

大型语言模型(LLMs)是一类特殊的预训练语言模型,它们是通过扩大模型规模、预训练语料库和计算能力来获得的。由于LLMs的庞大规模和在大量文本数据上的预训练,它们展现出特殊的能力,使得在许多自然语言处理任务中,无需任何任务特定训练即可取得显著的性能。LLMs的时代始于OpenAI的GPT-3模型,而在像ChatGPT和GPT4这样的模型的引入后,LLMs的受欢迎程度呈指数级增长。我们将GPT-3及其后续的OpenAI模型(包括ChatGPT和GPT4)称为GPT-3系列大型语言模型(GLLMs)。随着GLLMs在研究界的日益受欢迎,有强烈的需求进行一项全面的概述,总结多个维度的最近研究进展,并为研究社区提供有见地的未来研究方向。我们从基础概念如Transformer、迁移学习、自监督学习、预训练语言模型和大型语言模型开始这篇综述论文。接下来,我们简要概述了GLLMs,并讨论了GLLMs在各种下游任务、特定领域和多种语言中的表现。我们还讨论了GLLMs的数据标注和数据增强能力、GLLMs的鲁棒性、GLLMs作为评估者的有效性,并最终总结了多个有见地的未来研究方向。总之,这篇全面的综述论文将为学术界和工业界的人们提供一个很好的资源,以了解与GPT-3系列大型语言模型相关的最新研究。
大型语言模型(LLMs),是最近人工智能领域的热门话题,凭借其在大多数自然语言处理(NLP)任务中的卓越性能,在学术界和工业界都引起了广泛关注。这些模型本质上是深度学习模型,特别是基于变换器的模型,它们先在大量的文本数据上进行预训练,然后使用元训练根据人类的偏好进行对齐。预训练为模型提供了通用的语言知识[1],而元训练使模型能够根据用户的意图进行操作。这里的用户意图既包括显式意图,如遵循指示,也包括隐式意图,如保持真实性、避免偏见、毒性或任何有害的行为[2]。大型语言模型(LLMs)是通过扩大模型规模、预训练语料库和计算能力获得的预训练语言模型的特殊类别。对于下游任务使用,预训练语言模型利用了有监督的学习范例,这涉及任务特定的微调和数百或数千个标记实例[1],[3]。LLMs利用了上下文学习(ICL),这是一个新的学习范式,不需要任务特定的微调和大量的标记实例[4]。LLMs将任何NLP任务视为条件文本生成问题,并只通过根据输入提示生成所需的文本输出,该提示包括任务描述、测试输入以及可选的几个示例。图1显示了从机器学习到大型语言模型的人工智能演变过程。
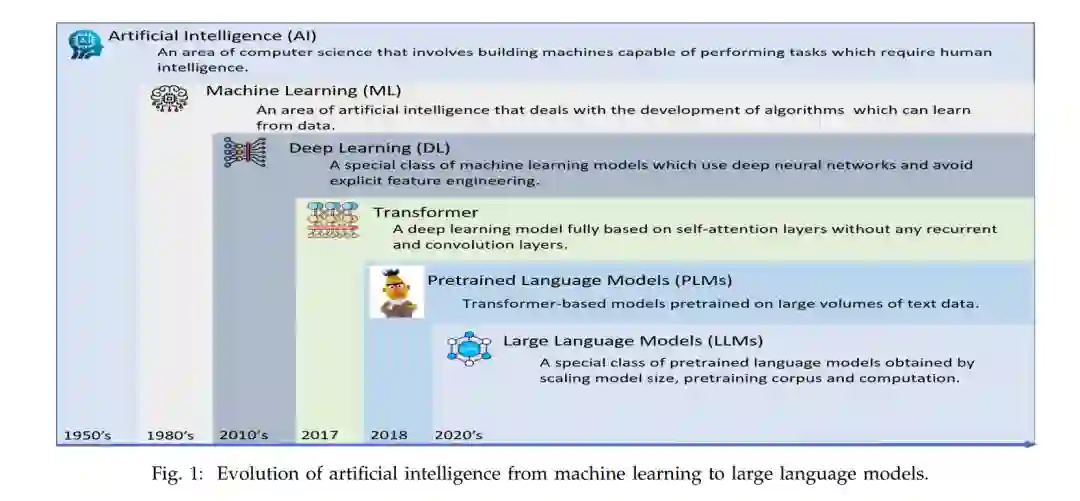
最初,NLP系统主要是基于规则的。这些基于规则的模型是建立在领域专家制定的规则之上的。由于手动制定规则是一个费时、昂贵的过程,且还需要频繁的更改,基于规则的模型逐渐被机器模型所取代,这些机器模型从训练数据中自动学习规则,完全避免手动规则制定[1]。然而,机器学习模型需要领域专家进行特征工程的人工干预。随着像Word2Vec[5]、Glove[6]、FastText[7]这样的密集文本向量表示模型的演变,以及像GPUs这样的计算机硬件的进步,NLP系统使用传统的深度学习模型构建,如CNN[8]、RNN[9]、LSTM[10]、GRU[11]、Seq2Seq[12]和基于注意力的Seq2Seq模型[13],[14]。