在这项工作中,我们探讨了大型语言模型(LLM)直接理解视觉信号而无需在多模态数据集上进行微调的可能性。我们方法的基础概念将图像视为一种语言实体,并将其翻译为源自LLM词汇表的一组离散单词。为实现这一点,我们提出了视觉到语言的分词器,简称为V2T分词器,该分词器借助编解码器、LLM词汇表和CLIP模型的综合帮助,将图像转换为“外国语言”。借助这种创新的图像编码,LLM不仅获得了视觉理解的能力,而且还能以自回归的方式进行图像去噪和恢复——关键是,无需任何微调。我们进行了严格的实验来验证我们的方法,包括理解任务如图像识别、图像字幕和视觉问答,以及图像去噪任务如图像修复、图像外扩、去模糊和偏移恢复。代码和模型可在 https://github.com/zh460045050/V2L-Tokenizer 上获取。
在自然语言处理(NLP)领域通过部署大型语言模型(LLM),如GPT [3, 30, 34, 35]、PaLM [2, 6]和LLaMA [45, 46],已经取得了显著进展。为了解决需要文本和视觉理解相结合的复杂挑战,学者们正在扩大现成LLM的能力。这种增强包括加入额外的视觉处理组件,以便于理解视觉内容[13, 23–25, 62]或从文本生成图像[41, 50, 59, 61]。随后,这些改进的模型会通过使用各种多模态数据集进行额外的重新训练或微调,以将视觉潜在空间与语言潜在空间对齐。尽管如此,精炼过程通常需要大量的训练资源。如图1所示,本工作旨在赋予大型语言模型天生的理解视觉信号的能力,重要的是,无需微调。在我们的方法中,我们将每幅图像视为源自“外语”的语言实体,将其适配以满足普通LLM的输入要求。因此,这种对齐发生在输入(令牌)空间而不是特征空间,这使我们的工作区别于之前需要微调以进行模态对齐的多模态方法[1, 23, 24, 62]。因此,在我们的方法论中可以避免多模态数据集上的微调或重新训练过程。我们的技术将图像转换为一系列属于LLM词汇表内的离散令牌。一旦转换,这些令牌可以被输入LLM,使其能够处理并理解视觉信息,从而促进涉及图像理解和去噪的一系列任务。
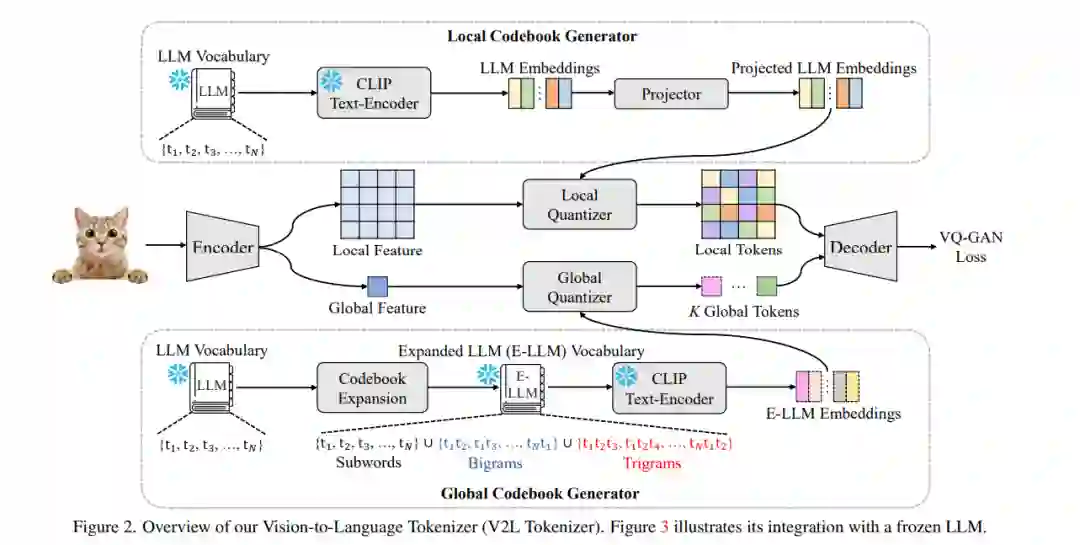
将图像转换为被冻结的LLM能够理解的一组令牌是具有挑战性的。在这项工作中,我们介绍了一个旨在将图像(非语言模态)映射到冻结LLM的输入(令牌)空间的分词器。这个分词器被称为视觉到语言分词器,或简称为V2L分词器。受到VQ-GAN [12]胜利进展的启发,V2L分词器采用了编码器-量化器-解码器结构。然而,其目标是将视觉信息翻译到LLM的令牌空间。这与其灵感来源不同,后者旨在仅为图像生成的目的学习一个独立的潜在空间。我们的V2L分词器避免了优化随机初始化的量化器代码本的标准过程;相反,它在整个训练过程中利用LLM的预先存在的词汇表作为其量化器代码本。在优化过程完成后,图像通过量化损失函数的指导被转换为一组LLM令牌。
通常,LLM的词汇表包含全词和子词单元,这是由于使用了如BPE [42]和SentencePiece [19]等语言分词器。在不失一般性的情况下,这个词汇表的广度影响了其将图像编码为LLM令牌的能力——通常,更大的词汇表提供了更强大的表示能力。在我们的方法中,我们通过组合其词汇项形成双词或三词语,显著增加了在将图像映射到LLM令牌时的表示能力。除了将每个图像块转换为语言令牌外,我们的V2L分词器还包括提取整个图像的全局表示。我们通过使用扩展LLM词汇表中的子词、双词或三词语的组合来实现这一点,以封装图像的全面信息。
在上下文学习[3, 27, 28]中已被证明对LLM的零样本推断非常有益。这是通过在LLM推断过程中,用一些领域特定的示例前置指令文本来实现的。我们的方法避免了LLM微调的必要性,而是采用在上下文学习来指导LLM模仿给定的少样本示例中呈现的模式。这使得模型能够更好地理解“外语”(即,视觉模态)。 实验上,我们的工作在这一新颖情景中超越了之前的尝试[25, 54],在该情景中,一个LLM能够在没有任何微调或重新训练的情况下理解视觉信号,包括理解任务如图像字幕和视觉问答,以及图像去噪任务如图像修复、外扩、去模糊和图像恢复。