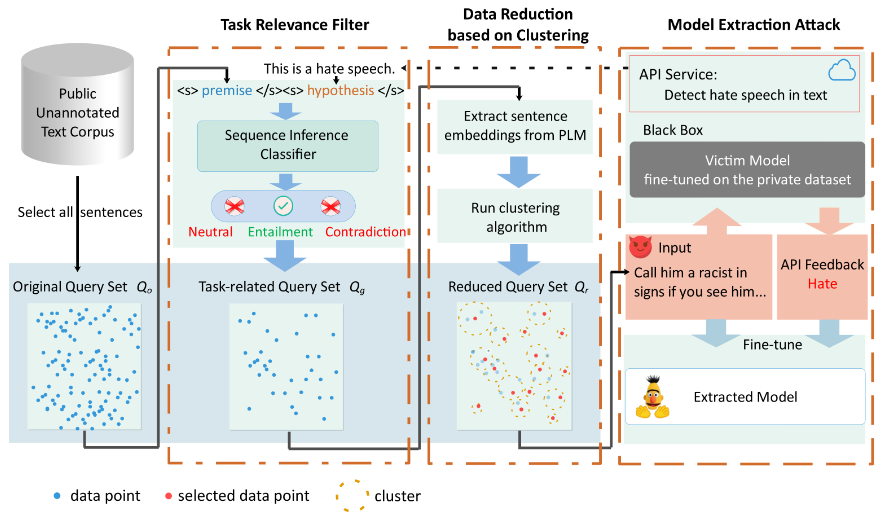
图1 MeaeQ的整体框架
问题定义 定义 表示受害者模型。攻击者需要从公开的文本语料库中采样Query用于查询API获取受害者模型的输出,从而创建了一个攻击者的数据集
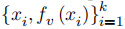
。 定义
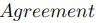
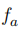
的功能相似性,其计算公式如下:
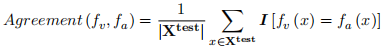
其中,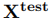
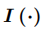

其中,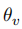

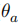
的所有参数。 任务相关性过滤器 我们首先从公开的文本语料库中以句子为单位采样所有文本数据,形成初始Query集
。然后,我们提出了任务相关性过滤器(Task Relevance Filter, TRF)从
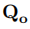
。TRF主要包含了一个序列推理分类器
和过滤机制。
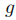
可以推理前提与假设的关系,包括中立(Neutral)、蕴含(Entailment)、矛盾(Contradiction)。基于此,为了过滤与任务相关的数据,我们可以使用
来计算文本语料库中所有的文本与目标任务的相关度。因此,我们需要先根据目标任务API提供的内容信息去手工设计提示
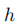
的其中一个输入即假设,而将文本序列
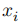
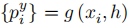
其中,
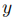
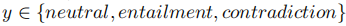
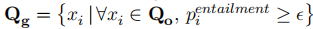

