
大型语言模型(LLMs)是在大量文本上训练的深度学习算法,学习了数十亿个单词之间的数学关系(也称为“参数”)。它们已经为我们大多数人所熟知,作为像OpenAI的ChatGPT和用于Google的Bard这样的聊天机器人的算法基础。如今的最大模型拥有数千亿个参数,训练成本也达到数十亿美元。 尽管大规模的通用模型如ChatGPT可以帮助用户处理从电子邮件到诗歌的各种任务,但专注于特定知识领域可以使模型更小且更易访问。例如,经过精心训练的高质量医学知识的LLMs可能有助于民主化获取循证信息,以帮助指导临床决策。
已经有许多努力试图利用和改进LLMs在医学知识和推理能力方面,但迄今为止,产生的AI要么是闭源的(例如MedPaLM和GPT-4),要么在规模上受限,约为130亿参数,这限制了它们的访问或能力。 为了改善访问和表现,洛桑联邦理工学院计算机与通信科学学院的研究人员开发了MEDITRON 7B和70B,一对分别具有7亿和70亿参数的开源LLM,适应于医学领域,并在他们的预印本MEDITRON-70B: Scaling Medical Pretraining for Large Language Models中进行了描述。
MEDITRON是在Meta发布的开源Llama-2模型的基础上,持续融入临床医生和生物学家的输入而训练的。MEDITRON使用了精心策划的高质量医学数据源进行训练,包括来自像PubMed这样的开放获取仓库的同行评审医学文献,以及覆盖多个国家、地区、医院和国际组织的独特的临床实践指南集。

大型语言模型(LLMs)可能有助于实现医学知识的民主化。虽然已经做出了许多努力来利用和提高LLMs在医学知识和推理能力方面的表现,但结果模型要么是封闭源代码的(例如,PaLM、GPT-4),要么在规模上有限(≤ 13B参数),这限制了它们的能力。在这项工作中,我们通过发布MEDITRON来改善对大规模医学LLMs的访问:一套适应医学领域的开源LLMs,拥有7B和70B参数。MEDITRON基于Llama-2构建(通过我们对Nvidia的Megatron-LM分布式训练器的调整),并在综合策划的医学语料库上扩展预训练,包括精选的PubMed文章、摘要和国际认可的医学指南。使用四个主要医学基准进行的评估显示,在任务特定微调前后均取得了显著的性能提升,超过了几个最先进的基线。总体而言,MEDITRON在其参数类别中的最佳公开基线上实现了6%的绝对性能提升,以及在我们从Llama-2微调的最强基线上实现了3%的提升。