摘要—视频场景解析(Video Scene Parsing, VSP)已成为计算机视觉领域的核心任务之一,它促进了在动态场景中对多种视觉实体的同时分割、识别与跟踪。在本综述中,我们全面回顾了VSP的最新研究进展,涵盖了多个视觉任务,包括视频语义分割(Video Semantic Segmentation, VSS)、视频实例分割(Video Instance Segmentation, VIS)、视频全景分割(Video Panoptic Segmentation, VPS)、视频跟踪与分割(Video Tracking & Segmentation, VTS)以及开放词汇视频分割(Open-Vocabulary Video Segmentation, OVVS)。我们系统分析了该领域从传统手工特征到现代深度学习范式的发展过程——涵盖了从全卷积网络到最新的基于Transformer的架构,并评估了它们在建模局部与全局时序上下文方面的有效性。此外,我们还深入探讨了该领域所面临的技术挑战,包括时序一致性的保持以及复杂场景动态的处理等,并对构建当前基准测试标准所依赖的数据集与评估指标进行了全面的对比分析。通过提炼当前先进方法的关键贡献与不足,本综述进一步指出了该领域的新兴趋势与潜在研究方向,有望在实际应用中进一步提升VSP方法的鲁棒性与适应性。 关键词—视频场景解析,视频分割,视频跟踪,开放词汇,深度学习
1 引言
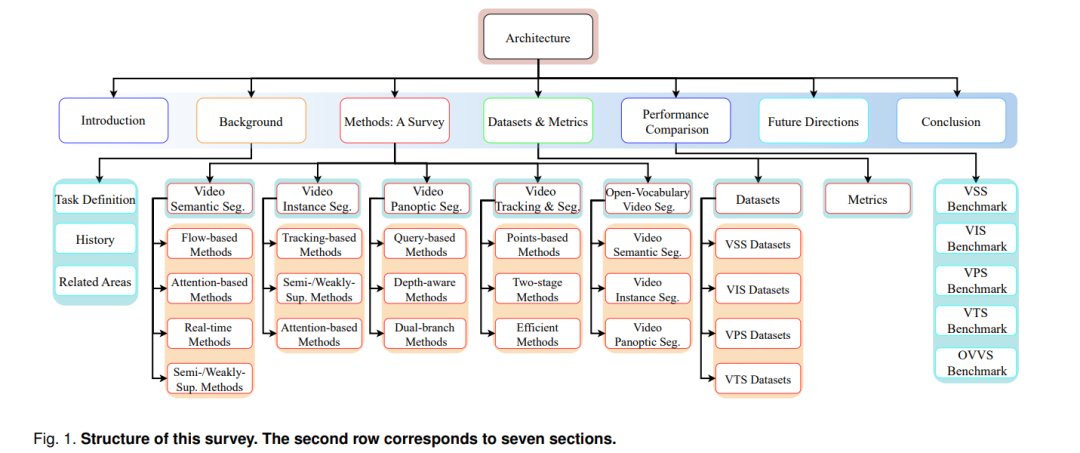
视频场景解析(Video Scene Parsing, VSP)是计算机视觉中的一个基础性问题,旨在为视频序列中的每一个像素分配语义标签。它包含了一系列关键任务,如视频语义分割(Video Semantic Segmentation, VSS)、视频实例分割(Video Instance Segmentation, VIS)以及视频全景分割(Video Panoptic Segmentation, VPS)。VSP架起了静态图像分析[^1]与动态场景理解[^2]之间的桥梁,在学术研究与工业应用中都发挥着至关重要的作用。 在学术层面,VSP带来了诸多挑战,例如跨帧保持时序一致性[^3]–[^5]、高效提取时空特征[^6], [^7],以及在复杂环境中准确跟踪动态目标[^8]。解决这些挑战不仅推动了计算机视觉理论基础的发展,也促进了模式识别与机器学习等相关领域的技术创新。 在工业层面,VSP支撑着广泛的重要应用,包括自动驾驶、智能监控、机器人系统以及视频编辑等。理解与解析动态视觉场景的能力对于提升决策过程与实现真实世界中的稳健性能具有关键意义。 回顾历史,VSP早期的研究主要依赖于手工设计的特征,例如颜色直方图、纹理描述符与光流[^9]–[^11],以及传统的机器学习模型,如聚类方法[^12]、图模型方法[^13]、支持向量机(SVM)[^14]、随机森林[^15],以及马尔可夫随机场与条件随机场等概率图模型[^16], [^17]。尽管这些基础性技术为该领域奠定了重要基础,但它们在处理复杂视频数据时的可扩展性有限,且过于依赖领域知识的特征工程。 