

导 读
本文是对发表于计算机视觉领域顶级会议 CVPR 2025 的论文 FreeCloth: Free-form Generation Enhances Challenging Clothed Human Modeling 的解读。该论文由北京大学王亦洲课题组完成。
该工作提出了名为 FreeCloth 的基于点云的混合式人体衣物建模方案,突破了现有方法在宽松衣物建模中的技术瓶颈。针对宽松衣物与骨骼运动关联性较弱的特点,该方法采用无约束自由生成网络,直接在姿态空间中对宽松衣物点云进行条件式生成。其混合表达框架兼具灵活性和强表达能力,能精准捕捉复杂几何细节。实验证明,FreeCloth 显著优于现有最先进的方法。文章在 CVPR 2025 中作为 Highlight 发表。
论文链接:
https://arxiv.org/pdf/2411.19942 项目代码:
https://github.com/AlvinYH/FreeCloth 项目主页:
https://alvinyh.github.io/FreeCloth/ 视频介绍:
https://www.youtube.com/watch?v=4dyM1hjTBdQ
01
研究背景
数字角色动画生成(Digital Avatar Animation)作为计算机视觉与图形学的交叉研究热点,在 VR/AR、电影及游戏创作等领域具有重要应用。传统图形学流程要求对全身 3D 人体模型进行骨骼绑定(Rigging),以模拟姿态变化引发的衣物形变。然而,当处理拓扑结构复杂的宽松衣物(如长裙)时,往往需要专业动画师进行逐帧调整,或依赖计算成本高昂的物理仿真方法。
专有名词解释
LBS:线性混合蒙皮方法(Linear Blend Skinning),最常见的人体驱动方式。该方法将人体简化为铰链式结构,通过 K=24 个关节点的刚性变换(SE(3)变换)描述人体姿态。对于人体表面的任意一点,其位置变换可表示为各关节刚性变换的线性凸组合(加权平均)。
现有的数据驱动方法[1-4]通过神经网络预测衣物的非刚性形变,作为 LBS 的补充和修正,即将衣物视为人体的“延伸”。然而这种范式受限于凸组合假设,难以表征远离人体骨骼的区域,导致宽松衣物在形变中出现“撕裂”现象。前沿工作如 IDOL[5]、GS-Avatar[6],虽实现了从单图或单视角视频重建可驱动 3D 人体,但囿于 LBS 的线性假设,在后续的动画生成应用中仍难以建模宽松衣物。由此可见,突破该技术瓶颈是实现数字人从静态 3D 迈向动态 4D 的关键挑战。
基于上述分析,我们的思考是:能否打破思维定势,突破现有的 LBS 框架呢?为此,本文提出了混合表达框架 FreeCloth,对靠近人体骨骼的区域保留 LBS 形变,对宽松衣物区域则采用自由生成策略,实现了点云表达下的高保真宽松衣物建模。

