赛尔笔记 | 条件变分自编码器(CVAE)
作者:哈工大SCIR 蔡碧波
0. 背景
机器学习模型可以主要分为判别模型与生成模型,近年来随着图像生成、对话回复生成等任务的火热,深度生成模型越来越受到重视。变分自编码器(VAE)作为一种深度隐空间生成模型,在数据生成任务上与生成对抗网络(GAN)一并受到研究者的青睐。VAE(Kingma and Welling.2013)先将原始数据编码到符合特定分布的隐变量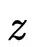
由于VAE是一种无监督模型,只能生成与输入类似的输出数据,故研究者提出条件变分自编码器CVAE(Sohn et al.,2015),将原始数据以及其对应的类别共同作为编码器的输入,可以用于指定类别的数据的生成。利用CVAE就可以生成符合特定视觉特征的图片(Yan et al.2016)。VAEs方法最初应用于CV中,在自然语言处理领域,(Bowman et al.,2015)首次利用VAE进行文本生成。(Zhao et al.,2017)将CVAE用于对话生成中,增强了生成回复的多样性。
1. 基本思想
目前有很多任务都有着one-to-many的性质。比如在图像任务中,希望能够根据给定的肤色生成不同的人脸图片;在自然语言处理任务中,给定上文,希望能够生成不同的回复等。由于这些任务中有多种变化的因素,故对相同的输入,可以有不同却均合理的结果。
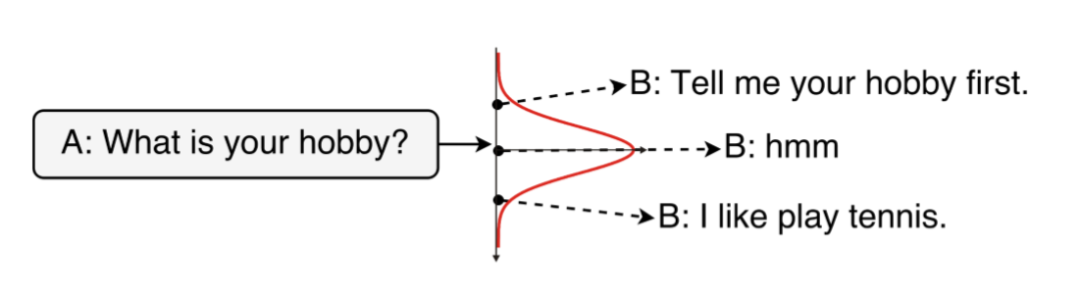
一对多问题示例
上图 (Zhao et al.,2017) 展示了一个在对话生成任务中有多种回复的例子,A同学提问“你的爱好是什么?”,由于回复的人可能有着不同的爱好,有不同的聊天习惯导致其有多种回复形式。CVAE模型作为一种深度条件生成模型,引入了隐变量z来捕捉这种一对多问题中的变化的因素。从概率图模型的角度可以将生成过程描述如下 (Kingma and Welling.2013) :
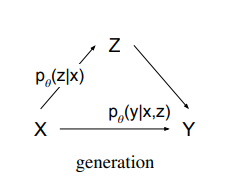
CVAE概率图模型
其将给定的上下文/肤色看作生成的条件
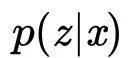
2. 模型架构与概率图架构
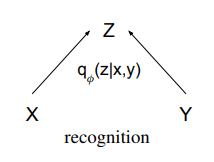
在具体介绍CVAE的数学原理前,我们先从整体的角度了解一下CVAE模型的整体架构¨对其有大体的认识。而模型的建模过程跟概率图结构是保持一致的。在对话生成任务中,CVAE模型在训练阶段和测试阶段的前馈网络框架如图所示 (Zhao et al.,2017) :

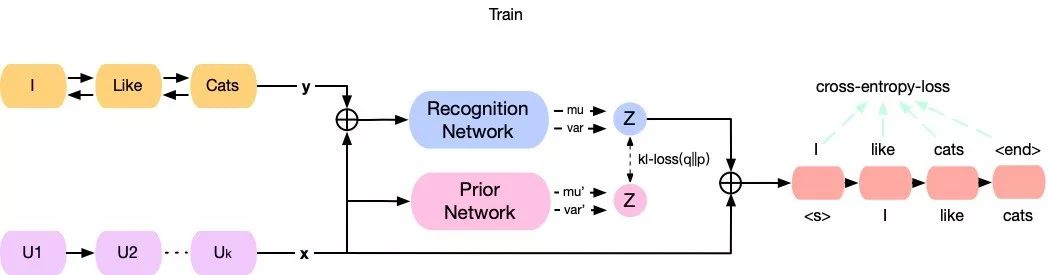
CVAE测试及训练模型图