然而,这些模型的缺点,如(i)捕获长期依赖性的能力和(ii)由于序列处理(CNN的情况除外)无法充分利用GPUs,导致了像Transformers[15]这样的高级深度学习模型的演变,它们完全基于注意力,没有任何循环和卷积层。 受到基于转移学习和大型卷积模型上的图像预训练模型[16]-[18]的成功启发,研究界开始关注构建如BERT[19]和GPT-1[20]这样的预训练语言模型(PLMs),这些模型以变换器为骨架,并基于称为自监督学习[1]、[21]、[22]的新学习范式进行预训练。与传统的深度学习模型和基础变换器模型不同,后者需要从头开始训练以供下游使用,预训练语言模型可以通过微调轻松地适应下游任务。BERT和GPT-1模型的巨大成功引发了其他预训练语言模型的开发,如RoBERTa、XLNet[23]、ELECTRA[24]、ALBERT[25]、DeBERTa[26]、[27]、GPT-2[28]、T5[29]、BART[30]等。 尽管PLMs与传统的深度学习和基础变换器模型相比有许多优势,但它们仍然存在如无法在没有任务特定训练的情况下泛化到未见任务的缺陷。因此,研究界专注于开发更先进的模型,如大型语言模型,这些模型可以在没有任何任务特定训练的情况下泛化到未见任务。LLMs的时代始于GPT-3[4],GPT-3的成功启发了其他LLMs的开发,如PaLM[31]、Chinchilla[32]、GLaM[33]、LaMDA[34]、Gopher[35]、Megatron-Turing NLG[36][181]、BLOOM[37]、Galactica[38]、OPT[39]、LLaMA[40]、[41]等。在Open AI的模型如ChatGPT和GPT-4[42]最近发布后,LLMs的受欢迎程度呈指数级增长。例如,ChatGPT在发布后的几周内就吸引了数百万用户。由于基于任务描述和几个示例泛化到未见任务的能力,而不需要任何任务特定的训练,就像人类一样,LLMs可以被视为朝向人工普遍智能[43]的一个初步步骤。在这篇综述论文中,我们主要关注Open AI的LLMs,如GPT-3模型、GPT-3.5模型(InstructGPT、ChatGPT等)和GPT-4,我们称之为GPT-3系列大型语言模型(GLLMs)。这篇综述论文提供了与GLLMs相关的多维度研究工作的全面回顾。 本综述论文的主要贡献是: • 首个在多个维度对GPT-3系列大型语言模型(GLLMs)进行全面回顾的综述论文,涵盖超过350篇最近的研究论文。 • 我们讨论了各种基础概念,如变换器、转移学习、自监督学习、预训练语言模型和大型语言模型。 • 我们详细讨论了GPT-3系列大型语言模型,从GPT-3开始,到最新的ChatGPT和GPT-4。 • 我们讨论了GLLMs在各种下游任务中的表现,并对GLLMs的数据标记和数据增强能力进行了深入的讨论。 •我们讨论了GLLMs的鲁棒性和评估能力。 • 我们提出了多个有深度的未来研究方向,这将指导研究界进一步提高GLLMs的性能。 与现有综述的比较。现有的综述论文提供了对大型语言模型[44]及其相关概念如上下文学习[45]、评估[46]、[47]、与人类价值观的对齐[48]、[49]、安全性和可靠性[50]、推理[51]、挑战和应用[52]、LLM压缩[53]以及多模态LLMs[54]的回顾。