与封闭源代码LLMs相比,MEDITRON-70B超过了GPT-3.5和Med-PaLM,并且与GPT-4相差5%,与Med-PaLM-2相差10%。我们发布了策划医学预训练语料库和MEDITRON模型权重的代码,以推动更有能力的医学LLMs的开源开发。 https://www.zhuanzhi.ai/paper/3a80007a9ee77b1b5c116259d8506624
医学深深植根于知识中,回顾证据是指导临床决策标准的关键。然而,虽然“循证医学”(EBM)现在已成为质量护理的同义词,但它需要的专业知识并不是普遍可得的。因此,确保公平获得标准化医学知识是医学所有领域持续的优先事项。最近在大型语言模型(LLMs)(Brown et al., 2020; Touvron et al., 2023a; Almazrouei et al., 2023; Touvron et al., 2023b; OpenAI, 2023b; Chowdhery et al., 2022)方面的进展有可能彻底改变获取医学证据的方式。如今,最大的LLMs拥有数十亿或数千亿参数(Bommasani et al., 2021; Hoffmann et al., 2022; Kaplan et al., 2020),并且在庞大的预训练语料库上进行训练(Raffel et al., 2019; Gao et al., 2020; Together AI, 2023; Soldaini et al., 2023)。这种前所未有的规模使LLMs具备了人类决策的核心特征:逐步思维推理、连贯沟通和情境解读(Bubeck et al., 2023; Wei et al., 2023; Wang et al., 2023)。
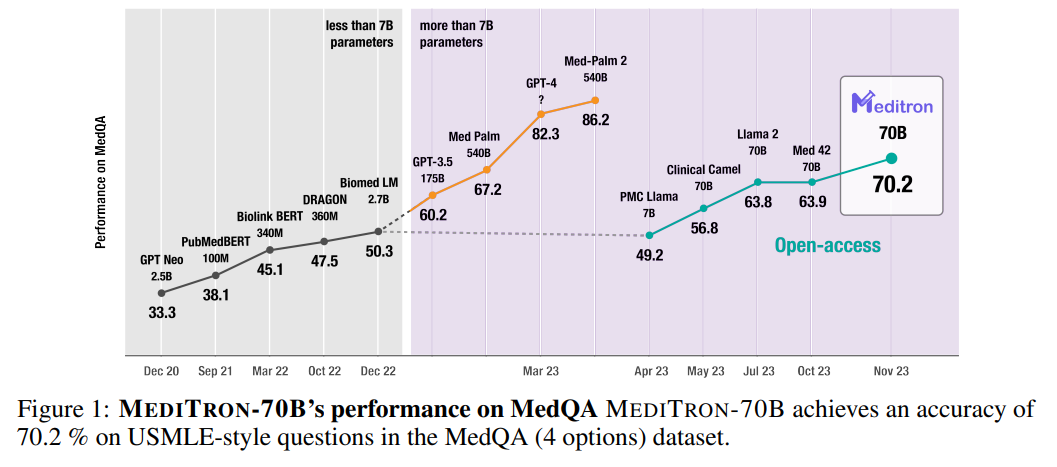
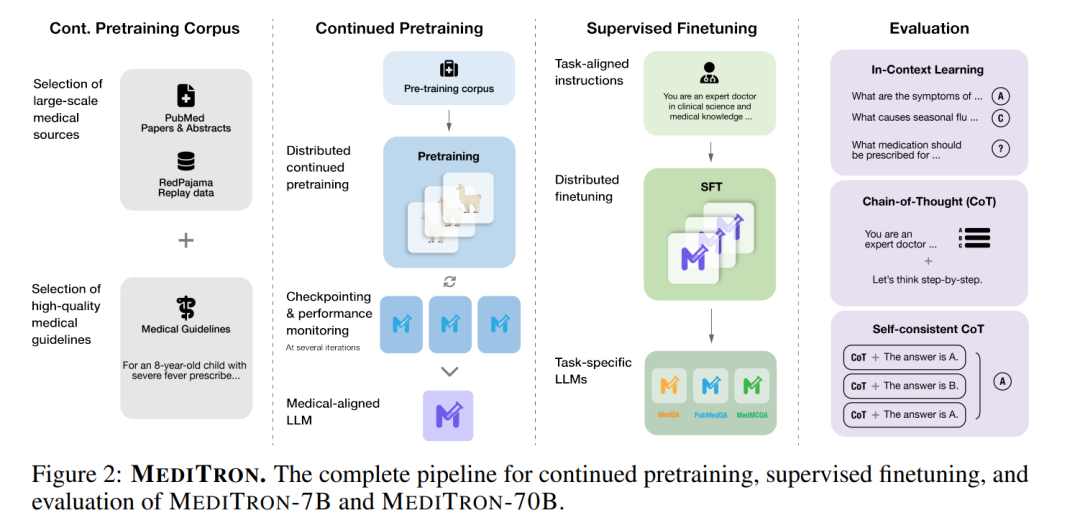
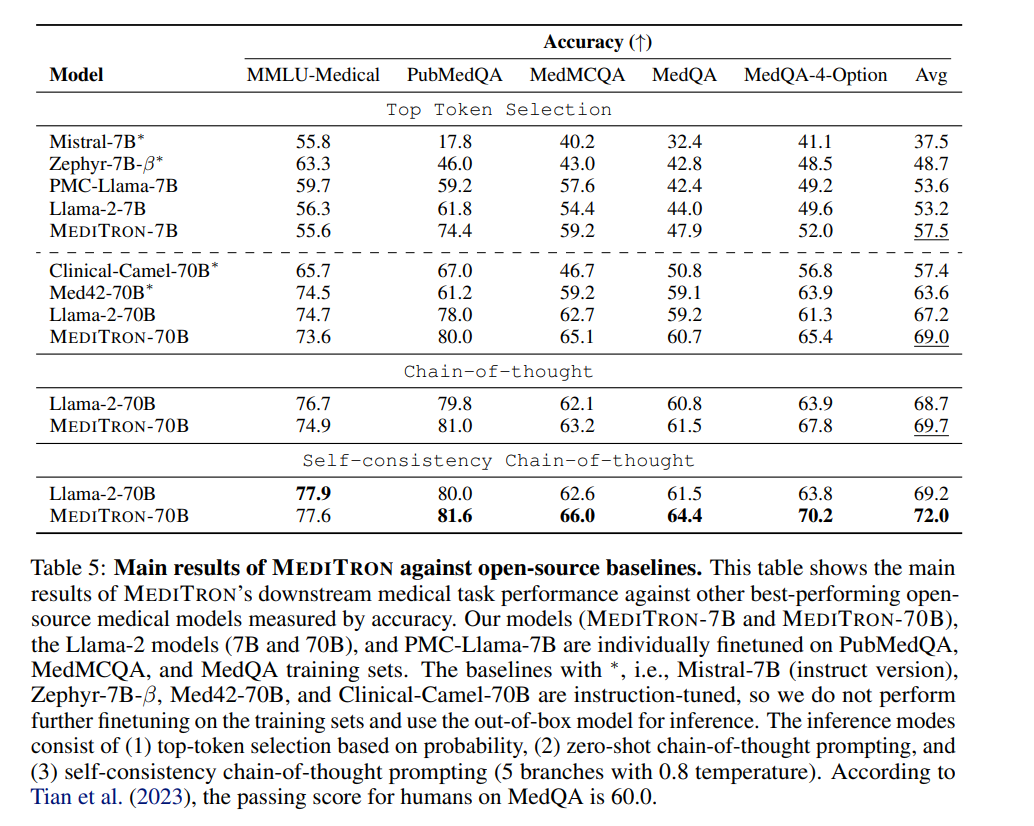
