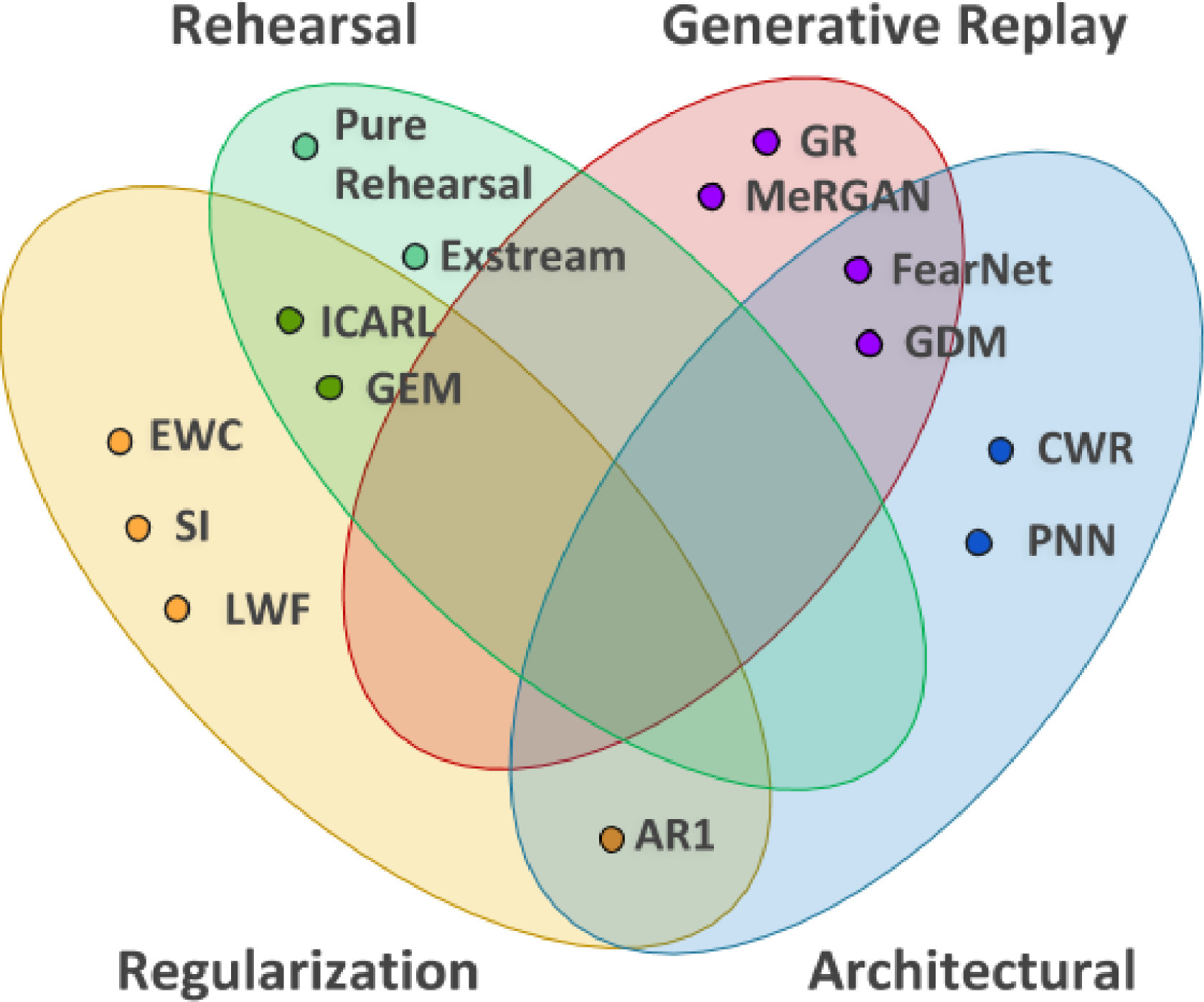
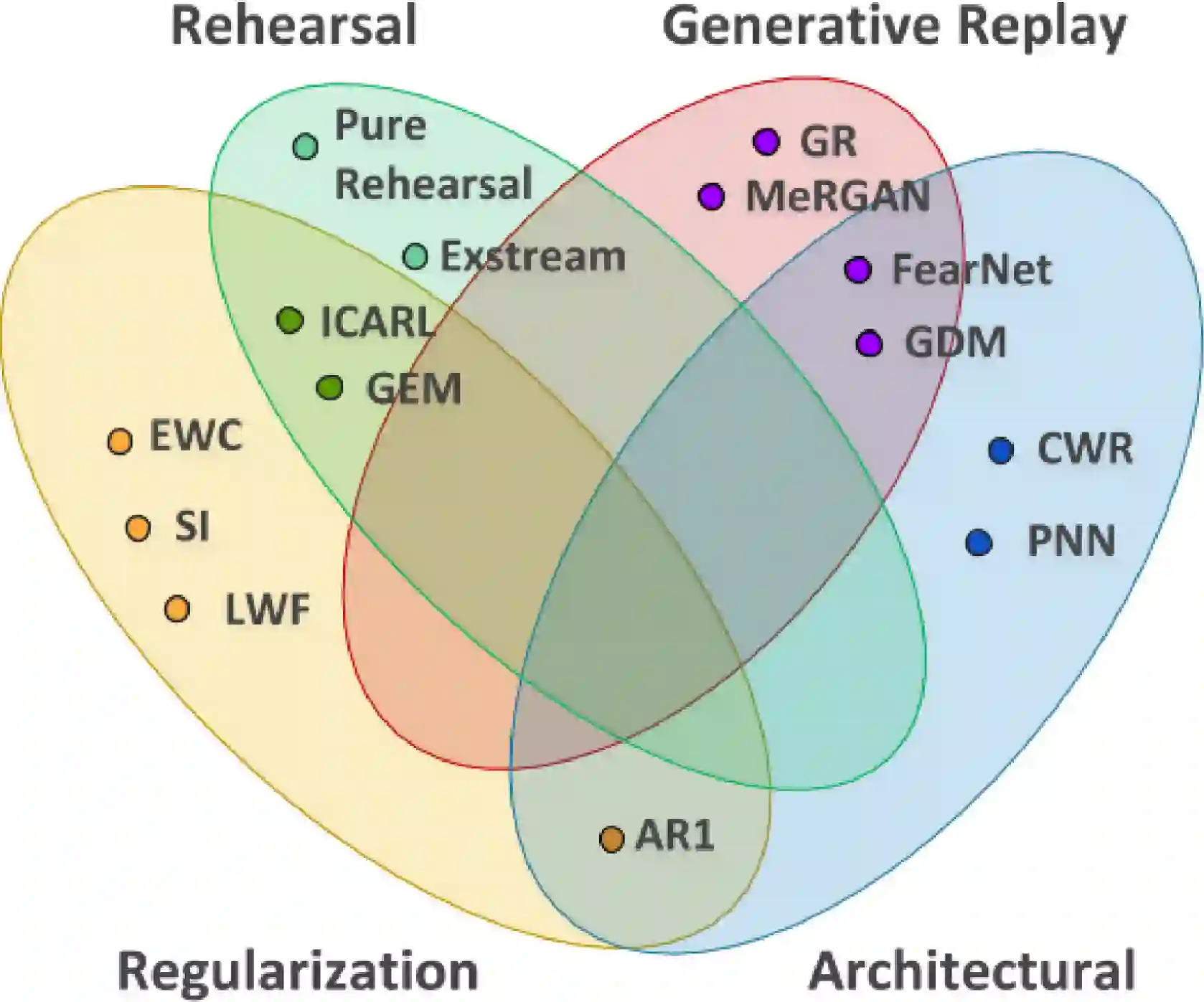
持续学习(CL)是一种特殊的机器学习范式,它的数据分布和学习目标会随着时间的推移而改变,或者所有的训练数据和客观标准都不会立即可用。学习过程的演变是以一系列学习经验为模型的,其中的目标是能够在学习过程中一直学习新的技能,而不会忘记之前学过的知识。CL可以看作是一种在线学习,需要进行知识融合,以便从按顺序及时呈现的数据流中学习。在学习过程中,不断学习的目的还在于优化记忆、计算能力和速度。机器学习的一个重要挑战不是必须找到在现实世界中有效的解决方案,而是找到可以在现实世界中学习的稳定算法。因此,理想的方法是在嵌入的平台中处理现实世界:自治的代理。持续学习在自主代理或机器人中是有效的,它们将通过时间自主学习外部世界,并逐步发展一套复杂的技能和知识。机器人必须学会通过连续的观察来适应环境并与之互动。一些最近的方法旨在解决机器人持续学习的问题,但最近关于持续学习的论文只是在模拟或静态数据集的实验方法。不幸的是,对这些算法的评估并不能说明它们的解决方案是否有助于在机器人技术的背景下持续学习。这篇论文的目的是回顾持续学习的现有状态,总结现有的基准和度量标准,并提出一个框架来展示和评估机器人技术和非机器人技术的方法,使这两个领域之间的转换更加容易。我们在机器人技术的背景下强调持续学习,以建立各领域之间的联系并规范方法。
