

本文探索了一类新的基于transformer架构的扩散模型。训练图像的潜在扩散模型,用一个在潜在块上操作的transformer取代常用的U-Net骨干。通过Gflops测量的前向传递复杂性来分析扩散transformer (DiTs)的可扩展性。具有较高Gflops的DiTs——通过增加transformer深度/宽度或增加输入tokens 数量——始终具有较低的FID。除了具有良好的可扩展性,最大的DiT-XL/2模型在类条件ImageNet 512x512和256x256基准上的性能优于所有先验的扩散模型,在后者上实现了最先进的FID 2.27。 https://www.wpeebles.com/DiT
1. 引言
在transformers的推动下,机器学习正在复兴。在过去的五年中,自然语言处理[8,39]、视觉[10]和其他几个领域的神经架构在很大程度上被transformer[57]所涵盖。然而,许多类别的图像级生成模型仍然坚持这一趋势,尽管transformer在自回归模型中被广泛使用[3,6,40,44],但在其他生成模型框架中被采用的较少。例如,扩散模型一直处于图像级生成模型最新进展的前沿[9,43];然而,它们都采用卷积U-Net架构作为事实上的骨干选择。
Ho等人的开创性工作[19]首先为扩散模型引入了U-Net主干。设计选择继承自PixelCNN++[49,55],一个自回归生成模型,有一些架构上的变化。该模型是卷积的,主要由ResNet[15]块组成。与标准的U-Net[46]相比,额外的空间自注意力块(transformer中的重要组成部分)在较低的分辨率下穿插。Dhariwal和Nichol[9]消除了U-Net的几个架构选择,例如使用自适应归一化层[37]来注入条件信息和卷积层的通道计数。然而,Ho等人提出的U-Net的高层设计在很大程度上保持不变。
**本文旨在揭开扩散模型中结构选择的意义,并为未来的生成式建模研究提供经验基线。**U-Net归纳偏差对扩散模型的性能不是至关重要的,可以很容易地被transformer等标准设计取代。因此,扩散模型很好地从最近的架构统一趋势中获益。通过继承其他领域的最佳实践和训练秘诀,以及保留可扩展性、鲁棒性和效率等良好特性。标准化的架构也将为跨领域研究开辟新的可能性。
本文关注一类新的基于transformer的扩散模型。我们称它们为扩散transformer,或简称DiTs。DiTs遵循视觉transformer (vit)[10]的最佳实践,已被证明比传统卷积网络(如ResNet[15])更有效地扩展视觉识别。
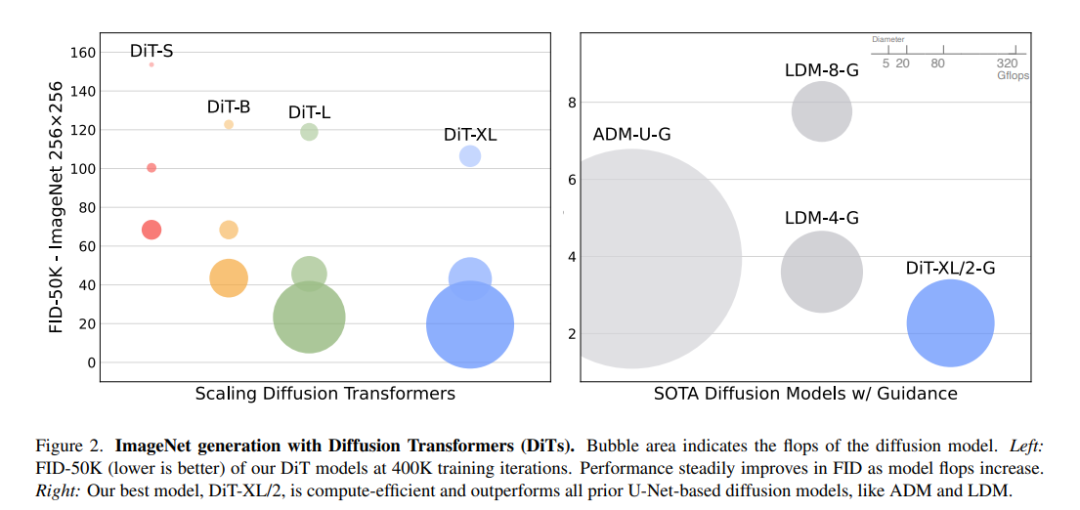
本文研究了transformer的扩展行为,即网络复杂性与样本质量之间的关系。通过在潜扩散模型(LDMs)[45]框架下构建DiT设计空间并对其进行基准测试,其中扩散模型是在VAE的潜空间中训练的,可以成功地用transformer取代U-Net主干。DiTs是扩散模型的可扩展架构:网络复杂性(由Gflops衡量)与样本质量(由FID衡量)之间有很强的相关性。通过简单地扩大DiT并训练具有高容量骨干(118.6 Gflops)的LDM,能够在有类条件的256 × 256 ImageNet生成基准上取得2.27 FID的最新结果。
Diffusion x Transformers
在过去的一年里,扩散模型在图像生成方面取得了惊人的成果。几乎所有这些模型都使用卷积U-Net作为骨干。这有点令人惊讶!在过去的几年里,深度学习的主要故事是transformer在各个领域的主导地位。U-Net或卷积是否有什么特别之处——使它们在扩散模型中工作得如此好?