例如,赵等人[44]是首先对大型语言模型提供全面回顾的。与赵等人[44]不同,其他现有的综述论文专注于LLMs的特定概念。例如,由董等人[45]、张等人[46]、王等人[48]和黄等人[51]撰写的综述论文分别专注于LLMs的情境学习、LLMs的评估、与人类价值观的LLMs对齐和LLMs的推理能力。同样,尹等人[54]和桓等人[50]所写的综述论文分别回顾了多模态LLMs和LLMs的安全性和可靠性。然而,目前还没有一篇综述论文提供了对GPT-3系列大型语言模型的全面综述。随着GPT-3系列大型语言模型,如GPT-3、InstructGPT、ChatGPT、GPT-4等的日益增长的受欢迎程度,以及大量使用这些模型的研究工作,迫切需要一篇专门针对GPT-3系列大型语言模型的综述论文。 综述论文的组织结构如下:第2节简要概述了各种基础概念,如变换器、转移学习、自监督学习、预训练语言模型和大型语言模型。第3节详细介绍了GPT-3系列大型语言模型,从GPT-3开始,到最新的ChatGPT和GPT-4。第4、5和6节分别讨论了GLLMs在各种下游任务、特定领域和多语言场景中的表现。第7节介绍了GLLMs的数据标记和数据增强能力。第8节讨论了各种研究工作,提出了检测GLLMs生成的文本的方法。第9和10节分别讨论了GLLMs的鲁棒性和评估能力。第11节提出了多个有洞察力的未来研究方向。
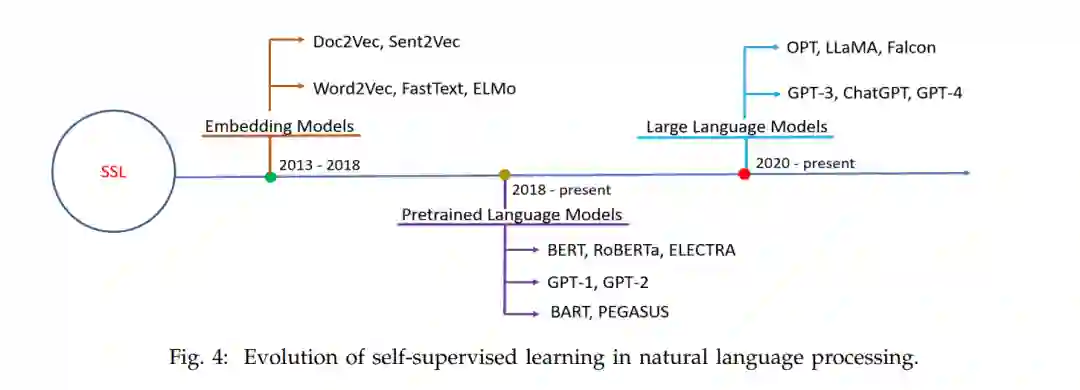
从GPT1 [20]、BERT [19] 模型到最新的DeBERTa [26]、[27],预训练语言模型取得了显著的进步,并且还减少了训练任务特定模型所需的标记数据量 [1]、[3]。预训练语言模型遵循“先预训练,然后微调”的范式,即模型首先进行预训练,然后通过微调适应下游任务。由于任务特定的微调是强制性的,以适应预训练语言模型到下游任务,预训练语言模型不能在没有任务特定微调的情况下泛化到未见过的下游任务。此外,任务特定的微调需要标记数据,并为每一个下游NLP任务创建一个预训练语言模型的独立副本,这增加了模型开发和部署的成本 [1]。预训练语言模型被视为狭义的AI系统,因为它们通过微调进行适应,然后用于特定的下游任务。但是,研究界的主要关注点是开发不局限于特定任务,而是具有通用问题解决能力,并且像人类一样利用现有知识处理甚至未见过的任务的人工普适智能系统 [43]、[100]。NLP研究者观察到,预训练语言模型的性能可以通过在三个维度上的扩展进一步提高:预训练计算、预训练数据和模型大小 [28]、[29]、[71]。大尺寸使模型能够捕捉更多的细微语言模式,从而增强它们理解和生成文本的能力,而大量的预训练数据帮助模型从更广泛的文本中学习。扩展的有 promising 成果以及建立人工普适智能系统的追求促使NLP研究者构建更大更大的模型,最终导致GPT-3及其后续模型的演化 [4]、[31]–[33]。像迁移学习和自监督学习这样的学习范式使得大型语言模型成为可能,但是扩展使这些模型变得强大。研究界为GPT-3及其后续大型模型创造了一个新的短语,“大型语言模型”,以区分这些模型与小的预训练语言模型 [44]。大型语言模型 (LLMs) 是通过扩展模型大小、预训练语料库和计算获得的预训练语言模型的一个特殊类别,如图6所示。大型语言模型 (LLMs) 本质上是深度学习模型,特别是基于transformer的模型,在大量的文本数据上进行预训练,并使用元训练与人类偏好进行对齐。预训练为模型提供了通用的语言知识 [1],而元训练则使模型根据用户的意图行事。在这里,用户的意图包括明确的意图,如遵循指示,以及隐含的意图,如维护真实性和避免偏见、毒性或有害行为 [2]。