CVAE的核心在于用神经网络对分布进行拟合。图中黄色的部分表示将回复句编码为y,紫色部分表示将输入的上下文编码为x,将隐变量z和x的拼接起来作为decoder的输入向量,生成回复的句子。隐变量z由prior/recognition net采样而来。
prior/recognition net实际上是MLP,其输出的值为分布的具体参数。如此例中假设隐变量服从的是一个高维高斯分布且其方差为对角矩阵,则MLP的输出为
和
。
所谓的采样指的是从服从
的分布中采样一个向量,由于直接采样是断微分的,故如下文所述,这里往往采取所谓的reparameterion trick,即采样由标准正态分布的变量变换而来,即
且
。
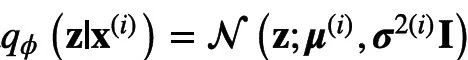 的分布中采样一个向量,
的分布中采样一个向量,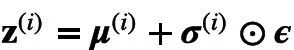 且
且 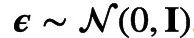 。
。实际的模型与概率图模型是一致的,前向先验概率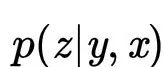
CVAE后验概率
以KL散度为优化目标可以使先验概率和后验概率尽量逼近,那么先验即可以与后验生成较为相似的隐变量。decoder端对应于概率
由于测试阶段输出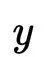
3. 数学原理
变分自编码(VAE)的方法核心其实是利用深度神经网络对概率分布进行拟合,优化目标为最大化变分下界(EOLB)。由于CVAE由VAE变化而来,而EOLB是他们共同的优化目标,所以这里从EOLB出发,先介绍VAE,再过渡到CVAE。
3.1 变分下界EOLB(evidence of lower bound)
在我们接触机器学习时,最先接触隐变量这个词是在EM算法中。变分自编码器与EM算法一脉相承。我们考虑一个概率模型,其中所有观测变量(可以理解为高维向量)联合起来记为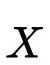
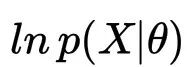
这里我们假设数据服从独立同分布假设,那么该似然函数就是每个数据点的边际似然函数的和,即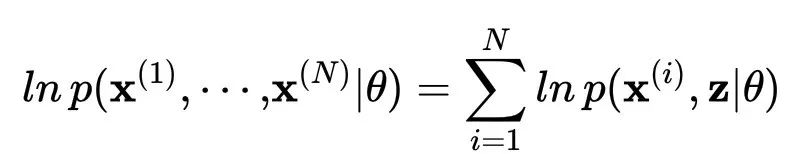
所以什么是变分下界?如果我们为每个数据点引入函数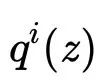
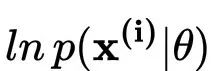
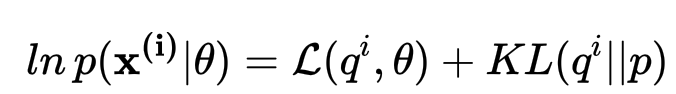
其中
