

近年来, 以深度学习为代表的人工智能技术迅猛发展, 深度学习模型和训练数据的规模均呈 爆炸式增长, 给智能模型训练系统带来了巨大挑战. 随着高性能计算与人工智能的不断深度融合, 并 行智能训练技术成为大规模深度学习模型高效训练的主要方法. 本文总结了并行智能训练的基本模 式和关键技术, 以及并行智能训练框架的发展现状, 分析了并行智能训练技术和框架发展面临的挑战 与发展趋势, 简介了银河天璇并行智能训练框架的研究进展.
1. 引言
海量数据的获得以及智能算力的提升推动人工智能迎来第三次发展浪潮. 2006 年以来, 深度学 习技术飞速发展, 在计算机视觉、自然语言处理、科学发现等领域取得了广泛的应用. 2022 年底发 布的 ChatGPT 对话模型[1] 进一步引发了人工智能热潮. 伴随人工智能技术的快速发展, 智能模型参数规模和训练数据规模呈爆炸式增长. 2017 年, Facebook 使用 256 块 P100 GPU 在一个小时内完成了 ResNet50[3] 在 ImageNet-1K 数据集[2] 上 的训练, ResNet50 模型的参数量为 2500 万, ImageNet-1K 训练数据集包含 128 万张图像. 到 2020 年, OpenAI 使用 10000 块 V100 GPU 完成 GPT-3 模型[4] 的训练, GPT-3 模型的参数量为 1750 亿, 训练数据使用的文本语料大小为 570 GB(Gigabyte), 包含 4000 亿个单词(tokens), 训练的计算 量达到 3.14E+23 浮点运算次数(floating point operations, FLOPs), 训练时间数以月计. 可以说, 人工智能飞速发展离不开大模型、大数据、大算力的 “暴力美学”. 人工智能训练的超大规模算力需求, 使其逐渐成为一种新型的高性能计算应用, 促进了人工智能 与高性能计算的不断融合发展. 2017 年, 优步公司(Uber)的 Horovod[5] 数据并行训练框架, 通过 借鉴高性能计算中的 Ring AllReduce[6] 技术, 尝试解决传统参数服务器[141](parameter server)分 布式训练架构中参数聚合通信的可扩展性问题, 标志着人工智能和高性能计算技术融合发展的开端随着 BERT[7]、GPT[8] 等基于 Transformer[9] 的预训练语言模型的发展, 智能模型参数和训练数据规 模不断增长, 智能模型训练对算力系统的规模和计算效率提出了更高的要求。