由于它们的大尺寸和在大量文本数据上的预训练,LLMs展现出称为“新兴能力”[101]、[102]的特殊能力,使它们在许多自然语言处理任务中无需任务特定训练即可取得卓越的性能。对于下游任务使用,预训练语言模型利用有监督的学习范式,其中涉及任务特定的微调和数百或数千的标签实例[1]、[3]。LLMs利用上下文学习(ICL),这是一种新的学习范式,不需要任务特定的微调和许多标记实例[4]、[45]。LLMs将任何NLP任务视为条件文本生成问题,并通过条件化输入提示生成期望的文本输出,包括任务描述、测试输入和可选的一些示例。
大型语言模型的演变沿着两个维度发展:闭源LLMs和开源LLMs。LLMs的时代大约从GPT-3开始。在GPT-3取得成功后,Open AI开发了InstructGPT [2]、Codex [103]、ChatGPT和GPT-4 [42]等后续模型。Google引入了GLaM [33]、PaLM [31]、PaLM2 [68]、LaMDA [34]和Bard等模型。DeepMind开发了Gopher [35]、Chinchilla [32]、AlphaCode [104]和Sparrow [105]等模型。像Baidu、AI21 labs和Amazon这样的公司分别开发了Ernie 3.0 Titan [106]、Jurassic-1 [107]和AlexaTM [108]等模型。尽管闭源LLMs的性能令人印象深刻,但这些模型的主要缺点是它们处于付费墙后面,即它们的权重不公开提供,其中一些模型只能通过各自公司提供的APIs访问,并且根据处理和生成的令牌收费。
为了解决这个问题,研究界专注于开发具有公开可用权重的开源LLMs。一些受欢迎的开源LLMs是OPT [39]、OPT-IML [109]、Galactica [38]、LLaMA [40]、LLaMA2 [41]和Falcon。这些开源LLMs的性能与闭源LLMs相当。此外,在某些情况下,开源LLMs的性能超过了闭源LLMs。例如,Galactica击败了像GPT-3、Chinchilla和PaLM这样的闭源LLMs。受到英语开源LLMs成功的启发,研究界专注于开发多语言和双语LLMs。BLOOM [37]和BLOOMZ [110]是多语言LLMs的例子,JAIS [111](英语和阿拉伯语)、GLM [112](英语和中文)和FLM-101B [113](英语和中文)是双语LLMs的例子。