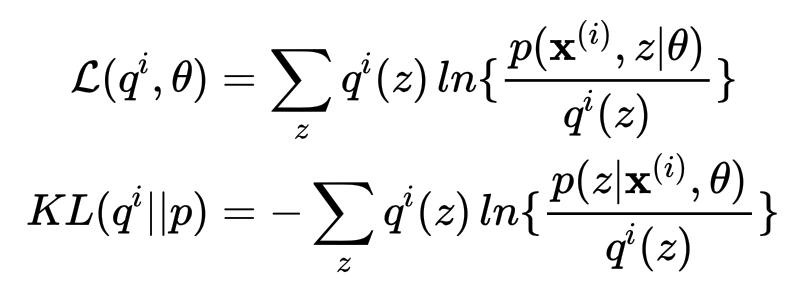
由于KL散度满足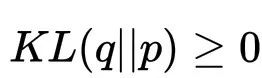
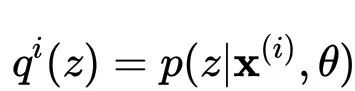
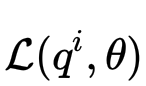
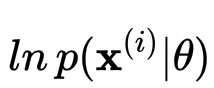
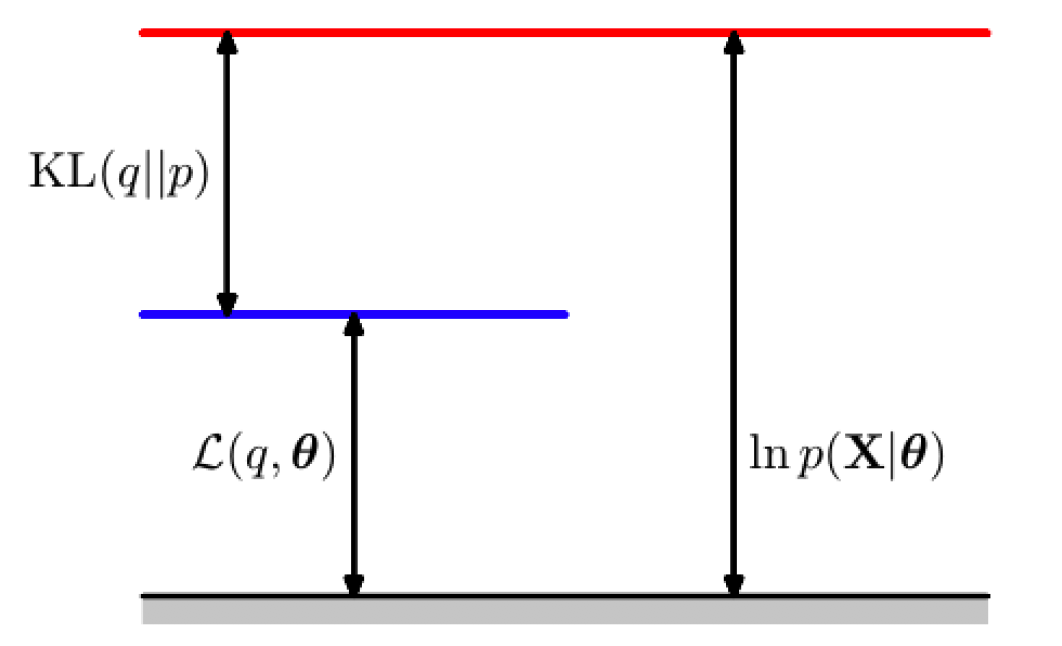
变分下界
另外也可以利用jensen不等式来构造变分下界,使用
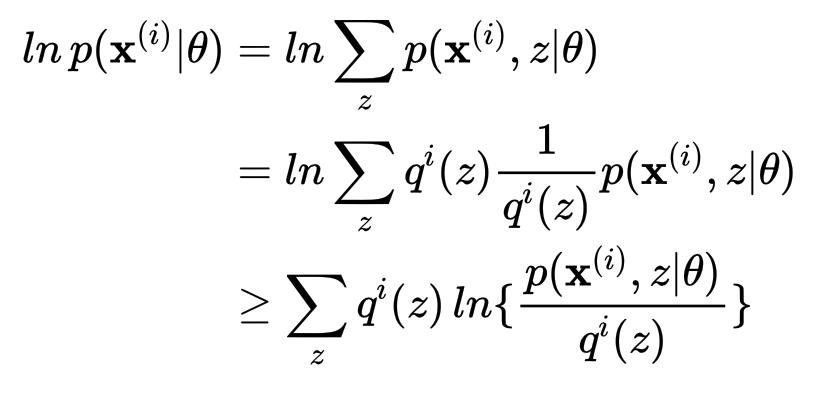
根据jenson不等式的取等条件有当且仅当
值得强调的是,变分下界是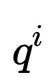
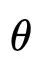
所以EM算法就是根据变分下界来进行两阶段的优化,如果后验分布可以被计算出来(如为混合高斯分布),那么即可以使用EM算法进行优化求解。
在E步,取
,此时KL散度为0。在旧
下变分下界
与
的值相等。
在M步以
为变量最大化变分下界
,由于其是一个下界,此时
必然也增大。
通过E步和M步的不断迭代,即可使得
3.2 不可计算问题与变分自编码器
上述提到,只有当后验概率是可计算的时候方可使用EM算法进行求解。但是对于实际应用中的很多模型来说,计算后验概率分布或者计算关于这个后验概率的期望是不可行的。例如在连续变量的情形中,需要求解的积分可能没有解析解,而空间维度和被积函数的复杂度较高导致数值积分不可行。如 (Kingma and Welling.2013) 的appendix C中所给的例子,分布的参数由mlp导出;对于离散变量,求边缘概率涉及到对隐变量的所有取值进行求和,但是实际应用中往往隐变量的数量为指数级,计算代价过高。
所以此时往往考虑对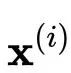
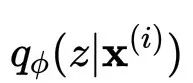
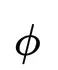
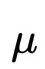
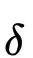
那么上述的变分下界可以写为:
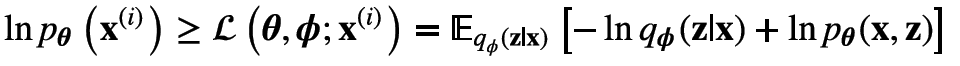
对上式稍作变换,也可以写为:
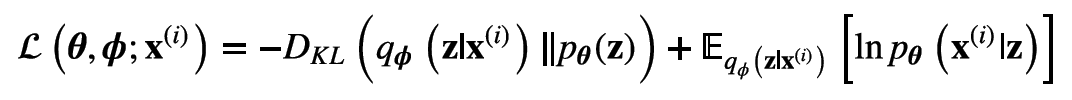
以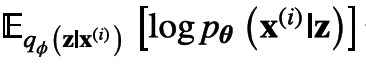
