

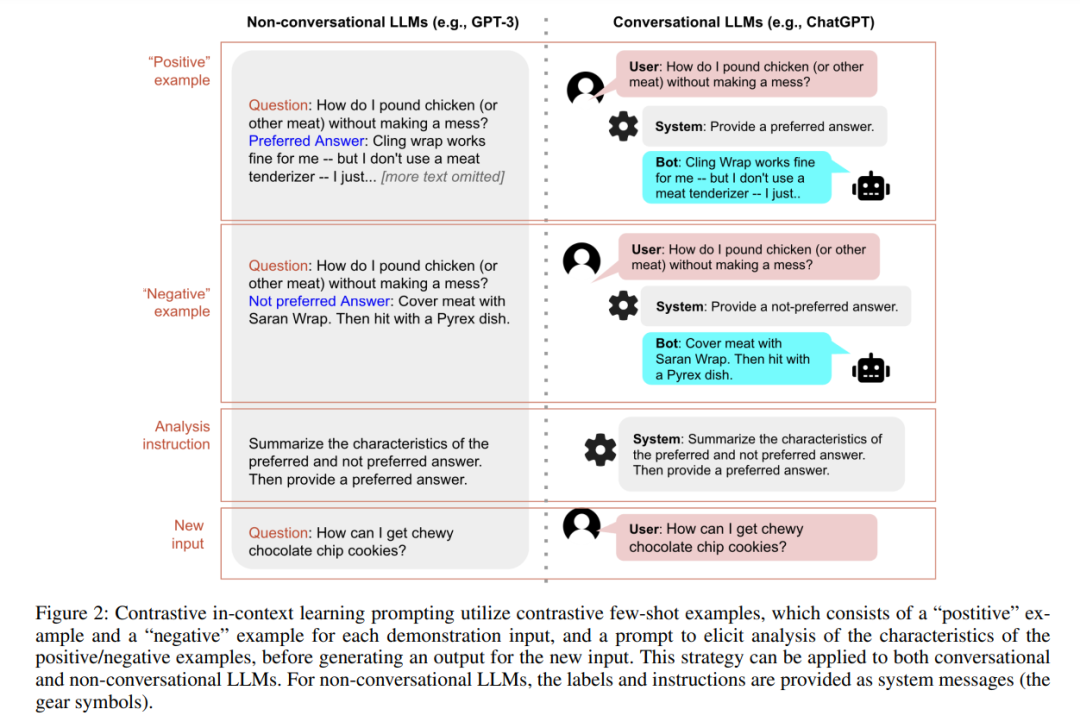
大型语言模型(LLMs)对于机器学习应用变得越来越重要。然而,使LLMs与我们的意图保持一致可能是具有挑战性的,特别是当我们想要生成优先于其他内容的内容,或者当我们希望LLM以某种难以描述的风格或语调响应时。为了应对这一挑战,我们提出了一种使用对比例子来更好描述我们意图的方法。这涉及提供展示真实意图的正面例子,以及展示我们希望LLMs避免的特征的负面例子。负面例子可以从标记数据中检索,由人类编写,或由LLM本身生成。在生成答案之前,我们要求模型分析这些例子,以教会自己需要避免什么。这一推理步骤为模型提供了用户需求的适当阐述,并引导它生成更好的答案。我们在合成和真实世界数据集上测试了我们的方法,包括StackExchange和Reddit,发现与标准的少次数提示相比,它显著提高了性能。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日