直到最近,LLMs主要针对通用任务进行开发和评估,主要使用从不同互联网来源收集的数据,这些数据在领域特定证据方面的质量各不相同(Rozière et al., 2023)。这种方法虽然通常非常强大,但会阻碍特定任务的性能,包括医学领域。一些新的特定任务模型,经过更精心策划的数据集训练,已经多次超越了通用模型(Wu et al., 2023b; Yue et al., 2023; Rozière et al., 2023; Azerbayev et al., 2023),揭示了在预训练数据方面平衡质量和数量的潜力。实现这种平衡的一个有希望的方法是使用通用LLMs,然后继续在更精选的领域特定数据上训练。这些系统获得了自然语言和领域特定语言理解及生成技能的结合(Gururangan et al., 2020)。在医学领域,这种方法仅在13B参数以下的模型中有报告(Lee et al., 2020; Gu et al., 2021; Peng et al., 2023; Wu et al., 2023a)。在更大规模(即≥70B参数)上,之前的研究仅探讨了指令调整(M42-Health)或参数高效微调(Toma et al., 2023)的范围。 在这项工作中,我们介绍了MEDITRON-7B和70B,这是一对用于医学推理的生成LLMs,由Llama-2(Touvron et al., 2023b)改编,通过在精心策划的高质量医学数据源上继续预训练:PubMed Central(PMC)和PubMed开放获取研究论文(通过S2ORC语料库收集,Lo et al., 2020),S2ORC中的PubMed摘要(来自非开放获取论文),以及从互联网收集的多种医学指南,涵盖多个国家、地区、医院和国际组织。为了支持训练,我们扩展了Nvidia的Megatron-LM分布式训练库,以支持Llama-2架构。 我们使用四个医学推理基准对MEDITRON进行评估,包括在上下文学习中(在提示期间提供示例,即在上下文窗口内)和特定任务的微调。基准包括两个医学考试题库,MedQA(来自美国医学执照考试,Jin et al., 2020)和MedMCQA(医学领域的多主题多选题数据集,Pal et al., 2022),PubMedQA(基于PubMed摘要的生物医学问答,Jin et al., 2019)和MMLU-Medical(来自大规模多任务语言理解的医学主题评估集,Hendrycks et al., 2021a)。在没有微调的情况下使用上下文学习,MEDITRON-7B超过了几个最先进的基线,显示出比PMC-Llama-7B(一种类似的LLM,由Llama改编,通过在PubMed Central论文上继续预训练,Touvron et al., 2023a)平均10%的性能提升,以及比Llama-2-7B模型平均5%的性能提升。