(Kingma and Welling.2013) 中提出可以reparameterization trick来解决。可以将该trick理解为一种变量代换的方法,也就是将原先的一个固定分布经过一个可导变换,变换为服从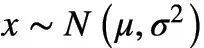
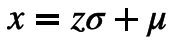
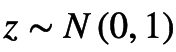
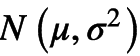
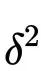
此时就可以用蒙特卡洛方法对重构误差进行估计,令为L采样的次数,那么重构误差近似于:
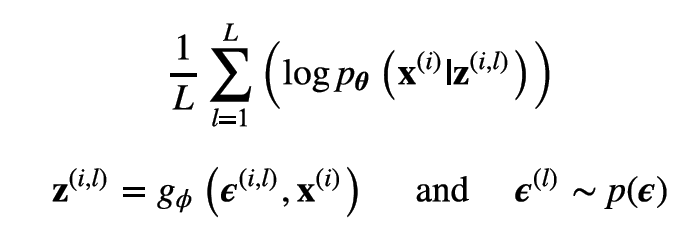
在实际实验中,数据以minibatch的方式送入模型进行训练, (Kingma and Welling.2013) 中提到,只要batch size足够大(如100),那么可以将采样的次数L设置为1,如果是分类任务,那么此时所估计的重构误差就与crossEntropyLoss无异了。
下图 (Doersch,2016) 展示了在使用reparameterization trick前后的整个变分下界的优化过程。
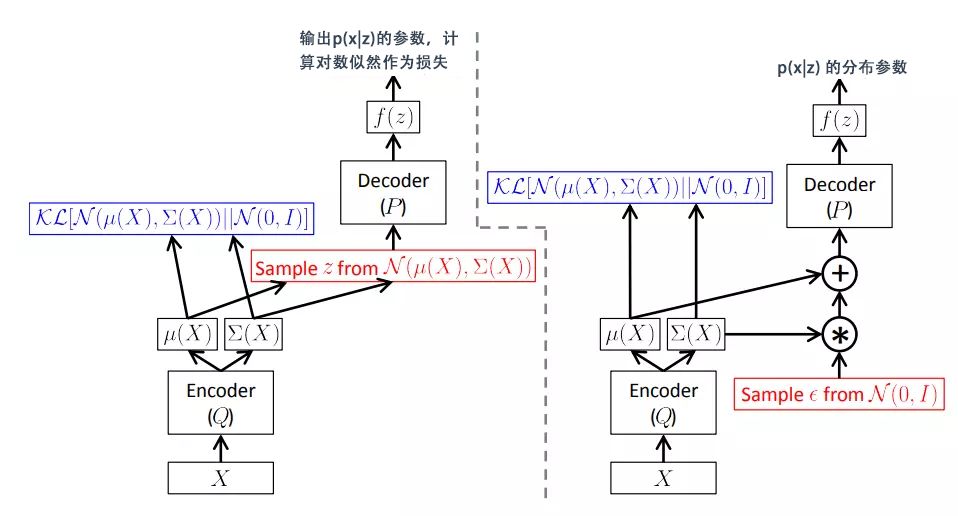
左:使用reparameterization trick前 右:使用reparameterization trick后
先验分布 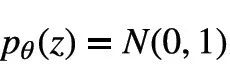
上图即是变分自编码器(VAE)的结构图。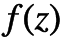
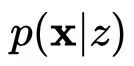
3.3 从变分自编码器到条件变分自编码器
条件变分自编码器正是变分自编码器的进阶版,但是其优化思路一脉相承。CVAE的概率图模型如图所示 (Sohn et al.,2015) 。
CVAE概率图模型
其中有三种变量,输入变量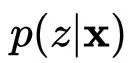
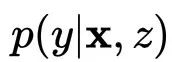
在CVAE中,我们转而对条件分布进行建模,优化的目标转为最大化条件似然。
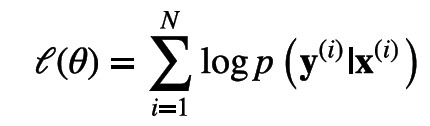
与VAE相同,对于此目标函数依然存在着后验概率不可计算问题,所以退而求其次,在一个受限的隐变量分布中使用变分方法对EOLB进行优化。下文中默认该受限的分布为一个高维高斯分布。CVAE的EOLB如下:
