【斯坦福经典书】强化学习在金融应用,414页pdf

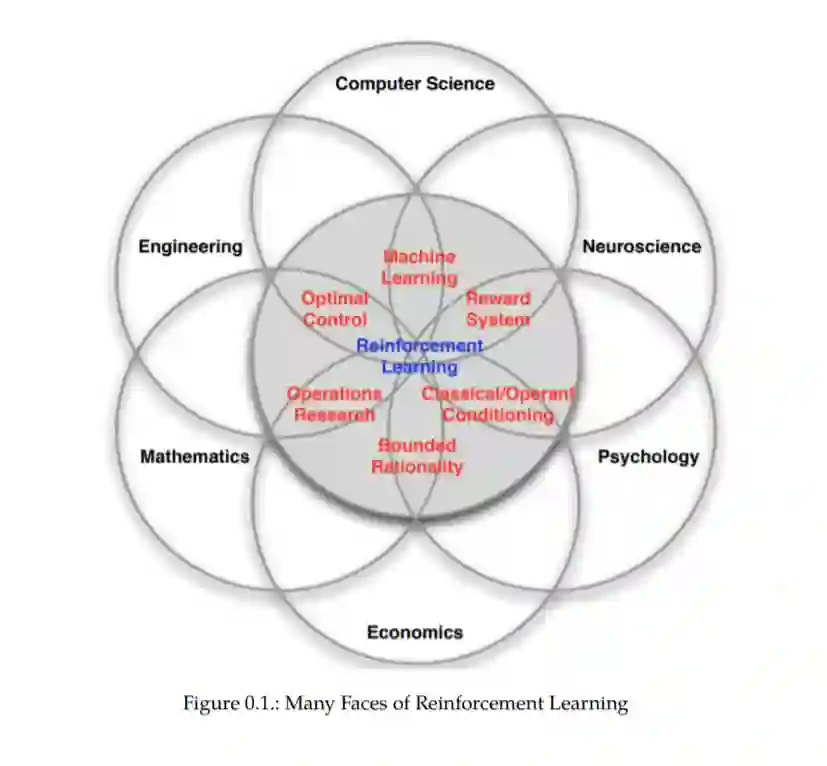
强化学习(RL)作为一种可行的、强大的技术,用于解决各种复杂的跨行业业务问题,包括在不确定性下的顺序优化决策。尽管RL被归类为机器学习(ML)的一个分支,但它的看待和处理方式往往与机器学习的其他分支(监督和非监督学习)非常不同。事实上,RL似乎掌握了开启人工智能前景的关键——人工智能可以根据观察到的信息的变化来调整决策,同时不断朝着最优结果前进。RL算法在无人驾驶汽车、机器人和策略游戏等备受瞩目的问题上的渗透,预示着未来RL算法的决策能力将远超人类。
本书重点研究支撑RL的基础理论。我们对这一理论的处理是基于本科水平的概率、优化、统计和线性代数。我们强调严谨但简单的数学符号和公式来发展理论,并鼓励你把方程写出来,而不是仅仅从书中阅读。偶尔,我们引用一些高等数学(如:随机微积分),但本书的大部分是基于容易理解的数学。特别是,两个基本的理论概念- Bellman最优方程和广义策略迭代-贯穿全书,因为它们构成了我们在RL中所做的几乎所有事情的基础,甚至在最先进的算法中。
本书第二部分用动态规划或强化学习算法解决的金融应用。作为随机控制问题的许多金融应用的一个基本特征是,模型MDP的回报是效用函数,以捕捉金融回报和风险之间的权衡。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RL414” 就可以获取《【斯坦福经典书】强化学习在金融应用,414页pdf》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2021年6月23日
Arxiv
0+阅读 · 2021年6月22日





相关VIP内容
相关资讯