闭源和开源LLMs在通用领域的成功引发了域特定LLMs的开发,如金融领域的FinGPT [114]和BloombergGPT [115],医疗领域的MedPaLM [116]和MedPaLM2 [117],以及编码领域的StarCoder [118]、CodeLlaMa [119]、CodeGen [120]和CodeGen2 [121]。例如,Bloomberg开发了专为金融领域设计的BloombergGPT。同样,Google根据PaLM和PaLM2模型分别为医疗领域开发了MedPaLM和MedPaLM2 LLMs。同样,HuggingFace开发了StarCoder,MetaAI开发了Code LlaMA,SalesForce为编码任务专门开发了CodeGen和CodeGen2 LLMs。
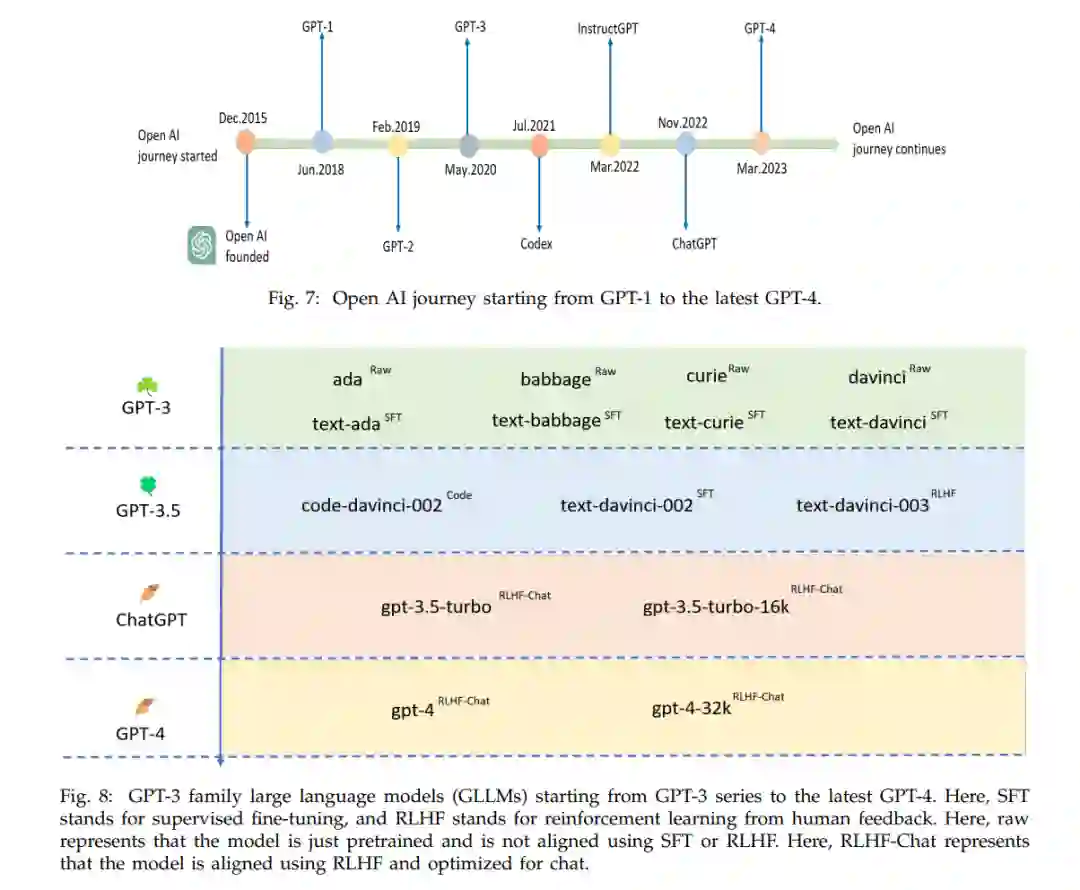
Open AI, 一个于2015年成立的AI公司,专注于建立生成模型。Open AI的研究人员最初探索了RNN来开发生成语言模型 [122]。受到transformer模型巨大成功的启发,以及其捕捉长期依赖关系的能力,Open AI研究人员利用transformer解码器构建了GPT-1(117M参数),这是第一个基于transformer的预训练语言模型 [20]。GPT-1引入了一个新的范式,“预训练和微调”,有效地开发下游任务模型。原来,“预训练和微调”范式是由Dai等人 [123] 提出的,然后被Howard和Ruder [124] 探索,用于构建文本分类的语言模型。但是,与Radford等人的工作 [20] 不同,这些研究工作是基于LSTM构建语言模型的,它缺乏并行化能力,并且在捕捉长期依赖关系上有困难。Radford等人 [20] 使用casual语言建模作为一个预训练任务来预训练GPT-1模型。casual语言建模预训练任务涉及生成基于先前标记的下一个标记。GPT-1在12个NLP任务中的9个中取得了SOTA结果 [20]。受到GPT-1的成功启发,Open AI的研究人员引入了GPT-2模型,以进一步推动这些结果 [28]。GPT-2模型预训练在WebText语料库上(40B文本),这比用于预训练GPT-1模型的Books语料库要大得多。作者开发了四个参数不同的GPT-2模型版本:117M、345M、762M和1.5B。作者观察到,随着模型大小的增加,困惑度减少,甚至对于最大的1.5B版本,困惑度的减少也没有显示出饱和。这表明GPT-2未能适应预训练数据集,延长训练时间可能会进一步降低困惑度。这一观察触发了这样的洞见:“开发更大的语言模型将进一步降低困惑度并增强自然语言理解和生成能力”。从GPT-1和GPT-2模型中获得的洞见为GPT-3家族大型语言模型的演化奠定了坚实的基础,包括最新的模型,如ChatGPT和GPT-4。图7显示了从GPT-1到最新的GPT-4的Open AI的发展历程,图8显示了从GPT-3系列到最新的GPT-4的GPT-3家族大型语言模型。
在这篇综述论文中,我们从多个维度对GPT-3系列的大型语言模型进行了全面的回顾,涵盖了超过350篇近期的研究论文。在这里,我们介绍了基础概念,GPT-3系列的大型语言模型,并讨论了这些模型在各种下游任务、特定领域和多种语言中的表现。我们还讨论了GLLMs的数据标注、数据增强和数据生成能力,GLLMs的鲁棒性,GLLMs作为评估者的有效性,并最终得出了多个有洞察力的未来研究方向。总的来说,这篇关于GPT-3系列大型语言模型的全面综述论文将为学术界和工业界的人们提供一个很好的资源,以便了解最新的研究进展。



