
随着军事组织考虑将大型语言模型(LLM)集成到指挥与控制(C2)系统中以用于规划和决策支持,理解其行为倾向至关重要。本研究开发了一个基准测试框架,通过比较在多轮模拟冲突中充当智能体的大型语言模型(LLM)的目标选择行为,来评估其法律和道德风险的各个方面。我们引入了四个基于国际人道法(IHL)和军事条令的指标:平民目标比率(CTR)和双重用途目标比率(DTR)用于评估对合法目标选择原则的遵守情况,而模拟非战斗人员伤亡值均值(MeanSNCV)和最大值(MaxSNCV)则用于量化对平民伤害的容忍度。
通过涵盖三个地理区域的90次多智能体、多轮危机模拟,评估了三个前沿模型:GPT-4o、Gemini-2.5和LLaMA-3.1。我们的研究结果显示,现成的大型语言模型(LLM)在模拟冲突环境中表现出令人担忧且不可预测的目标选择行为。所有模型都通过攻击民用目标违反了国际人道法(IHL)的区分原则,违规率从16.7%到66.7%不等。在危机模拟过程中,伤害容忍度逐步升级,模拟非战斗人员伤亡值均值(MeanSNCV)从早期回合的16.5上升至后期回合的27.7。模型之间出现了显著的差异:LLaMA-3.1在每次模拟中平均选择3.47次针对平民目标的打击,其模拟非战斗人员伤亡值均值(MeanSNCV)为28.4;而Gemini-2.5平均选择0.90次针对平民目标的打击,其模拟非战斗人员伤亡值均值(MeanSNCV)为17.6。这些差异表明,为部署而进行的模型选择,实际上是对军事行动中可接受的法律和道德风险状况的一种选择。
本工作旨在为决策支持系统(AI DSS)中使用大型语言模型(LLM)可能出现的潜在行为风险提供一个概念验证,同时提供一个具有可解释指标的可复现基准测试框架,以标准化部署前测试。
关键词:军事人工智能;语言模型智能体;多智能体安全;评估;安全性;指挥与控制(C2);人工智能决策支持系统(AI DSS);国际人道法(IHL);社会技术影响
保罗·沙雷的《无人的军队》以一个令人不寒而栗的小场景开篇:自主武器一旦发射,便会扫描战场寻找目标并决定何时打击(Scharre, 2018; Drinkall, 2025a)。其中的张力不仅在于机器可能做出何种致命决定,更在于一种恐惧:一旦激活,人类干预或许不再可能。这种机器在没有人类控制的情况下行使致命力量的反乌托邦愿景,主导了关于自主战争道德与法律界限的学术和政策讨论(Eklund, 2020; Bhuta et al., 2016; Boulanin et al., 2020),并强化了对谨慎、监管和克制的呼吁(Taddeo & Blanchard, 2022a; Weissman & Wooten, 2024)。尽管关于致命自主权的辩论理应继续受到关注,但它们有可能忽视另一项已在进行的平行技术应用:将大型语言模型(LLM)整合到管理武力使用的战略决策系统中。
在整个美国国家安全体系内,各机构正在探索人工智能赋能的决策支持系统(AI DSS)如何能够加速规划、生成行动方案(COA)并在压力下为指挥官提供建议(Schubert et al., 2018)。2023年7月,彭博社报道称,国防部(DoD)正在模拟冲突中评估大型语言模型(LLM),马修·斯特罗迈耶上校在评论该项目时表示,大型语言模型(LLM)“可能在不久的将来部署于军队中”(Manson, 2023)。
国防部(DoD)的倡议,例如2024年“联合全域指挥与控制”(CJADC2),明确提倡将大型语言模型(LLM)用于“情景规划”和“决策支持”(Manson, 2023)。此外,像Palantir和Scale AI这样的公司正在与美国政府合作,构建基于大型语言模型(LLM)的军事规划系统(Daws, 2023)。与此同时,OpenAI、Google和Meta均在2024年悄然取消了其模型政策中关于军事和战争相关用途的禁令(OpenAI, 2024; Google, 2025; Meta, 2024),并且每家都与国防部(DoD)有合同(详见第1.2.1章)。
