

尽管在大型语言模型(LLMs)中加速文本生成对于高效产生内容至关重要,但这一过程的顺序性往往导致高推理延迟,从而对实时应用构成挑战。为了解决这些挑战并提高效率,已经提出并开发了各种技术。本文对自回归语言模型中加速生成技术进行了全面的综述,旨在了解最先进的方法及其应用。我们将这些技术分为几个关键领域:投机解码、提前退出机制和非自回归方法。我们讨论了每个类别的基本原理、优点、局限性和最新进展。通过这篇综述,我们希望能够提供对当前LLMs技术领域的见解,并为该自然语言处理关键领域的未来研究方向提供指导。
大语言模型(LLMs)的推理需要大量的计算资源,这归因于多个因素。其中关键因素之一是诸如GPT家族[1]、LLaMA家族[2]、PaLM[3]、OPT[4]和Mistral[5]等模型固有的复杂性,这些模型通常包含数百万甚至数十亿个参数。因此,通过这些模型的众多神经网络层处理输入数据需要大量的计算资源。此外,推理过程计算密集,涉及复杂的操作,如矩阵乘法、非线性激活和跨多个层的注意力机制。此外,LLMs需要大内存分配,因为它们的参数中包含了广泛的数据存储,包括词嵌入和注意力矩阵。此外,自回归解码的性质,即输出令牌基于先前生成的令牌逐步生成,限制了并行化的潜力,特别是对于较长的序列,导致推理速度较慢。最后,LLMs中常用的注意力机制用于捕捉输入数据中的长程依赖关系,这增加了计算复杂性,特别是在计算大输入序列的注意力分数时。综上所述,这些因素使得大语言模型的推理需要大量的计算资源和时间。
为了解决加速大语言模型推理的挑战,已经开发了各种方法。这些技术包括知识蒸馏[6, 7, 8, 9]、量化[10, 11, 12, 13]、稀疏化[14, 15, 16]、修改后的注意力机制[17, 18, 19, 20]。然而,提高大语言模型效率的另一个关键方面在于其解码机制。本综述聚焦于LLMs的这些解码机制,探索和评估其在加速推理的同时保持或提高性能的作用。LLMs中的生成方法指的是这些模型如何基于输入数据生成输出序列。这涉及选择最可能的下一个令牌,以在每一步构建连贯且有意义的序列。然而,加速这一过程面临着若干挑战。一个主要挑战是自回归解码的固有顺序性,即每个令牌基于先前生成的令牌生成。这种顺序依赖性限制了并行化的潜力,特别是在较大模型中导致推理速度较慢。另一个挑战是,在加速生成过程的同时保持生成输出的质量。任何加速技术必须确保生成的序列保持准确、连贯和上下文相关。加速生成应保持模型生成高质量输出的能力,同时所需的计算资源可能非常庞大。
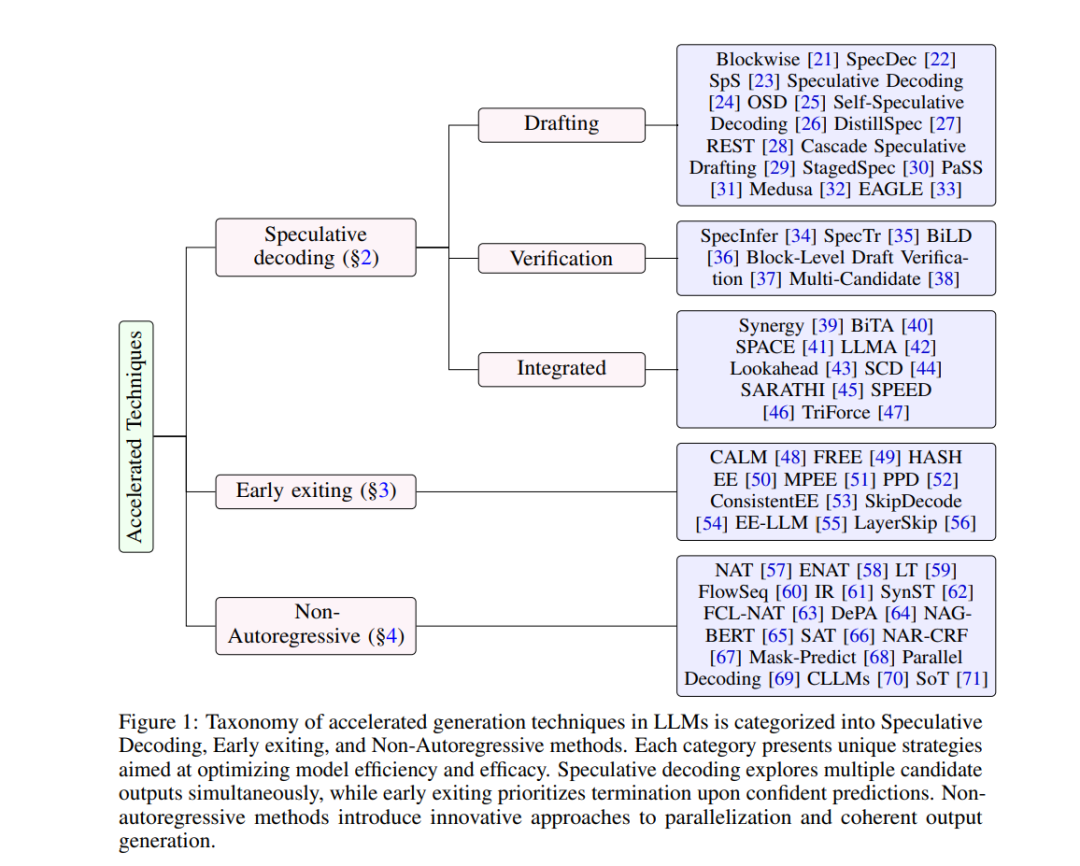
本文全面讨论了各种加速生成技术。第2节讨论了投机解码方法,第3节探讨了提前退出方法,第4节研究了非自回归算法(并行解码)策略。通过详细分类和深入分析,我们提供了对这些大语言模型机制的深刻见解,强调其优点、局限性和未来研究方向。如图1所示,图中展示了不同算法的分类法,本文讨论的加速生成技术根据其基本原理和方法进行了分类和可视化。
投机解码:并行预测与验证
投机解码技术通过并行预测多个令牌并同时验证这些预测,有效地提高了生成速度。这一技术受启发于处理器中的投机执行优化技术,通过并行执行任务来验证其必要性,从而提高并发性。
**Blockwise 解码
Blockwise解码是一种经典的投机解码方法,通过在模型内部并行评分来加速解码过程。该方法首先在训练时在原解码层后增加多输出前馈层,并训练多个辅助“提议”模型以并行预测多个令牌。在推理时,这些模型并行生成下一个k个令牌,并通过基本模型对这些令牌进行评分,确定最长的前缀。如果这个前缀的长度超过1,则可以跳过一个或多个贪心解码循环,从而加快推理速度。
**SpecDec 方法
SpecDec方法通过引入Spec-Drafter和Spec-Verification两个组件,进一步优化了投机解码过程。Spec-Drafter是一个独立的模型,专注于高效准确地生成令牌草稿,而Spec-Verification则允许接受略微偏离贪心解码的令牌,从而提高接受率。实验结果表明,SpecDec方法在保持生成质量的同时,实现了约5倍的速度提升。