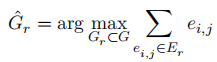
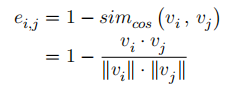
然而,这是一个NP难问题。因此,我们设计了一种基于聚类的数据归约方法(Data Reduction based on Clustering, DRC)来选择样本,具体步骤如下: 步骤1:在整个 上执行聚类算法,得到簇集合
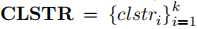
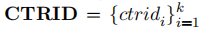
。 此方法背后的动机是聚类算法可以生成k个具有大类间距离与小类内距离的簇。最理想的情况是选择的样本刚好是位于各个簇质心的样本。但这并不现实,因此我们选择离质心最近的样本。 最后,攻击者使用
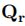
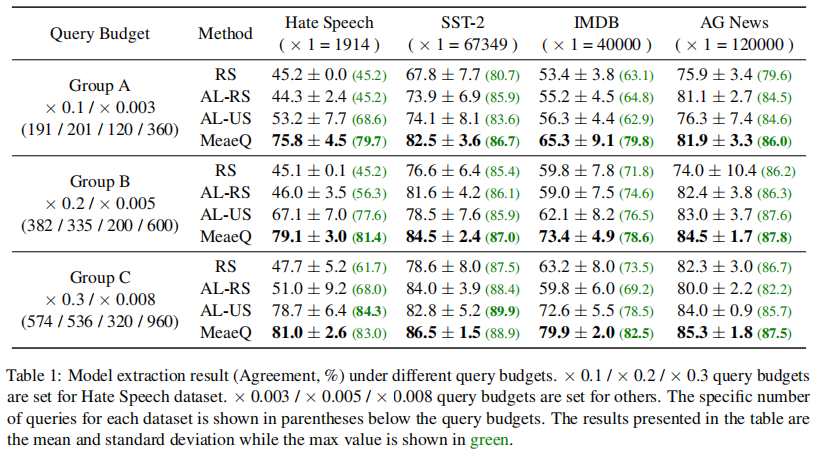
表1 不同Query预算下模型提取攻击的实验结果(Agreement,%) 此外,为了充分探索MeaeQ的有效性,我们进行了更多Query预算设置的实验。实验结果如图2所示。图2中第一行汇报的是在目标任务准确率上的结果,第二行汇报的是功能一致性上的结果。我们可以看到MeaeQ在几乎所有的设置下都超越了基线方法。值得注意的是,对于SST-2和IMDB任务,MeaeQ仅用了×0.008的Query预算就达到与基线方法用了×0.02的Query预算相同甚至更好的性能。
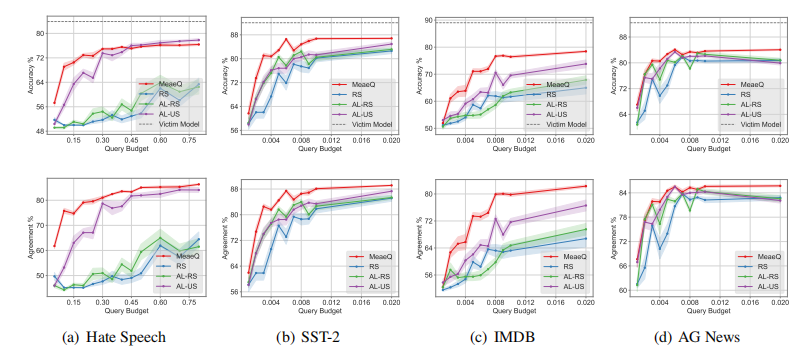
图2 在更多Query预算设置下的实验结果 我们探索了不同模型结构对MeaeQ方法鲁棒性的影响。我们分别为攻击者模型和受害者模型设置了三种模型架构,包括bert-base、roberta-base、xlnet-base。实验在Query预算为×0.5下进行,任务为Hate Speech(仇恨言论检测)。实验结果如图3所示,图中横轴代表受害者模型结构,纵轴代表攻击者模型结构。从图中,我们可以很清楚地看到MeaeQ在不同模型结构下都优于基线方法。此外,我们也注意到基线方法仅在匹配的模型结构上表现出较好的性能。相反,MeaeQ在设置的所有模型结构下均表现出优异的性能,这表明MeaeQ是一种与模型结构无关的方法,具有普适性以及对模型结构的鲁棒性。
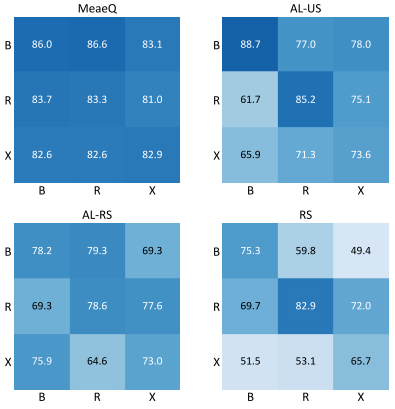
图3 不同模型结构的影响 为了更好地理解MeaeQ中的两个关键模块,我们对MeaeQ进行了消融,用w/o TRF和w/o DRC分别表示MeaeQ的两种去除对应模块的变体。实验结果如图4所示。本实验在SST-2上进行。

图4 消融实验 从图4中,我们可以看到MeaeQ在低Query预算下(例如×0.003 / ×0.005)显著优于两种变体(更高的Agreement),并且表现出更强的稳定性(更短的误差线)。本实验结果强调了TRF和DRC的重要性。 我们使用ChatGPT在零样本的设置下作为仇恨言论检测的分类模型,并额外使用了GPT-2作为攻击者模型架构,以探索MeaeQ在自回归语言模型窃取上的效果。实验结果如表3所示。