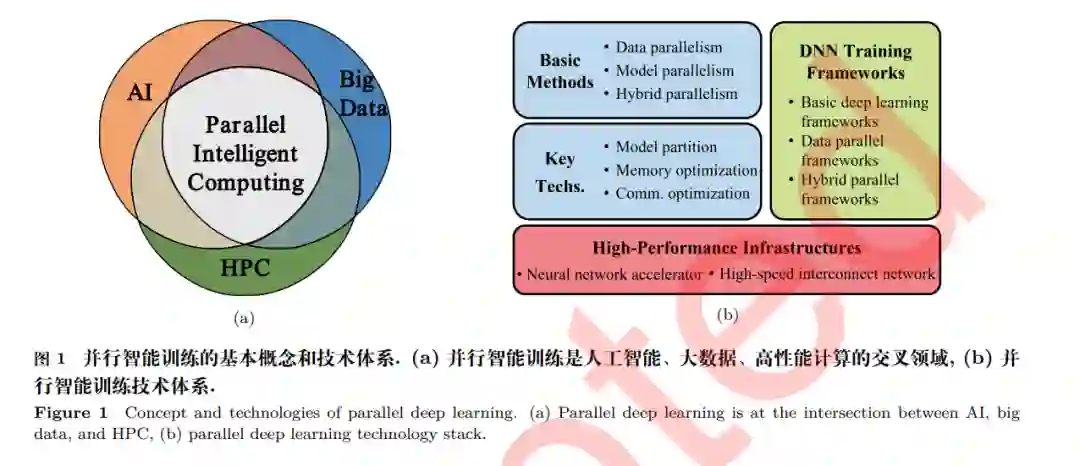
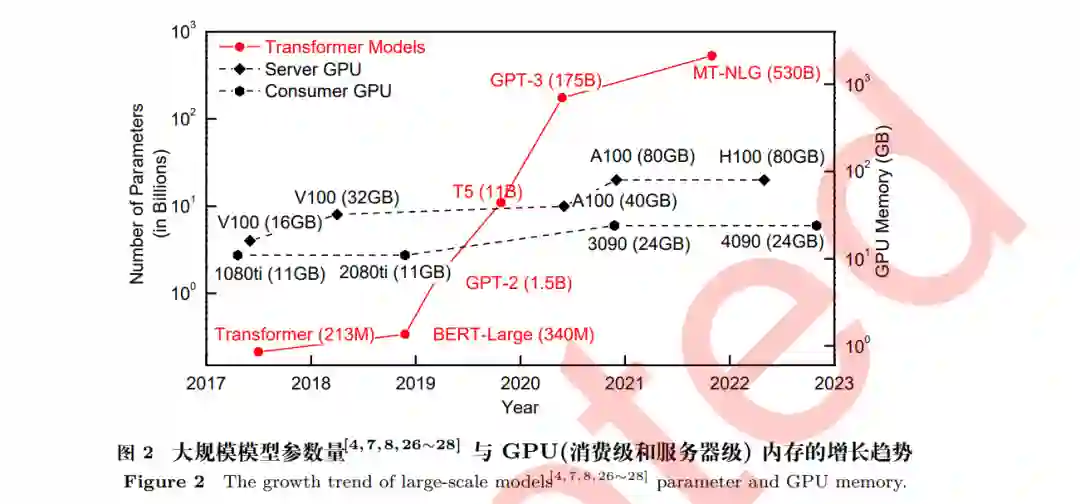
利用高性能计算系统进行并行智能训练, 是解决大规模智能模型训练问题, 提高智能模型训练计 算效率和扩展性能的有效手段. 如图 1(a) 所示, 并行智能训练是人工智能、大数据、高性能计算的 一个交叉领域. 经过多年的不断融合发展, 并行智能训练技术体系目前已初步形成. 如图 1(b) 所示, 并行智能训练在高性能并行智能训练体系结构基础上, 以并行智能训练框架为软件载体, 采用并行智 能训练基本方法和关键技术提高智能训练系统的计算效率和可扩展性, 支持大规模人工智能模型的 训练. 本文将围绕并行智能训练技术展开, 第 2 节主要介绍深度学习、智能处理器和高性能计算系统 等背景与挑战;第 3 节介绍数据并行、模型并行、混合并行等并行智能训练基本模式;第 4 节介绍 并行智能训练关键技术以及业界的最新研究进展;第 5 节总结并行智能训练技术和框架软件发展面 临的挑战问题;第 6 节概述并行智能训练技术的发展趋势;第 7 节介绍作者团队在并行智能训练框 架方面的研究成果;第 8 节为总结和展望.2. 深度学习深度学习技术 以深度神经网络为代表的人工智能技术推动着计算机视觉[3,10,11]、自动驾驶[12,13]、自然语言处 理 (natural language processing, NLP)[14∼19]、语音识别[20,21] 等智能应用的成功落地. 这些深度神 经网络通过在海量数据上训练, 在许多任务上甚至达到超过人类的水平, 产生了一系列深度学习技术 的应用实例, 例如目标检测与语义分割[22]、图片分类[11]、问答系统[23]、图像生成[24] 等. 然而, 近年来模型的参数量和训练数据量急剧增加, 大模型和大数据问题给深度学习系统的设计 和实现带来了巨大挑战, 特别是基于 Transformer 的预训练模型[4,7,8,25,26] 参数量已超过十亿 (Billion) 数量级, 而且模型规模的增长速度非常快, 如图 2 所示, 近年发布的预训练模型参数量增长了超过 1000 倍. 此外, 训练的数据量往往达到 Terabyte (TB) 数量级. 