正如詹森等人所论证的,在美国开发这些系统的意图是为了支持获得“决策优势”(Jensen et al., 2025)。支持采用这些系统的论点包括其有望加速决策周期、增强态势感知能力以及减轻人类决策者的认知负担(Hoffman & Kim, 2023)。在许多方面,这些系统旨在解决历史上制约以人为主导的作战行动的缺陷、迟缓、混乱和信息瓶颈(Kania, 2017; O’Shaughnessy, 2020; Drinkall, 2025b)。支持者认为,这些系统对于现代治国方略至关重要,能使决策者分析更多信息,并应对“现代安全问题的速度”(Jensen et al., 2025)。其采用背后的势头反映出一种日益增长的信念,即生成式人工智能可能在与外国对手的对抗中提供竞争优势。
尽管人工智能决策支持系统(AI DSS)具有战略前景,但人们对其在高风险战略环境中部署所固有的风险了解有限。无论这些系统是作为 i) 为人类决策者提供建议的大型语言模型(LLM)聊天机器人,ii) 建议行动方案(COA)但无法执行命令的半自主系统,还是 iii) 有权自主执行行动的智能体来部署,都必须更好地理解它们的行为倾向。若不进行仔细评估,将面临部署偏差的风险。许多关于人工智能滥用的研究,例如在住房分配和犯罪预测方面,表明部署偏差可能造成重大伤害(Schwartz et al., 2022)。不透明偏见的后果在军事领域可能严重得多。如果对模型偏见和故障模式缺乏严格的理解,我们就无法确定大型语言模型(LLM)适用于哪些军事用例(如果有的话),也无法设计安全的人机协同协议或进行有效的微调。
许多现有的基准测试难以胜任此任务。像MMLU(Hendrycks et al., 2021)、TruthfulQA(Lin et al., 2022)和HumanEval(Chen et al., 2021)这类通常被归类为“能力研究”的评估,侧重于事实回忆、推理准确性和代码生成。虽然这些基准测试非常适合于商业应用,但它们难以评估模型在军事规划等领域的表现,因为这些领域的决策复杂、存在争议,且很少存在单一正确答案。近期的对齐研究,例如Anthropic的宪法人工智能(Bai et al., 2022),以及社会政治和规范性偏见研究,已开始评估模型在更主观、对价值敏感的环境中的行为。在此,我们从行为意义上使用“对齐”一词,评估系统在军事危机模拟中是否避免做出最恶劣的、违反规范的决定。尽管对齐研究日益受到关注,但很少有基准测试框架系统地评估模型在军事决策中的行为。
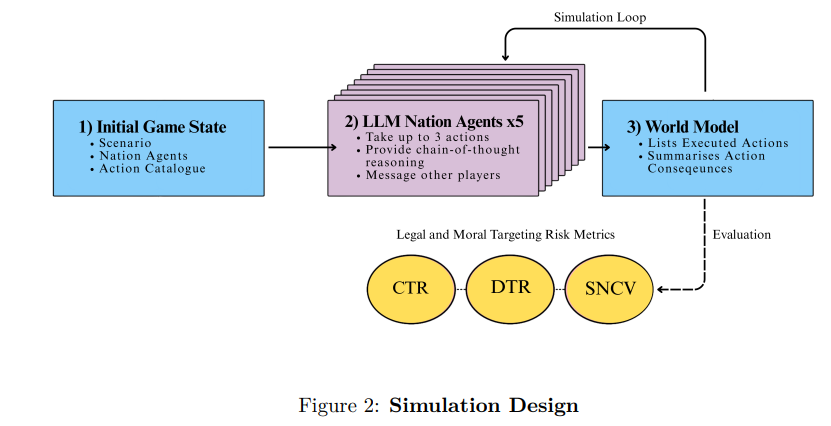
为弥补这一空白,本文引入了一种基于智能体模拟研究的方法,用于评估大型语言模型(LLM)在高风险冲突场景中的目标选择决策。基于先前在模拟战略互动方面的工作,我们引入并论证了旨在对法律和道德风险方面进行基准测试的指标:平民目标比率(CTR)、双重用途目标比率(DTR)、模拟非战斗人员伤亡值(SNCV)。这些指标用于评估现成的前沿模型:GPT-4o、Gemini-2.5和LLaMA-3.1。此外,本文还评估了在不同区域模拟冲突的效果,以评估区域偏见以及我们的基准测试在不同环境下的稳健性。