图1. FreeCloth 框架示意图 02
方法概览
本文探索的任务以 3D 人体扫描数据为输入,采用点云作为几何表达(不涉及纹理外观建模),旨在从训练序列中学习可驱动的人体及衣物模型。方法的核心创新点包括:
对紧身衣物区域保留基于 LBS 的形变方法(LBS-based Deformation) * 对宽松衣物区域采用无限制的自由生成方法(Free-form Generation) * 通过计算服装剪裁分区图(Clothing-cut Map)来实现区域的划分。
1. 点云分区处理
首先基于距离识别未受覆盖的体表区域(如头、手、足部),该区域无需任何变换(黄色标识)。利用分割模型 SAM[7]从法线图提取宽松服装掩码,经反投影后,通过与 SMPL 模型的最近邻关联确定覆盖区域(绿色标识)。该区域的顶点不参与“人体到衣物”的 LBS 形变,而是由生成网络直接预测对应服装的几何。剩余区域(蓝色标识)则采用基于 LBS 的“线性+非线性残差”形变方法。
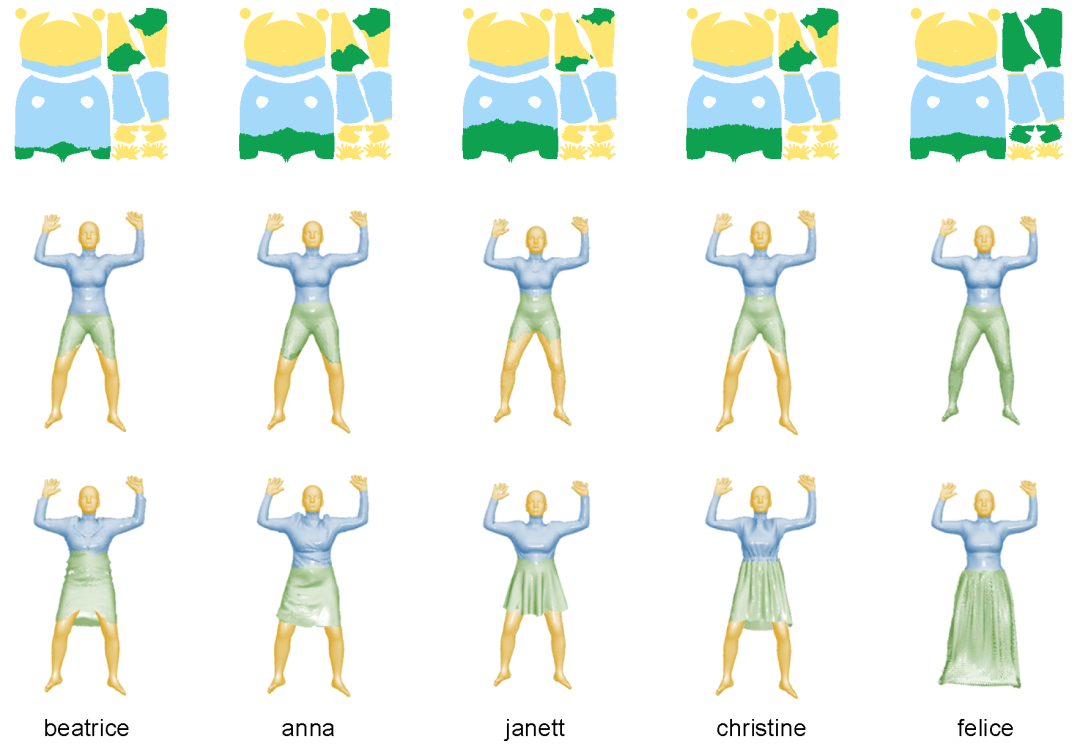
图2. 点云分区可视化示意图
2. 自由生成网络
我们将宽松衣物的姿态形变建模为条件生成任务(上述绿色区域),其核心设计包括:
**网络架构:**采用SpareNet[8]作为基础生成器。 * **条件编码:**基于人体语义分割的层级化姿态特征提取。相比全局特征提取,该设计能更好建模服装-骨骼的局部运动关联。 * **训练策略:**除三维监督外,我们还引入碰撞损失函数加强约束,避免宽松衣物与人体表面出现“穿模”;通过姿态空间增强,增强生成网络对姿态的鲁棒性。
此方案规避了 LBS 的拓扑约束,实现了自由形态形变(无需后处理变换),显著增强了网络的表达能力。而现有方法则采用两阶段 LBS 方案[2-4],学习特定衣物的“模版”,即为 SMPL 模型[9]添加衣物"外壳"再进行 LBS 形变,其性能提升有限。

图3. FreeCloth 模型架构图
03
实验结论
我们在合成数据集 ReSynth[1]上进行了实验评估,该数据集包含五段 3D 扫描序列,涵盖不同款式、长度及松紧度的裙装样本。通过渲染点云的多视角法线图,采用 MSE 和 FID 指标评估,FreeCloth 在各项指标上均表现最优,在用户研究中也获得63.4%的偏好率。特别是在最具挑战性的宽松裙装样本上,FreeCloth 的优势最为显著。