**自我投机解码(SSD)
自我投机解码(SSD)是一种不需要辅助草稿模型的新颖推理方案,而是利用单一LLM同时进行草稿生成和验证,从而减少了总内存使用。在草稿阶段,部分中间层被跳过,选择这些层是通过贝叶斯优化完成的。在验证阶段,使用原始LLM对草稿令牌进行一次前向传递评估。虽然跳过额外层可以加速草稿生成,但也可能降低令牌接受率,增加整体推理时间。因此,层选择过程被设计为优化问题,目标是最小化每个令牌的平均推理时间。
提前退出机制:动态计算资源分配
提前退出机制通过动态调整每个输入和生成时间步的计算资源分配,有效地加速了生成过程。这一机制基于对样本难度的观察,动态调整计算资源,避免对简单样本的过度计算,同时确保复杂样本的精确处理。
**CALM 框架
Confident Adaptive Language Modeling(CALM)框架通过动态分配计算资源,根据中间层的置信度得分决定是否提前退出计算,从而加速生成过程。CALM框架探索了三种不同的置信度测量方法:Softmax响应、隐藏状态饱和度和早退出分类器。通过这些方法,模型可以在达到预定义阈值时提前退出,避免全层计算,从而加速推理。
**FREE 方法
Fast and Robust Early-Exiting(FREE)方法通过引入浅层-深层模块和同步并行解码,提高了推理效率。FREE框架将计算路径分为浅层模型和深层模型,在解码时同步处理来自浅层模型的早退出令牌,直到遇到非退出令牌。通过Beta混合模型(BMM),FREE方法能有效捕捉置信度得分与预测一致性的关系,从而动态调整阈值,提高推理效率。
**HASH EE
Hash-based Early Exiting(HASH EE)通过哈希函数为每个令牌分配固定的退出层,避免了传统方法中的内部分类器或额外参数,从而提高了推理效率。HASH EE的优势在于无需监督即可实现令牌级提前退出,适用于多种任务,包括语言理解和生成任务。
非自回归模型:并行生成目标令牌
非自回归模型通过同时或并行生成所有目标令牌,避免了自回归模型中逐令牌生成的顺序性,显著加速了推理过程。非自回归模型在处理诸如机器翻译等任务时,表现出更高的推理效率。
**NAT 模型
非自回归Transformer(NAT)模型在机器翻译任务中首次引入,通过预测每个输入词的繁殖数量来确定目标句子的长度。在训练和推理过程中,NAT模型通过复制源输入来初始化解码器输入,并使用繁殖预测器来决定每个输入词应复制多少次,从而构建目标句子长度。通过这种方法,NAT模型实现了与自回归模型相当的质量,同时推理延迟降低了十倍以上。
**FlowSeq 模型
FlowSeq模型使用生成流技术,通过引入潜变量提高了非自回归生成过程的依赖性建模。FlowSeq通过生成流对先验分布进行编码,引入潜变量,从而在非自回归生成过程中建模输出令牌之间的依赖关系,同时实现高效并行解码。实验结果表明,FlowSeq在保持性能的同时,实现了显著的推理加速。
**依赖感知解码器(DePA)
依赖感知解码器(DePA)通过双向依赖建模和注意力转换过程,提高了非自回归模型对目标依赖的建模效果。DePA模型采用前向-后向依赖建模,在非自回归训练之前进行自回归前向-后向预训练,增强解码器对目标依赖的建模能力。
结论与未来展望
本文全面探讨了各种加速生成技术,包括投机解码、提前退出机制和非自回归方法。通过详细的分类和分析,我们总结了当前技术的优势、局限性和最新进展,为研究人员和工程师在实际应用中提供了宝贵的参考。未来,随着技术的不断发展,这些加速生成方法有望进一步优化,提高LLMs在各种应用场景中的实用性和效率。 通过不断优化和创新,我们期待LLMs能够在更广泛的领域中展现其强大的潜力,实现实时高效的文本生成。