
经典的机器学习隐含地假设训练数据的标签是从一个干净的分布中采样的,这对于真实的场景来说限制太大了。然而,基于统计学习的方法可能不能很好地训练深度学习模型。因此,迫切需要设计标签噪声表示学习(LNRL)方法对带噪声标签的深度模型进行鲁棒训练。为了充分了解LNRL,我们进行了综述。我们首先从机器学习的角度阐明LNRL的形式化定义。然后,通过学习理论和实证研究的视角,找出了噪声标签影响深度模型性能的原因。在此基础上,我们将不同的LNRL方法分为三个方向。在这个统一的分类法下,我们将全面讨论不同类别的优缺点。更重要的是,我们总结了鲁棒的LNRL的基本组件,它们可以激励新的方向。最后,我们提出了LNRL可能的研究方向,如新数据集、实例依赖的LNRL和对抗性LNRL。最后,我们展望了LNRL之外的潜在方向,比如使用特征噪声、偏好噪声、领域噪声、相似性噪声、图形噪声和演示噪声进行学习。
https://arxiv.org/abs/2011.04406
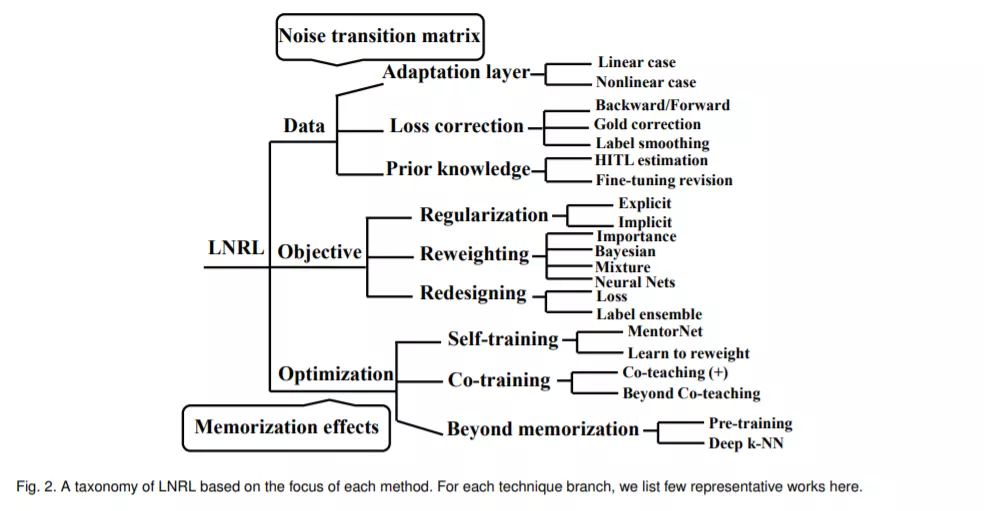
标签噪声表示学习在学术界和工业界都非常重要。背后有两个原因。首先,从学习范式的本质来看,深度监督学习需要大量的有良好标签的数据,这可能需要太多的成本,尤其是对于许多初创企业来说。然而,深度无监督学习(甚至是自我监督学习)还不够成熟,无法在复杂的现实场景中很好地发挥作用。因此,作为深度弱监督学习,标签噪声表示学习自然受到了广泛的关注并成为研究的热点。其次,从数据方面来看,许多真实的场景缺乏纯粹干净的注释,比如金融数据、web数据和生物医学数据。这直接激发了研究人员探索标签噪声表示学习。
据我们所知,确实有三篇关于标签噪声的综述的工作。Frenay和Verleysen[8]专注于讨论标签噪声统计学习,而不是标签噪声表示学习。尽管Algan等人[9]和Karimi等人[10]。它们都专注于带噪声标签的深度学习,都只考虑图像(或医学图像)的分类任务。此外,他们的调查是从应用的角度写的,而不是讨论方法。为了弥补这些缺陷,我们希望对标签噪声表示学习领域做出如下贡献。
-
从机器学习的角度,我们给出了标签噪声表示学习(LNRL)的正式定义。这个定义不仅足够通用,可以包含所有现有的LNRL,而且也足够具体,可以阐明LNRL的目标是什么以及我们如何解决它。
-
与[9]、[10]相比,通过学习理论的视角,我们更深入地理解了为什么噪声标签会影响深度模型的性能。同时,我们报告了在噪声标签下的深度模型的泛化,这与我们的理论发现是一致的。
-
我们进行了大量的文献综述,从表示学习开始,并在一个统一的分类,在数据,目标和优化。分析了不同类别的利弊。我们还对每个类别的见解进行了总结。
-
基于上述观察,我们总结和讨论了鲁棒标签噪声表示学习的基本组成部分。这些可以帮助启发标签噪声表示学习的新方向。
-
除了标签噪声表示学习,我们提出了几个有前途的未来方向,如学习噪声特征、偏好、领域、相似性、图和演示。我们希望他们能提供一些见解。