例如图片数据集 JFT-3B 包含近 30 亿张 图片[29] , 更大的 Common Crawl 网页数据集中的 token 数量达到了上千亿, 存储图像数据集 Open Image 需要 18TB[30] , 视频分析的 Youtube-8M 数据集甚至需要 1 Petabyte (PB) [31] . 典型的深度 神经网络训练步骤需要迭代进行前向计算 (forward pass, FP) 和反向传播 (backward propagation, BP) 来获得更高的准确性,而计算量与参数量和数据量呈正相关关系,巨大的参数量和训练数据量 会带来高昂的计算开销. 2012 年以来, 智能模型计算量每年增长 10 倍[4,7,8,25,26] , 增长速度超越摩尔 定律. 因此亟需高性能并行智能训练系统支撑模型开发者在海量数据上更快地训练大规模神经网络 模型[32] , 并行智能训练技术成为学术界和产业界的研究热点[5,33,34] .
**3. 智能训练处理器 **
智能模型训练过程主要包括神经网络的前向和反向计算,其中涉及大量高维矩阵运算, 通用 CPU 难以应对这类计算密集型任务, 而 GPU、FPGA 等加速芯片并行计算的特性使其被广泛用 于深度学习模型训练任务. 因此, 目前并行智能训练系统通常是异构的, 包含了 CPU 和专用硬件加 速芯片. 这种异构计算系统由 CPU 访问主存或 I/O 设备读取数据, 将数据传输给硬件加速器进行 模型训练. 以智能训练系统中广泛应用的英伟达 GPU 为例, 其配合使用 Compute Unified Device Architecture (CUDA) 套件进行矩阵加速计算, 其代表性产品 NVIDIA A100 的 Tensor Cores 可以 在面向智能训练的数据格式 Tensor Float (TF32) 上进行计算, 提供高达 312 teraFLOPS (TFLOPS) 的计算能力. 与此同时, 谷歌公司也研发了应用于大规模神经网络计算的 TPU[35] . 国内也抓住 AI 芯 片这一新的机遇进行投入, 如华为推出 Davinci 架构的 Ascend NPU 芯片、寒武纪研发 CambriconX[36]、百度发布昆仑系列芯片[37] 等. 这些专用加速芯片极大提高了神经网络训练和推理的计算速度. 除此之外, 新一代 HPC 系统中的高性能异构多核处理器, 例如国防科技大学的 MT-3000 [38],在加 速科学计算任务的同时, 也可用于智能训练和推理任务.
