
导 读
本文是对于发表在 RSS 2024 的论文 NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation 的解读。该工作由北京大学王鹤团队与北京智源人工智能研究院、自动化研究所、阿德莱德大学、澳大利亚国立大学和北京银河通用机器人合作完成。共同第一作者包括北京大学计算机学院博士生张嘉曌,以及北京智源人工智能研究院的实习生王堃宇和许镕涛。

↑扫码跳转论文
项目主页:
https://pku-epic.github.io/NaVid/ 论文:
https://arxiv.org/pdf/2402.15852
NaVid 是首个专为视觉语言导航(VLN)**任务设计的基于视频的视觉语言大模型。**此模型模仿人类导航策略,仅将视频信息作为输入,无需地图、里程计或深度数据的支持。为训练 NaVid,我们还在仿真环境中收集了510k 个 VLN 样本。在仿真环境和现实世界的测试中,NaVid 展示出了前所未有的性能,并且在未知场景中的实验验证了其卓越的泛化能力。 视频1. NaVid 在 VLN-CE 模拟器(RxR 和 R2R)上的结果
01
背 景
视觉语言导航任务[1],是机器人可以根据人类的文字指令, 在未知场景中进行导航的一种任务。视觉语言导航任务的指令来自人类的自然语言,并不需要显式的规定格式。一个例子如下:
穿过浴室对面的门。经过钢琴,继续前进经过挂着小提琴的墙。在放着花瓶的桌子前停下。
这种任务具有人机交互的直观性和易用性,机器人仅需根据日常语言即可进行导航。同时也可以用来设计辅助设备,如帮助视觉障碍人士或老年人在未知环境中独立导航。然而视觉语言导航任务是非常有挑战的。它要求机器人需要同时精确地理解人类指令和场景信息,并在线的规划合理的路径完成指令。大部分已有的工作通过简化任务,如使用预先定义好的路标点(landmark),全景图,地图,无噪声的深度图和坐标信息。这些简化又会带来额外的 sim-to-real 的挑战。
近些年来,多模态大语言模型展现了令人印象深刻的理解文字和视觉信号的能力。更重要的是,通过学习大量的数据,多模态大语言模型被广泛的认为具有极强的泛化能力。本文考虑进一步将大模型的能力扩展到视觉导航任务中,通过将指令和导航视频作为大模型的输入,直接输出底层的执行命令,如前进,转向和停止。我们认为这种方法避免了对地图,坐标等信息的依赖,更接近人类的导航模式(视觉信息输入-动作信号输出)。
02
方 法
实现可用于导航任务的视频大模型主要有两个难点:
1)导航数据的模态与大模型常见的数据模态不一致。机器人的导航数据需要建模历史信息和当前信息,并保证导航过程中动作输出的格式一致性。
2)缺少大量高质量的视觉语言导航任务的真实数据。在真实世界收集这样的数据极其耗时耗力,且在场景和指令的多样性上有欠缺。这些困难限制了视频大模型用于导航任务的前景。
2.1 用于视觉语言导航的视频大模型
NaVid 基于通用视频大模型 LLaMA-VID[2],并在其基础上加入针对视觉导航任务的设计。LLaMA-VID 主要包含三个模块,图像编码器(Observation Encoder),文字编码器(BERT)[3]和大语言模型(Vicuna-7B)[4]。 图像编码器和文字编码器,被分别用于提取对应的图像信号(逐帧)和文字信号到词元,这些词元(Tokens)经组合后通过大语言模型处理以得到最终回答。
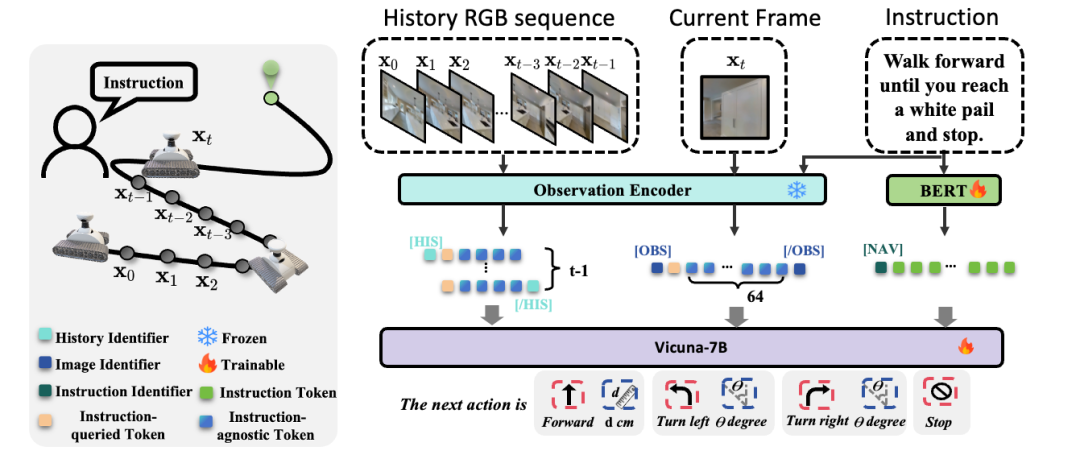
图1. NaVid 结构图
在视觉语言导航任务中,模型需要利用历史信息去理解自己完成到指令的哪一部分,由于大量的历史帧存在冗余和重复的信息,而对于当前帧,不仅需要提供其所在的最新场景信息,还需要预测符合指令的下一步合理动作。这种图像信号作用的显著不同,要求我们分别编码历史视频信息和当前视频信息。因此,我们分别对历史帧和当前帧的图像信号,进行不同程度的池化,来保留不同程度的信息量。
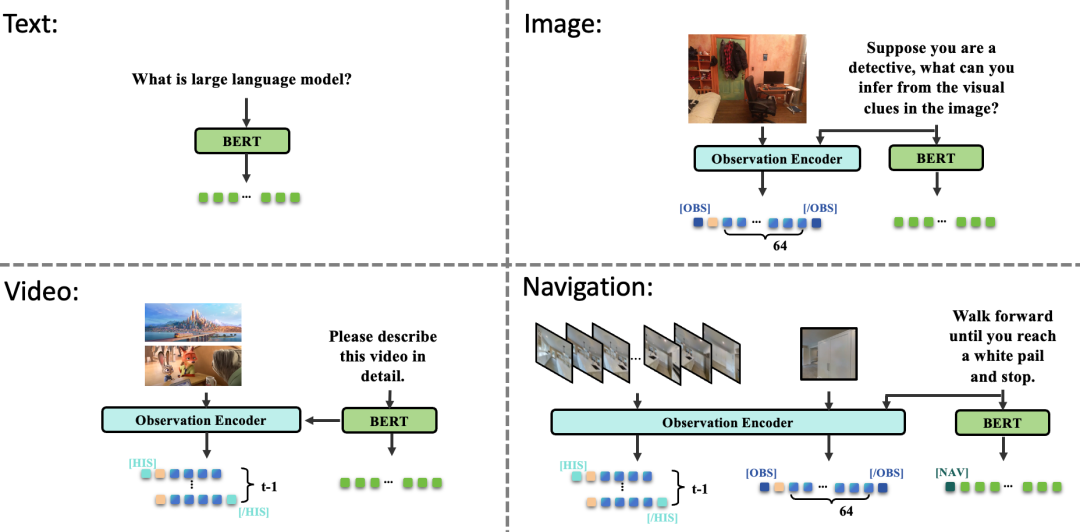
图2. 不同模态数据的词元序列
除此之外,为了让模型仍然可以理解常见模态的数据,我们使用了特殊词元(special tokens)去标识不同的信息,如历史信息([HIS]和[/HIS]),当前帧([OBS] 和 [/OBS])和指令 [NAV]。这些标识可以帮助大模型区分当前输入的词元序列来自于哪一种模态,实现多种模态的联合训练。这种联合训练方式能够避免灾难性遗忘(Catastrophic Forgetting)的问题,在学习导航数据的时候同时保持对自然世界的理解。更多的实现细节请参考原文。
**2.2 **视觉语言导航数据
考虑到真实数据收集的难度大,成本高以及多样性有限。因此我们在模拟器 VLN-CE[5]中收集视觉语言导航数据,主要有两类:
1)**动作规划样本:**给定一条指令,我们收集这条指令对应的导航轨迹中的图像序列,回答对应的下一步动作。
2)**指令推理样本:**给定一条轨迹的图像,回答对应的指令。
我们共收集了32万动作规划样本和1万指令推理样本(见图3例子)。
