论文浅尝 | 知识图谱增强的机器翻译

笔记整理:张嘉芮,天津大学硕士
链接:https://www.ijcai.org/Proceedings/2020/0559.pdf
动机
在机器翻译中,实体的正确翻译对于译文质量有着至关重要的作用。知识图(KG)在各种实体上存储了大量结构化信息,其中许多实体不在神经机器翻译(NMT)的双语句子对中,导致实体的错翻率较高,因此本文关注神经机器翻译中的实体翻译。
亮点
本文的亮点主要包括:
(1)提出了一种将非并行KG合并到NMT模型中的方法。
模型
问题定义:
本文所利用的数据资源包括以下三个:
1.双语句子对:D={(X,Y)},其中X是源语言,Y是目标语言。
2.源语言知识图谱:
3.目标语言知识图谱:
注:
其中
框架:
模型整体框架如下:
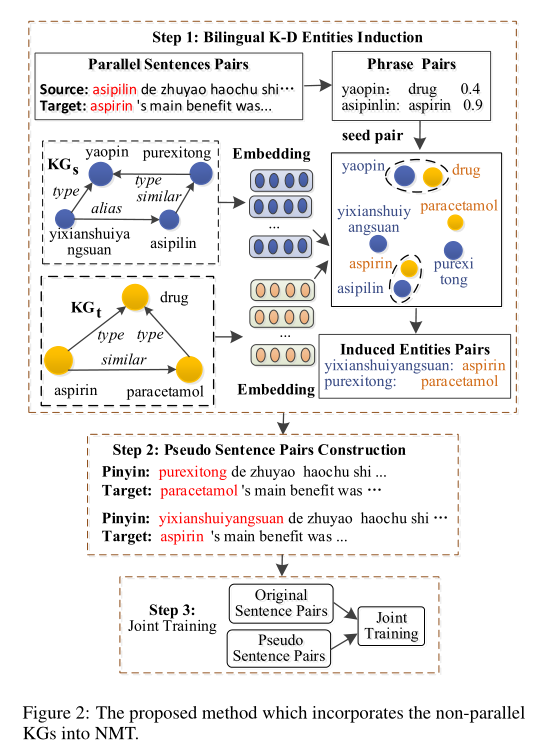
1.双语K-D实体推断
①将源语言知识图谱
②利用双语句对,首先提取出短语翻译对,利用上述段语言翻译对作为种子实体翻译对。
③利用种子实体翻译对为锚点,将
④根据语义距离,预测出K-D实体的译文。
2.伪双语数据构造
3.联合训练
将原始双语数据和伪双语数据进行联合训练,学习神经机器翻译的参数,损失函数为:
1.总体结果

本文所提方法在中英(医疗领域、旅游领域和通用领域)和英日翻译任务上均有一定BLEU值的提升。
2.超参数分析
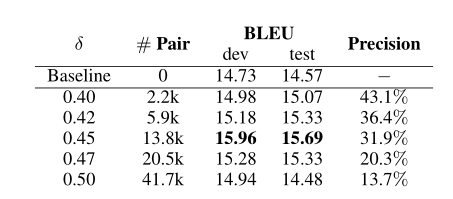
在算法1中,本文设置了一个预定义的超参数δ来确定双语对。表中显示了不同δ(医学KG)的BLEU分数。可以看到,当δ=0.45时,BLEU分数最大。当δ超过0.45时,BLEU分数(dev)从15.96降至14.94。同时结果表明:需要在K −D实体对的数量之间取得平衡,并不是越多越好。
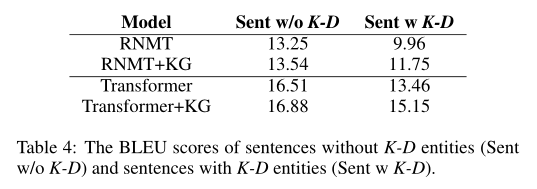
3.K-D实体的分析
总结
为了解决NMT中的K-D实体,本文提出了一种知识图谱增强的NMT方法。本文设计了一种新的方法来归纳K-D实体使用KG生成的翻译结果,生成伪并行句子对,最后联合训练NMT模型。在汉英翻译和英日翻译任务上的大量实验表明,本文方法在翻译质量上明显优于基线模型,尤其是在处理K−D实体上。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