并行智能训练系统
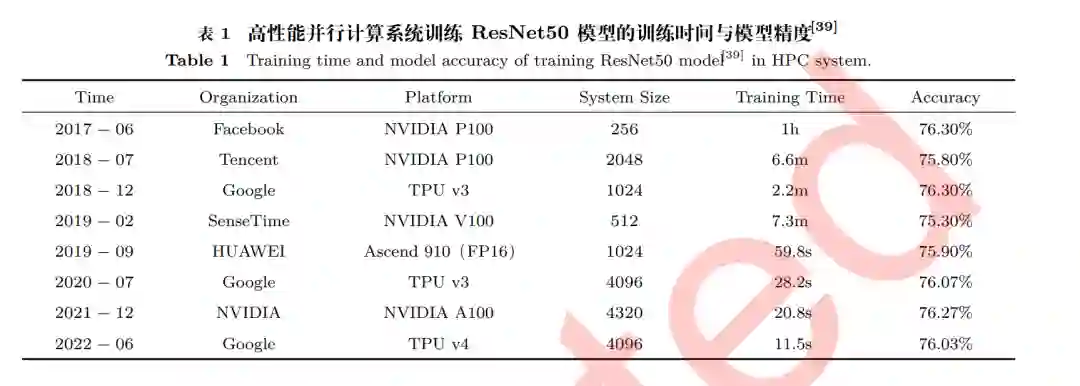
基于上述计算加速设备, 采用异构计算模式的高性能并行计算系统越来越广泛地用于训练大规 模神经网络模型. 例如在计算机视觉任务方面, 多个厂商使用 HPC 系统在 ImageNet-1K 数据集上 并行训练 ResNet-50, 加速效果如表 1所示. Meta(原 Facebook)使用 256 个 GPU, 以 8192 的 mini-batch 大小训练 ResNet-50[40] , 华为使用自主并行智能训练框架 MindSpore 和数千个 Ascend 910 芯片达到了 1024 petaFLOPS(PFLOPS) 的峰值性能(FP16). Summit 是 TOP500[41] 排名中 首个实现 E 级峰值性能的 HPC 系统, 在从 3.5 TB 气候图像中分割极端天气模式时, 可扩展到使用 27360 个 NVIDIA V100 GPU, 其半精度 FP16 计算峰值性能达到 1.13E+18 FLOPS[42] . 在预训练语 言模型方面, NVIDIA 使用 2048 个 A100 GPU 的 SuperPOD 训练 BERT 模型, 耗时 49 秒. Google 使用 4096 个 TPU v3 芯片训练 BERT, 耗时仅 23 秒. 为了研发 GPT-3 语言模型, OpenAI 使用了 微软 Azure 计算集群中的约一万个 V100 GPU.
并行智能训练技术挑战
随着深度学习算法的快速演进以及模型参数量和训练数据量的指数级增长, 智能模型训练面临 模型结构多样、内存开销巨大、参数通信密集等严峻挑战.
模型结构多样: 伴随着人工智能算法高速演进, 以深度神经网络为基础的智能应用, 其应用领域 在不断拓展. 然而不同的任务种类体现出不同的计算特点, 例如应用于视频等应用的实时目标检测 模型要求较高的吞吐量[22] , 以 Transformer 结构[9] 为基础的预训练语言模型包含众多大规模矩阵乘 法. 与此同时, 如2.3节所述, 智能训练系统快速发展, 可利用的计算规模不断增大. 如何高效利用训 练系统资源, 满足多种智能训练任务的不同需求, 对并行智能训练方法提出了挑战. 例如语言模型任 务中, 其对模型精度增加的需求导致模型参数量高速增长[43] , 使得单个设备无法容纳完整模型; 以及 研究者发现将稠密模型转为稀疏化激活可以进一步增加模型的表征能力[44] , 使得多个模型之间的计 算内容不再相同. 本文将在第 3节对并行智能训练基本模式进行介绍.
内存开销巨大: 如图 2 所示, 与大规模模型的参数量增长速度相比, 常用智能计算加速器的内存 容量增长较为缓慢. 因此, 如何在保证训练效率的同时高效地利用内存空间,成为大规模智能模型训 练的一大挑战. 首先, 单个设备的内存容量无法满足大规模模型训练的存储需求, 模型划分成为大规模模型训练的必需手段, 模型划分的优劣将显著影响智能训练运行效率, 然而,随着模型并行技术的 发展, 模型划分策略的搜索空间呈指数级增加, 给模型划分算法设计带来严峻的挑战. 其次, 常用异 构计算系统有着多级存储空间且异构存储空间的传输带宽有着显著区别, 大容量低带宽存储空间的 不当使用将降低整体训练性能, 本文第 4.1、 4.2节将分别介绍模型划分和内存优化相关的关键技术.