深度学习的兴起,尤其是全卷积网络(Fully Convolutional Networks, FCNs)[^1], [^18]–[^20],标志着VSP领域范式的重大转变。FCNs 能够学习层级化的特征表示,并进行像素级标签预测,显著提升了VSP任务的准确性与效率。在过去十年中,基于FCN的方法[^21]–[^25]已成为主流,建立了新的基准并展现出在各种VSP场景中的广泛适应性。 在深度学习的基础上,Transformer架构[^26]的兴起进一步革新了计算机视觉的格局[^27]–[^35]。Transformer最初是为自然语言处理(NLP)设计的[^26],其引入的自注意力机制在捕捉长距离依赖关系与上下文建模方面表现出色。受其在NLP中的成功启发,视觉Transformer(如ViT[^36]、DETR[^37])被引入视觉任务,重塑了图像与视频分割的技术前沿。这类基于Transformer的模型通过自注意力机制在空间与时间维度上建模全局交互,突破了传统卷积神经网络(CNN)在感受野方面的局限,为VSP带来了新的发展机遇。 随着这些技术的推进,VSP的研究范围也不断扩展,涵盖了更为复杂的任务。例如,视频跟踪与分割(Video Tracking & Segmentation, VTS)作为关键的拓展方向,其目标不仅是对目标进行分割,还要在跨帧过程中保持目标身份的一致性[^38], [^39]。该任务对目标关联策略的鲁棒性提出了更高要求,同时还需应对遮挡、剧烈运动变化与复杂交互等问题,在拥挤场景下的多目标跟踪与高级视频编辑等应用中不可或缺。 另一个新兴方向是开放词汇视频分割(Open-Vocabulary Video Segmentation, OVVS),其结合了CLIP模型[^40],突破了VSS中固定标签集合的限制。通过多模态学习与自然语言引导,这类方法[^41]–[^45]能够实现超越预定义类别的目标分割,从而适应真实视频中丰富多样的物体类别。这种范式的转变对于动态环境中的泛化与零样本识别尤为关键,尤其在面对新颖或稀有物体时,模型需具备更强的适应能力。 鉴于上述技术进展,本文对VSP的多方面发展进行了系统梳理。有别于现有综述文献仅聚焦某一子领域或特定方法,我们的工作在卷积方法与Transformer方法之间建立桥梁,采用统一视角全面覆盖VSS、VIS、VPS、VTS与OVVS等任务。已有综述如[^46]主要聚焦于视频目标分割(Video Object Segmentation, VOS),在语义分割、实例分割与全景分割方面覆盖有限,难以满足对VSP的整体性理解;另一些工作如[^47]则侧重于Transformer架构,常忽略卷积方法在本领域中的基础地位。针对这些不足,我们在本综述中不仅整合了VSP方法的全貌,也对卷积与Transformer技术的发展路径进行了批判性分析。 通过同时关注如时序一致性与动态场景理解等长期挑战,以及如跟踪、分割与开放词汇识别等新兴需求,本综述全面总结了当前VSP领域的研究现状,并为未来研究方向奠定基础。这些多任务的融合反映了VSP向更全面的动态环境理解自然演进的趋势,最终推动关键应用场景中的创新发展。