在特定任务训练数据上微调后,MEDITRON的性能也在同等规模的其他微调基线上有所提升,达到了5%(7B)和2%(70B)的平均性能提升。最后,将MEDITRON-70B微调以支持高级提示策略,如思维链和自我一致性,进一步提高了最佳基线3%和最佳公开基线12%的性能。总的来说,MEDITRON在医学推理基准上表现强劲,在同等规模的最先进基线上匹敌或超越。
总结来说,我们提出了一种优化的工作流程,用于扩展医学LLMs的领域特定预训练,包括基于知识的数据策划、通过分布式训练管道的持续预训练、微调、少样本上下文学习,以及高级推理方法,如思维链推理和自我一致性。我们发布了策划的训练语料库、分布式训练库2和MEDITRON模型(7B和70B)3,包括经过微调和未经微调的版本,以确保公众能够进行现实世界评估,促进其他领域类似工作的发展。
医学训练数据
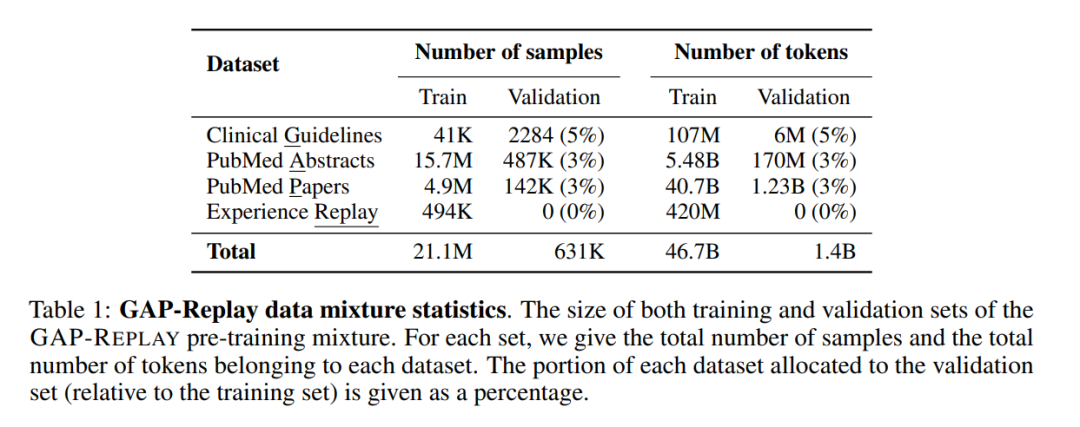
MEDITRON的领域适应性预训练语料库GAP-REPLAY结合了来自四个数据集的48.1B个词符;临床指南:来自各种医疗相关来源的46K份临床实践指南的新数据集,论文摘要:来自16.1M闭源PubMed和PubMed Central论文的公开可用摘要,医学论文:从500万份公开可用的PubMed和PubMed Central论文中提取的全文文章,以及回放数据集:一般领域数据提炼而成,占整个语料库的1%。
模型
结果
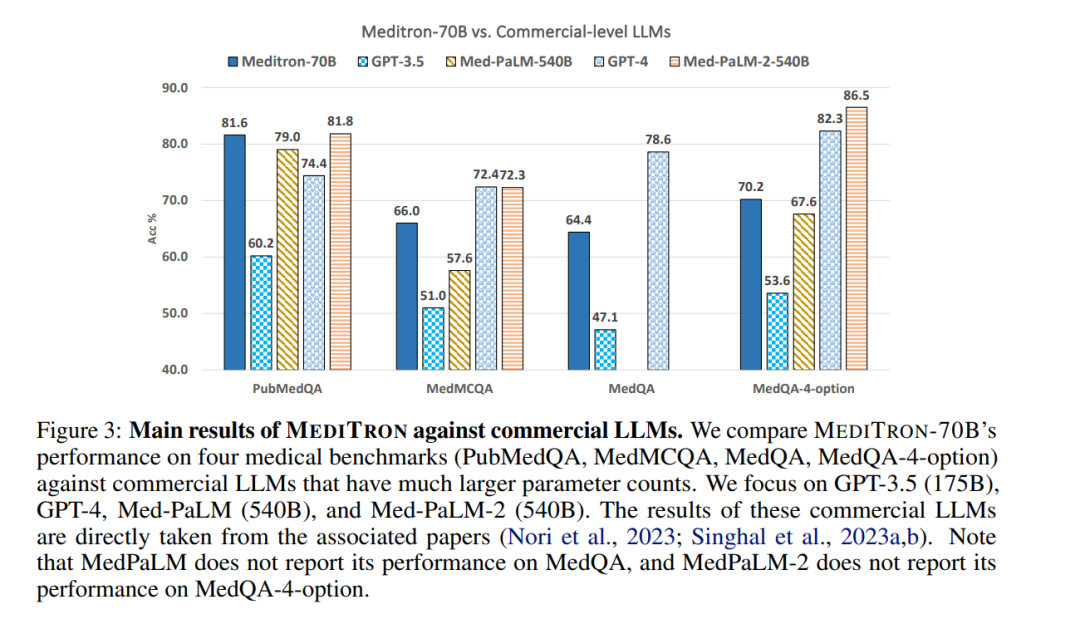
结论
我们发布了MEDITRON,一套适用于医疗领域的高级语言模型(LLM),展示出卓越的医学推理能力和改进的领域特定基准性能。通过对精心策划的高质量医疗资源进行持续预训练(包括一套新的临床指南),MEDITRON在临床推理基准上表现出比所有最先进基准规模更大8倍商业LLM 10%性能提升。值得注意的是,MEDITRON在所有医疗基准上均优于开源多功能和医疗LLM。我们将我们的模型(以7B和70B规模)、筹备训练语料库所需工具以及分布式训练库作为开放资源提供。这不仅确保了对真实世界情境下评估结果,还促使进一步微调和指导性模型发展成为可能。通过公开提供这些资源,我们旨在帮助释放共享模型潜藏于增强医学研究、改善患者护理并推动各种健康相关领域创新方面变革潜力。