参数通信密集: 随着异构加速设备的性能持续增长, 智能模型训练的通信频率不断提高, 同时智 能模型参数量的增加也直接加大了参数通信的数据规模. 上述两方面的因素导致了参数通信开销在 系统中占比增加, 参数通信开销成为了制约大规模并行智能训练效率提升的性能瓶颈. 一方面, 专门 用于加速深度学习训练的专用芯片性能增长很快, 例如 NVIDIA A100 比其两代之前的产品 NVIDIA V100 的计算速度高 20 倍[45] . 另一方面, 网络带宽增速较慢, 而参数通信数据量却在越来越大. 高 性能并行计算系统常用 Infiniband 等高速互连网络, 但其带宽提升相较于通信数据量提升较慢. 在 并行智能训练系统的每次迭代中, 通信系统都需要传输模型参数或者梯度, 通信量与结点规模和模 型大小呈正相关关系. 如第 2.1、 2.3节所述, 在近年来结点规模和模型大小都增长的情况下, 通信 量也增长明显. 智能模型训练中密集的参数通信严重影响了并行智能训练系统的吞吐率和可扩展性. 第 4.3节将介绍近期在参数通信优化方面的相关工作.
4. 并行智能训练基本模式
随着智能模型参数量和训练数据量的增长, 单个计算设备已经不能满足模型训练的需求, 采用多 个计算设备进行并行智能训练成为主流训练方式. 高效的并行智能训练, 要求在保证模型收敛性的 前提下, 尽可能提高模型训练的吞吐量, 继而缩短模型的训练时间. 如图 3所示, 按照数据划分和模 型划分两个计算任务划分维度,并行智能训练包括数据并行[5,141] 和模型并行[53,56,65] 两种基础并行 训练模式,以及混合多种并行模式的混合并行模式[52,157,160,161] . 根据智能模型特点,模型并行又演 化出流水线并行[49∼53,55]、张量并行[56,57,60,61]、专家并行[63,65,66] 等多种计算模式.
5. 并行智能训练关键技术
并行智能训练基本模式为智能模型并行训练提供了基本方法, 但是, 如何根据智能模型和训练系 统的特点, 对并行智能训练方法进行优化, 尽可能挖掘并行训练系统的潜力, 提高并行智能训练的计 算效率和扩展性能,仍然面临模型划分、内存优化及通信优化等并行智能训练关键技术问题.

6 并行智能训练框架软件
智能训练框架为智能模型的开发提供编程接口和运行环境, 对于深度学习发展具有重要的推动 作用. 然而, 随着训练数据和模型参数规模的增长,智能训练需要的计算设备规模越来越大,并行智 能训练方式也越来越复杂, 传统的 TensorFlow、PyTorch 等基础深度学习框架已经不能满足大规模 智能模型的开发和训练需求. 因此, 数据并行训练框架和混合并行训练框架先后被提出, 通过对并行 智能训练方法进行封装, 抽象出简单易用的用户接口, 降低并行智能训练的编程难度, 进一步推动深 度学习技术的发展。

7 并行智能训练技术发展趋势
并行智能训练技术和框架软件的快速发展, 有效支撑了人工智能算法不断演进, 本节结合现有研 究梳理了并行智能训练技术的发展趋势.

8 总结
人工智能技术发展对于国家经济和国防建设都具有重要意义. 并行智能训练技术和框架软件, 向下依托高性能智能训练硬件系统, 向上支撑人工智能算法开发和运行, 是人工智能技术持续发展的 关键, 是智能训练软件生态建设的核心. 本文梳理了并行智能训练的基本模式和关键技术, 以及并行 智能训练框架的发展现状, 总结了国内外相关研究工作和最新研究进展, 分析了并行智能训练发展面 临的主要技术挑战, 以及作者团队在并行智能训练框架方面的研究成果和发展思路. 随着人工智能 算法的快速演进, 作为底层系统支撑技术, 并行智能训练将面临更多严峻挑战, 具有重要的研究价值 和广泛的应用前景.