https://www.sciencedirect.com/science/article/pii/S1566253519307377#sec0001
概要:
机器学习(ML)方法通常从平稳数据分布中随机采样的数据流中学习。这通常是有效学习的必要条件。然而,在现实世界中,这种设置相当少见。持续学习(CL)[128]汇集了解决当数据分布随时间变化时,以及在永无止境的数据流中需要考虑的知识融合的学习问题的工作和方法。因此,CL是处理灾难性遗忘[47]的范式[102]。
为了方便起见,我们可以根据经验将数据流分割成几个子段,这些子段有时间边界,我们称之为任务。然后我们可以观察在学习一项新任务时所学到或忘记了什么。即使对任务没有强制约束,任务通常指的是一段特定的时间,其中数据分布可能(但不一定)是平稳的,并且目标函数是常量。就学习目标而言,任务可以是相互独立的,也可以是相互关联的,并且取决于设置。
持续学习的一个解决方案是保存所有数据,打乱它,然后回到传统的机器学习设置。不幸的是,在这种情况下,这并不总是可能的,也不是最佳的。这里有几个例子,其中持续学习是必要的:
你有一个训练过的模型,你想用新的数据更新它,但是原来的训练数据被丢弃了,或者你没有权利再访问它。
你想在一系列任务上训练一个模型,但你不能存储你的所有数据,或者你没有计算能力从所有数据中重新训练模型(例如,在嵌入式平台中)。
您希望智能代理学习多种策略,但您不知道学习目标何时发生变化,如何变化。
您希望从持续的数据流中学习,这些数据可能会随着时间而变化,但您不知道如何变化,何时变化。