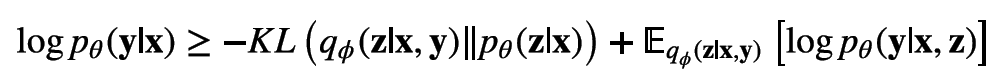
具体的推导请参考(Sohn et al.,2015)
使用蒙特卡洛的方法来计算期望,那么转为:
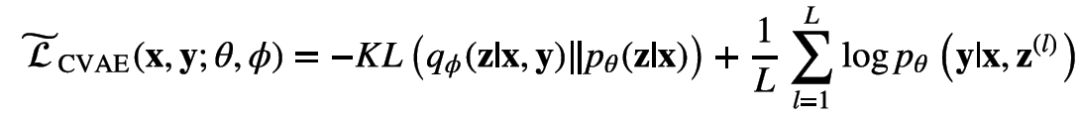
这里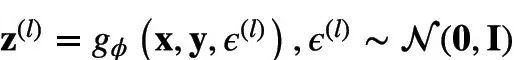
3.3.1 EOLB比较
VAE中的EOLB
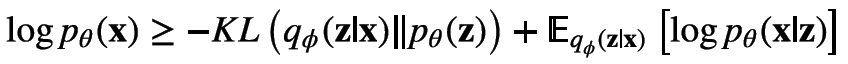
CVAE中的EOLB
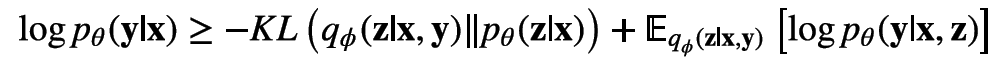
其差别主要是引入了条件x。统一来看,在EOLB中,KL散度的两项仍然分别是隐变量的先验和后验;期望部分对应的是生成网络的输出的对数似然在隐变量的后验分布上的期望。
3.3.2 模型结构图
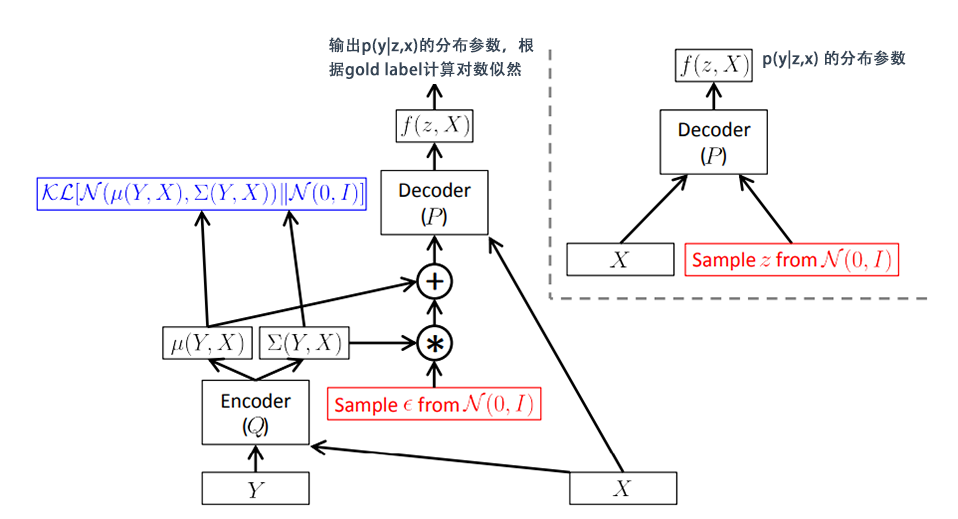
CVAE模型架构
将EOLB中的每一项在结构图中找到对应。对应关系如下:
图例中对
的先验分布
进行了松弛,将其设定为的与
独立,变为了
故KL散度中的第二项为
。请注意,并不强制假设x与z是互相独立的,如第2章中的图示,我们可以使用一个神经网络对条件先验
建模。
的后验分布
是一个多元高斯,其参数
,
由
,
经过recognition net导出。之后的reparameterization过程与VAE相同。
生成过程
即decoder部分,以
,
作为输入,输出是
的分布参数。比如回复生成任务中,decoder在每个step生成一个单词,即
符合multinomial分布,输出即词表中每个单词的概率。此时蒙特卡洛一次采样的结果与计算交叉熵损失的过程是一致的。
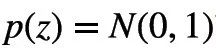
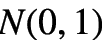 。请注意,并不强制假设x与z是互相独立的,
。请注意,并不强制假设x与z是互相独立的,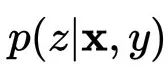 是一个多元高斯,其参数
是一个多元高斯,其参数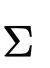 由
由4. 总结
CVAE是一个将贝叶斯推断方法与神经网络结合的很好的方法,有着优美的数学推导。由于隐变量有着良好的灵活性,便于对one-to-many的关系进行建模,在一些生成任务中得到了广泛的应用。本文对CVAE的相关数学原理及网络结构进行了总结归纳,如有不妥当之处,还望各位读者多多批评指正。
参考文献