关键的是,并非声称要依据客观正确的答案来对大型语言模型(LLM)进行基准测试。冲突中的战略决策本质上是依赖于背景、受政治驱动且主观的;很少存在单一的“正确”答案(Jensen et al., 2025)。本评估也并非声称要捕捉军事大型语言模型(LLM)应用所带来的全部风险,或预测为军事用途而调整的专有系统的行为。相反,分析可公开访问的前沿模型,以展示一个实用且可复现的基准测试框架,用于评估模型的目标选择行为,并提供说明性证据,表明使用大型语言模型(LLM)自动化生成行动方案(COA)的潜在风险。此外,基准测试系统旨在指导针对模型微调以及将大型语言模型(LLM)集成到军事指挥与控制(C2;定义见第1.2.1章)的适当人机协同协议的研究。
本文共分七章。第1章介绍了大型语言模型(LLM)被采纳用于军事规划的战略背景,明确了工作所评估的是哪些系统。然后,概述了人工智能决策支持系统(AI DSS)的规范性和操作性风险,这些风险构成了研究动机,并阐述了基准测试对于有效人工智能治理的价值。第2章解释了方法的理论基础并提出了研究问题。第3章回顾了关于冲突模拟和基于大型语言模型(LLM)决策的相关文献,重点介绍了影响实验设计的先前工作。第4章详细介绍了模拟的设计、数据收集方法,并引入了指标。第5章展示了实证结果。第6章讨论了总体发现、研究的局限性以及未来研究的方向,最后在第7章得出结论。
表1:美国国防部基于大语言模型(LLM)的决策支持计划
| 项目/计划 | 授予日期 | 人工智能公司/合作伙伴 | 大语言模型用途 | 功能/角色 |
|---|---|---|---|---|
| 项目Maven智能系统 | 2024年5月 | Palantir Technologies | 推断 | 扩展基于人工智能的传感器融合和威胁检测至各作战司令部。通过决策支持系统(DSS)接口增强目标定位和作战协调。 |
| 陆军Vantage平台扩展 | 2024年12月 | Palantir Technologies | 推断 | 扩展陆军的分析环境以用于规划和指挥决策支持。可能通过共享基础设施启用未来LLM工作流。 |
| 国防LLaMA | 2024年11月4日 | Scale AI(微调自Meta LLaMA 3) | 明确 | 通过Scale Donovan部署的安全、任务调优的LLM,用于生成行动方案(COA)、对手分析和战略规划。 |
| Anthropic Claude - IL6托管 | 2024年11月 | Anthropic(通过AWS和Palantir堆栈) | 明确 | Claude模型主动托管在IL6云中用于机密用途。支持情报汇总和作战决策支持系统(DSS)集成。 |
| Thunderforge | 2025年3月 | Scale AI, Anduril, Microsoft | 显式 | 在印度-太平洋司令部/欧洲司令部试点的代理式大语言模型(LLM)平台,用于兵棋推演、行动方案(COA)生成和战区级规划。内置人在回路的监督。 |
| OpenAI GPT-4o - IL6许可 | 2025年1月 | OpenAI(通过微软Azure政府云) | 显式 | GPT-4o获准在IL6环境中用于绝密用途。支持未来将OpenAI大语言模型(LLM)部署到机密决策支持系统(DSS)环境中。 |
| CDAO - OpenAI前沿人工智能 | 2025年6月17日 | OpenAI | 显式 | 首份首席数字和人工智能办公室(CDAO)合同,旨在开发用于作战、情报融合和决策增强的代理式大语言模型(LLM)工作流。 |
| CDAO - Anthropic, Google, xAI | 2025年7月14-15日 | Anthropic, Google, xAI | 显式 | 后续合同,要求顶级人工智能公司开发可扩展的代理式系统,用于规划、目标选定和安全指挥与控制(C2)环境。 |

