

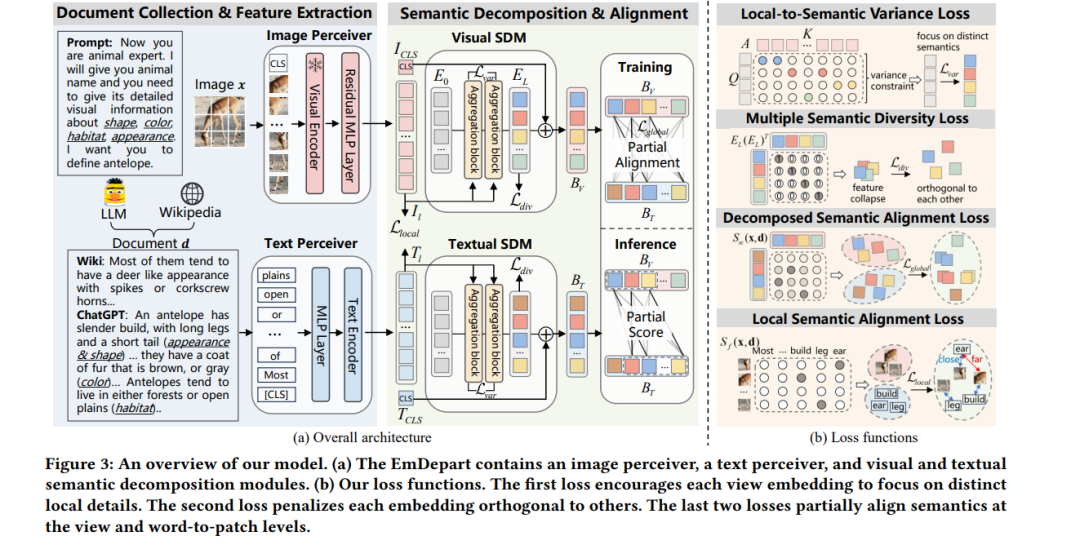
最近的研究表明,百科全书中的文档作为辅助信息对零样本学习非常有帮助。现有方法通过将整个文档的语义与相应的图像对齐来传递知识。然而,这些方法忽略了语义信息在两者之间并不等价,导致次优的对齐效果。在本研究中,我们提出了一种新颖的网络,从文档和图像中提取多视角的语义概念,并对匹配的部分概念进行对齐,而不是整个概念。具体来说,我们提出了一个语义分解模块,从视觉和文本方面生成多视角的语义嵌入,为部分对齐提供基本概念。为了缓解嵌入中的信息冗余问题,我们提出了局部到语义方差损失,以捕捉不同的局部细节,并提出多语义多样性损失,以在嵌入之间强制正交性。随后,引入了两种损失,根据它们在视图和词到片段级别的语义相关性,部分对齐视觉-语义嵌入对。因此,我们在三种标准基准测试的两个文档来源下,一直优于最新的方法。在定性方面,我们表明我们的模型学习到了可解释的部分关联。代码可在此获取。
成为VIP会员查看完整内容
相关内容

ACM 国际多媒体大会(英文名称:ACM Multimedia,简称:ACM MM)是多媒体领域的顶级国际会议,每年举办一次。
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日