表2 指令模板
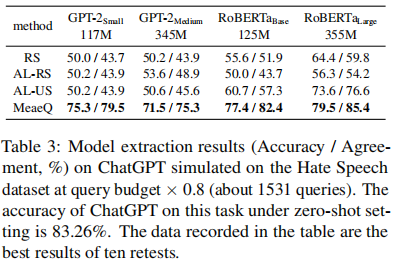
表3 对在Hate Speech任务上以ChatGPT为底座的受害者模型进行提取攻击的实验结果
从表中我们可以看到,即使在自回归语言模型设置下,MeaeQ仍然优于基线方法。例如,gpt2-small达到了79.5%的功能一致性以及75.3%的测试准确率(达到受害者模型测试准确率的90.4%)。 四、分析 我们探索了不同任务相关程度的语料库对模型窃取的影响。我们模拟的受害者模型在IMDB数据集上训练。不同任务相关度的语料库包括WikiText-103(最原始的)、SST-2的训练集(与目标任务均属于电影情感分类领域)、IMDB的训练集(与目标任务同域)。实验结果如表4所示。我们观察到,语料库所在领域越是接近目标任务的领域,模型窃取的功能一致性越高。MeaeQ中的TRF正是源于这一观察。TRF旨在从公开无标注的语料库中过滤文本来拉近与目标任务数据的分布。
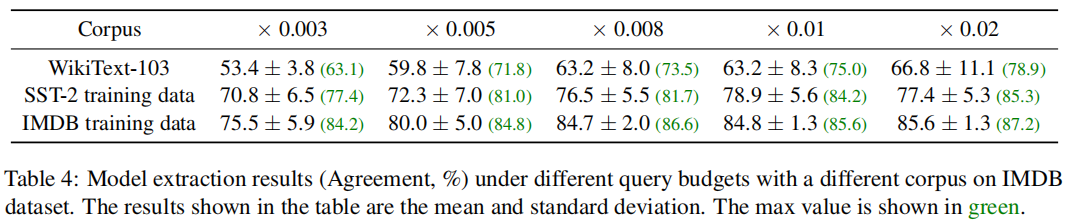
表4 不同语料库对模型提取结果的影响(Agreement,%) 我们使用t-SNE技术对数据归约进行了可视化,如图5所示。我们可以看到DRC采样的样本在整个数据域中广泛分布,而RS(Random Sampling)采样的样本出现了一部分重叠。这也说明了DRC采样是基于文本信息的,并且有效降低了冗余。
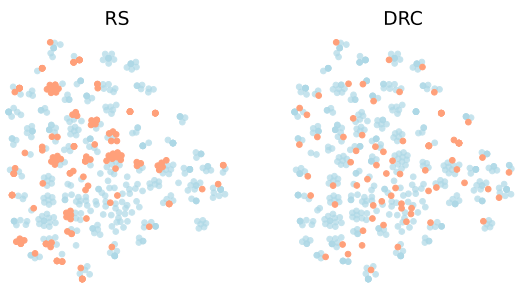
图5 DRC采样与RS采样数据分布可视化图 我们对MeaeQ和RS在Hate Speech任务上采样的样本分别进行了高频词统计,结果如图6所示。我们可以看到MeaeQ采样的样本包含许多与仇恨言论相关的词汇,例如“hate”、“antisemitic”、“nazi”等,这些词汇在RS采样的样本中几乎看不到。这说明了MeaeQ能够有效过滤得到任务相关的数据并且增加了数据多样性。
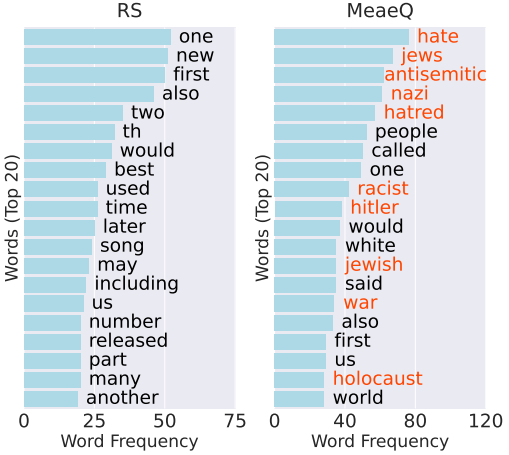
图6 前20个高频词结果 此外,我们在表5中给出了完整的样例,并高亮了与任务相关的词汇。我们可以看到MeaeQ样本的内容风格是与目标任务对齐的。对于Hate Speech,样本中倾向于包含消极或者仇恨情绪的词汇;对于SST-2 / IMDB,样本中包含一些积极或者消极的影评;对于AG News,样本中包含一些新闻的关键要素,例如时间、人物等。

表5 在四个任务下RS和MeaeQ采样的Query示例 五、总结 本文提出了一个简单但有效的模型窃取攻击方法MeaeQ。MeaeQ首先利用一个零样本的序列推理分类器,结合目标任务的API内容信息来过滤任务相关度高的数据。其次,利用基于聚类的数据归约技术从过滤的数据中获取最具代表性的数据作为最终用于攻击的Query。在4个基准数据集上的实验表明,我们的方法能够在受限的Query预算下,达到优于基线方法的性能。