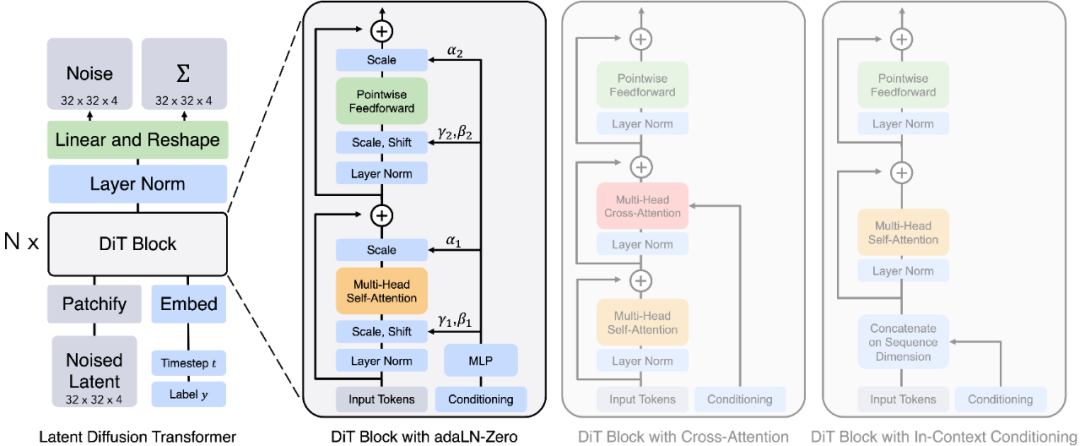
本文将潜在扩散模型(LDMs)中的U-Net骨干替换为transformer。我们称这些模型为扩散transformer,或简称DiTs。DiT架构非常类似于标准的视觉Transformer (ViT),有一些小但重要的调整。扩散模型需要处理条件输入,如扩散时间步或类标签。我们尝试了一些不同的模块设计来注入这些输入。最有效的是具有自适应层norm层(adaLN)的ViT块。重要的是,这些adaLN层还调制块内任何残差连接之前的激活,并被初始化为每个ViT块都是identity函数。简单地改变注入条件输入的机制就会在FID方面产生巨大的差异。这是我们获得良好性能所需的唯一更改;除此之外,DiT是一个相当标准的transformer模型。
Scaling DiT

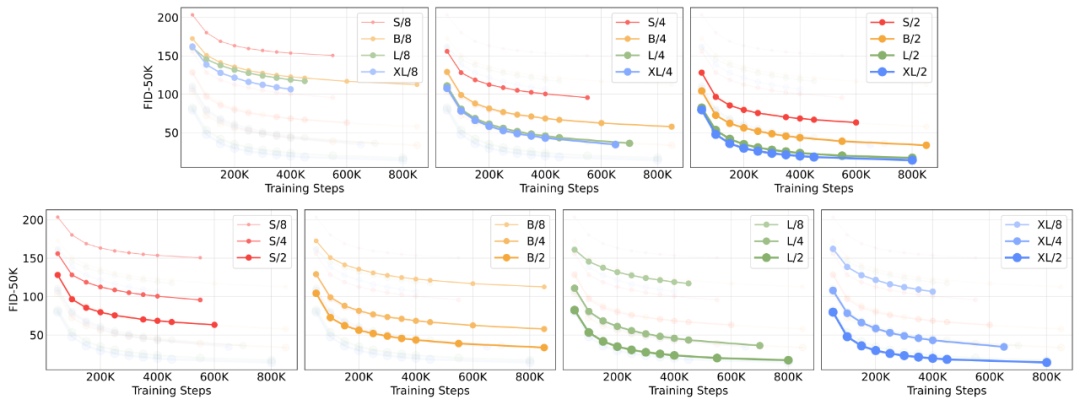
可视化放大DiT的效果。我们使用相同的采样噪声,在400K训练步骤中从所有12个DiT模型生成图像。计算密集型的DiT模型具有更高的样本质量。 众所周知,transformer在各种领域都具有良好的扩展性。那么作为扩散模型呢?本文将DiT沿两个轴进行缩放:模型大小和输入标记数量。
*扩展模型大小。我们尝试了四种不同模型深度和宽度的配置:DiT-S、DiT-B、DiT-L和DiT-XL。这些模型配置范围从33M到675M参数和0.4到119 Gflops。它们是从ViT文献中借来的,该文献发现联合放大深度和宽度效果很好。
扩展标记。DiT中的第一层是patchify层。Patchify将每个patch线性嵌入到输入图像(或在我们的例子中,input latent)中,将它们转换为transformer token。较小的patch大小对应于大量的transformer token。例如,将patch大小减半会使transformer的输入token数量增加四倍,从而使模型的总Gflops至少增加四倍。尽管它对Gflops有巨大的影响,但请注意,patch大小对模型参数计数没有意义的影响。