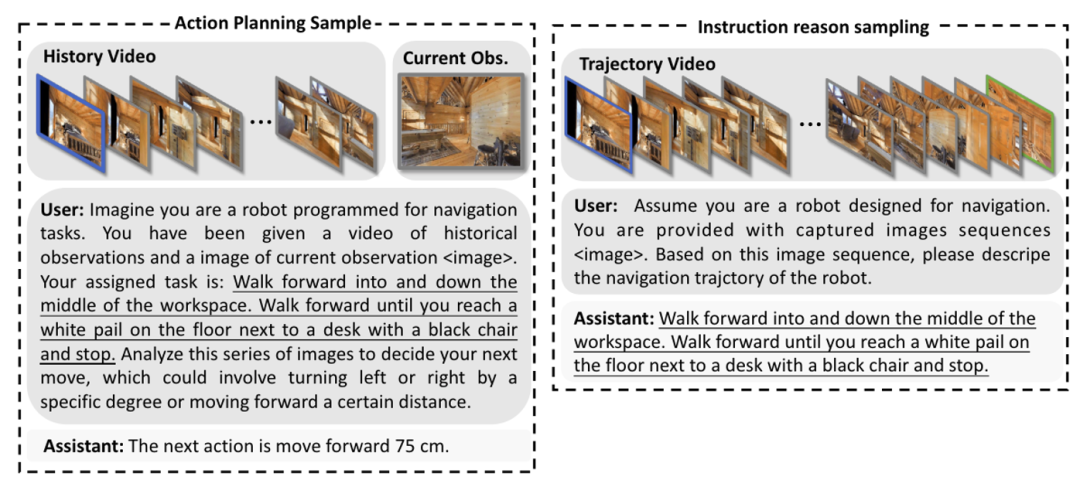
图3. 动作规划样本和指令推理样本的例子
需要注意的是,这样收集的数据只包含正确(Ground-Truth)的轨迹和指令信息。但是在实际进行导航推理时,模型需要理解具有噪声的轨迹(如历史轨迹中存在一些错误的动作)。因此我们利用 DAGGER[6]的方法,在模拟器中额外收集了18万包含噪声的导航数据。最终我们将导航数据和 LLaMA-VID 的多模态数据共同作为 NaVid 的训练数据。
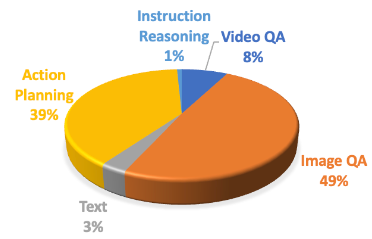
图4. 训练数据的分布,共120万数据
03
实验结果
我们在公开的模拟器数据集和真实场景测试了 NaVid 的表现。需要注意的是,NaVid 只使用了图像视频信息,没有使用深度图,里程计和地图。我们的方法的训练过程中只使用了模拟器 R2R train 中的数据。
在跨不同数据切分实验中(R2R train 训练,R2R Val-Unseen 推理),针对未见过的场景,未见过的指令数据中。我们方法只使用视频序列就实现了和 SOTA 方法相当的表现。
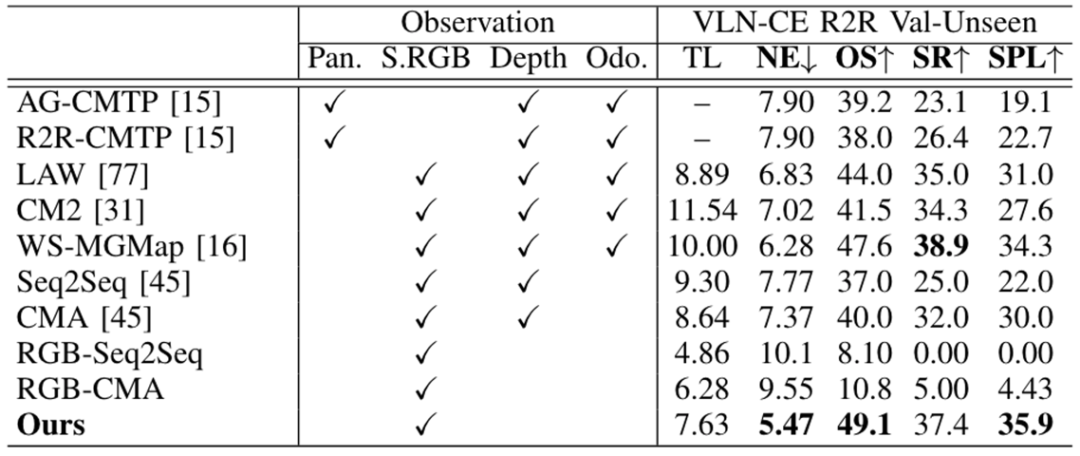
表1. R2R Val-Unseen 结果
在跨数据集实验****中(R2R train 训练,RxR Val-Unseen推理),针对未见过的场景,更复杂的指令数据,我们的方法实现了最好的表现。值得注意的是,仅使用视频的方法 RGB-Seq2Seq 和 RGB-CMA 几乎不能在 R2R 和 RxR 的数据集成功。这也证明了 NaVid 使用大模型的设计的有效性。
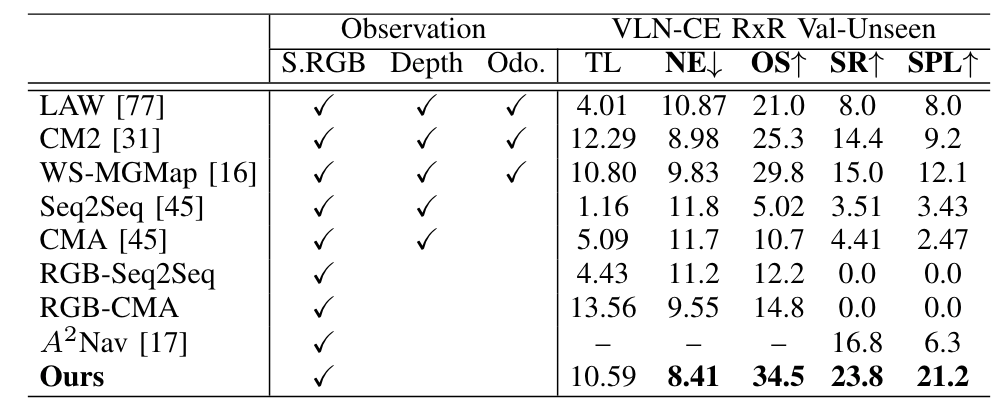
表2. RxR Val-Unseen 结果
我们的方法也在真实场景中进行了实验。我们测试了不同难度,不同环境的指令,我们发现 NaVid 具有很强的泛化能力,能够高质量完成不同指令。 视频2. 简单指令表现
视频3. 复杂指令表现
除了导航任务外,NaVid 还可以接受导航视频输入,并预测对应的导航指令。这种能力表明了 NaVid 可以理解机器人的导航历史,并为未来实现可解释和可交互的导航大模型提供了新的思路。 视频4. 视频理解表现
04
总 结