[1] Tiancheng Zhao, Ran Zhao and Maxine Eskenazi. 2017. Learning Discourse-level Diversity for Neural Dialog Models using Conditional Variational Autoencoders. ACL.
[2] Diederik P Kingma, Max Welling. 2013. Auto-Encoding Variational Bayes. ICLR.
[3] Bishop, C. M. (2006). Pattern recognition and machine learning. Springer Science+ Business Media.
[4] Bowman, S. R., Vilnis, L., Vinyals, O., Dai, A. M., Jozefowicz, R., & Bengio, S. (2015). Generating sentences from a continuous space. arXiv preprint arXiv:1511.06349.
[5] Kihyuk Sohn, Honglak Lee, and Xinchen Yan. 2015. Learning structured output representation using deep conditional generative models. NeurIPS.
[6] Xinchen Yan, Jimei Yang, Kihyuk Sohn, Honglak Lee. 2016. Attribute2Image: Conditional Image Generation from Visual Attributes. ECCV.
[7] Sohn, K., Yan, X., & Lee, H. Supplementary Material: Learning Structured Output Representation using Deep Conditional Generative Models.
[8] Doersch, C. (2016). Tutorial on variational autoencoders. arXiv preprint arXiv:1606.05908.
本期责任编辑:张伟男
本期编辑:顾宇轩
本文转载自公众号:哈工大SCIR,作者哈工大SCIR
推荐阅读
赛尔原创 | EMNLP 2019融合行、列和时间维度信息的层次化编码模型进行面向结构化数据的文本生成
Google工业风最新论文, Youtube提出双塔结构流式模型进行大规模推荐
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