对于我们的四个模型配置中的每一个,我们训练三个模型,潜块大小为8、4和2(共12个模型)。Gflop 最高的模型是DiT-XL/2,它使用最大的XL配置,patch大小为2。
通过Fréchet Inception Distance (FID)测量,扩展模型大小和输入tokens 数量可以大大提高DiT的性能。正如在其他领域观察到的那样,计算(而不仅仅是参数)似乎是获得更好模型的关键。例如,虽然DiT-XL/2获得了优秀的FID值,但XL/8表现不佳。XL/8的参数比XL/2多一些,但Gflops少得多。较大的DiT模型相对于较小的模型是计算效率高的;较大的模型比较小的模型需要更少的训练计算来达到给定的FID(详细信息请参见论文)。
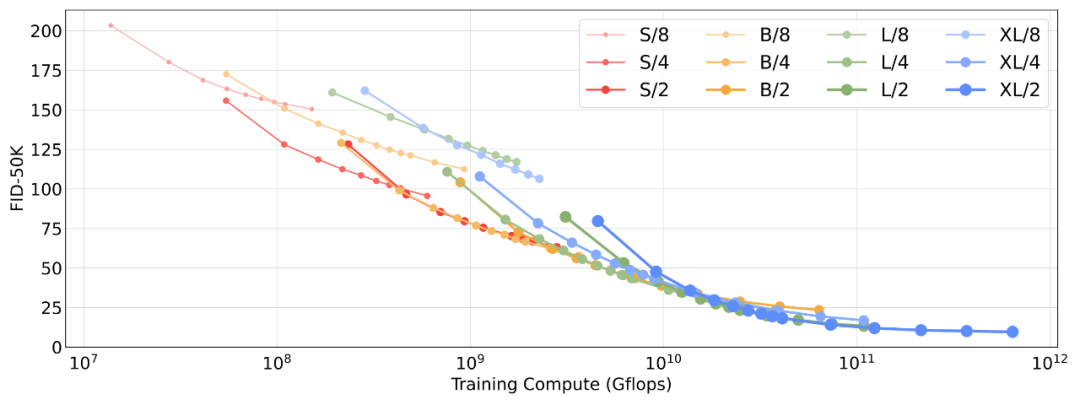
根据我们的扩展分析,当训练时间足够长时,DiT-XL/2显然是最佳模型。在本文的其余部分,我们将专注于XL/2。
与最新扩散模型的比较

从我们的DiT-XL/2模型中选择的样本,以512x512分辨率(顶部行)和256x256分辨率(底部)进行训练。在这里,我们使用无分类器指导规模,对512模型使用6.0,对256模型使用4.0。 我们在ImageNet上训练了两个版本的DiT-XL/2,分辨率分别为256x256和512x512,步骤分别为7M和3M。当使用无分类器指导时,DiT-XL/2优于所有先验扩散模型,将LDM (256x256)取得的3.60的之前最好的FID-50K降低到2.27;这是所有生成模型中最先进的。XL/2在512x512分辨率下再次优于所有先前的扩散模型,将ADM-U之前获得的最佳FID 3.85提高到3.04。
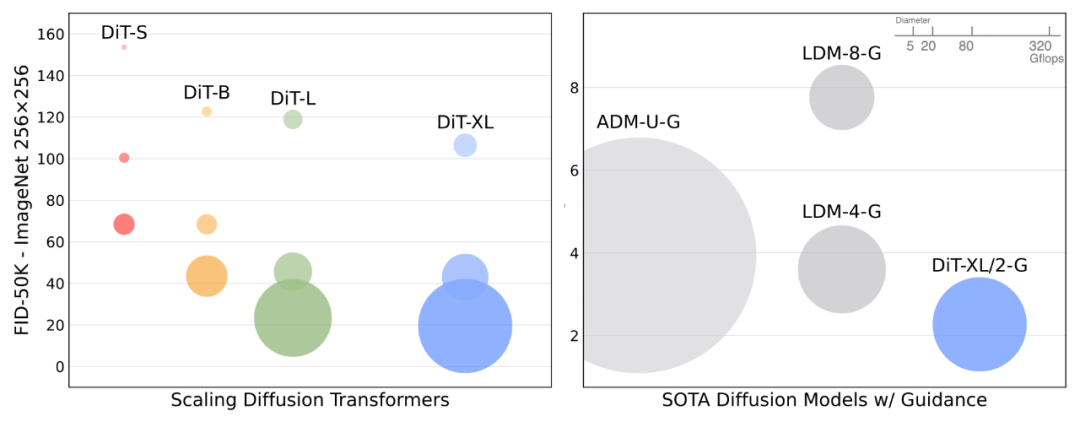
除了获得良好的FIDs外,DiT模型本身相对于基线仍然是计算高效的。例如,在256x256分辨率下,LDM-4模型是103 Gflops, ADM-U是742 Gflops, DiT-XL/2是119 Gflops。在512x512分辨率下,ADM-U是2813 Gflops,而XL/2只有525 Gflops。