为了处理这些设置,表示应该通过在线方式学习[87]。随着数据被丢弃并且生命周期有限,忘记不重要的东西而保留对未来有意义的东西的能力是持续学习的主要目标和重点。
从机器人技术的角度来看,CL是发展机器人技术的机器学习答案[93]。发展机器人技术是一种交叉学科的方法,用于自主设计人工主体的行为和认知能力,直接从儿童自然认知系统中观察到的发展原则和机制中获得灵感。
在这种情况下,CL必须包含一个学习累积技能的过程,并能逐步提高所处理任务的复杂性和多样性。
自主主体在这样的环境中以开放式的[36]方式学习,但也以持续的方式学习。这种发展方法的关键组成部分包括学习自主产生目标和探索环境的能力,开发内在动机[113]和好奇心的计算模型[112]。
我们提出了一个框架来连接持续学习和机器人技术。这个框架也为持续学习提供了机会,以一个有框架的数学公式以清晰和系统的方式呈现方法。
首先,我们介绍了持续学习的背景和历史。其次,我们的目标是在不断学习的基础上理清概念汇。第三,我们将介绍我们的框架作为一种标准的CL方法,以帮助在不同的持续学习领域之间进行转换,特别是对于机器人技术。第四,我们提供了一组度量标准,它将有助于更好地理解每一类方法的质量和缺点。最后,我们提出了持续学习机器人技术的细节和机会,这使得CL变得如此重要。
对于机器人技术和非机器人技术领域,我们保持了定义、框架、策略和评估的一般性。尽管如此,最后一节,机器人持续学习(第6节)受益于前几节的内容,以呈现机器人领域持续学习的特殊性。