NaVid 是首个专为视觉语言导航(VLN)任务设计的基于视频的视觉语言模型(VLM)。其采用类似人类的导航方式,只需使用视频信息作为输入,无需依赖地图、里程计或深度信息。为了训练 NaVid,本工作还收集了来自仿真环境的510K 个 VLN 样本和763K 个现实世界的问答样本,有效实现了跨场景泛化。最终,在仿真和现实世界环境中,NaVid 均展现了最先进的性能,并在未知场景实验中显示出了卓越的泛化能力。
参考文献
[1] Gu, Jing et al. "Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions." Annual Meeting of the Association for Computational Linguistics (2022). [2] Li, Yanwei, Chengyao Wang, and Jiaya Jia. "LLaMA-VID: An image is worth 2 tokens in large language models." arXiv preprint arXiv:2311.17043 (2023). [3] Devlin, Jacob et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." North American Chapter of the Association for Computational Linguistics (2019). [4] Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench and chatbot arena." Advances in Neural Information Processing Systems 36 (2024). [5] Yue, Lu et al. "Safe-VLN: Collision Avoidance for Vision-and-Language Navigation of Autonomous Robots Operating in Continuous Environments." IEEE Robotics and Automation Letters 9 (2023): 4918-4925. [6] Ross, Stéphane et al. "A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning." International Conference on Artificial Intelligence and Statistics (2010).
