

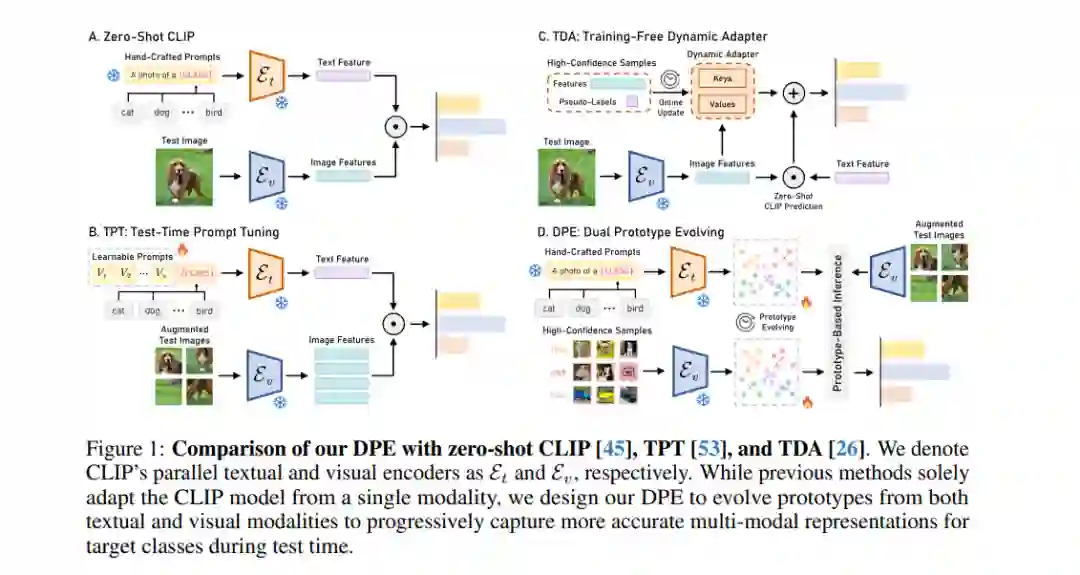
测试时自适应 (Test-time adaptation) 使模型能够在无标签测试样本下对多样化数据进行泛化,在现实应用中具有重要价值。近期,研究人员将这种设置应用于高级预训练视觉-语言模型 (Vision-Language Models, VLMs),提出了如测试时提示调优(test-time prompt tuning)等方法,以进一步扩展其实际适用性。然而,这些方法通常仅关注单模态的VLMs适应性,且在处理更多样本时,未能累积任务特定知识。为了解决这一问题,我们提出了双原型演化 (Dual Prototype Evolving, DPE),这是一种新的VLMs测试时自适应方法,可以有效地从多模态中累积任务特定知识。具体来说,我们创建并不断演化两组原型——文本和视觉原型——以在测试时逐步捕捉目标类别的更准确的多模态表示。此外,为了促进多模态表示的一致性,我们为每个测试样本引入并优化可学习残差,以对齐来自不同模态的原型。在15个基准数据集上的广泛实验结果表明,我们提出的DPE方法不仅在性能上持续优于当前最先进的方法,同时在计算效率上也具备竞争力。代码可在 https://github.com/zhangce01/DPE-CLIP 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日