表1. FreeCloth 与现有工作在 ReSynth 数据集上的定量误差结果(越小越好)
除点云可视化外,我们还通过泊松重建得到三角网格以更全面地评估三维几何质量。如图4所示,POP 和 SkiRT[1, 2]出现“撕裂”伪影,且存在点云分布不均、缺乏真实褶皱细节等问题。FITE[3]方法受限于 LBS,在长裙建模中会产生不自然的过度弯曲褶皱,且难以捕捉精细几何特征,常导致表面噪声。相比之下,FreeCloth 凭借无约束的生成模块,在宽松区域能生成自然的高保真细节,同时保持点云均匀分布,充分展现了混合框架的卓越表征能力。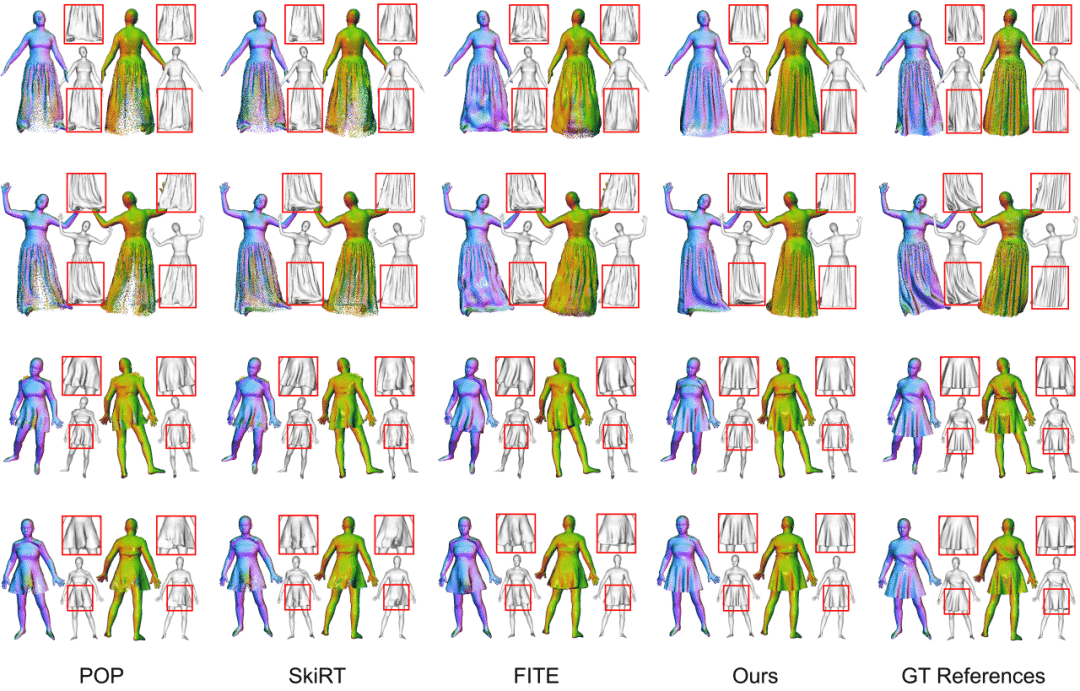



图4. FreeCloth 和现有方法的定性对比结果 (更多结果详见项目主页)
针对宽松服装的单独可视化表明:FreeCloth 既避免了 FITE 的“表面闭合”缺陷,也消除了 POP 和 SkiRT 中的“撕裂”现象,实现了当前最优的宽松服装生成质量。

图5. FreeCloth 和现有方法的宽松衣物生成效果对比
04
总 结
本文提出 FreeCloth——一种基于点云的混合式人体衣物建模框架,通过结合 LBS 形变与自由生成技术,实现对不同服装区域的针对性建模。该框架有效解决了现有方法在宽松衣物建模中存在的“撕裂”伪影、点云密度不均等问题,具有更强的拓扑灵活性,能生成逼真的高质量褶皱细节。在包含不同长度、松紧度及款式的宽松衣物测试中,FreeCloth 均展现出卓越的表征性能。我们相信,这种混合建模范式将为该领域的研究提供新的思路。
项目视频:
参考文献:
[1] Ma, Qianli, et al. "The power of points for modeling humans in clothing." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. [2] Ma, Qianli, et al. "Neural point-based shape modeling of humans in challenging clothing." 2022 International Conference on 3D Vision (3DV). IEEE, 2022. [3] Lin, Siyou, et al. "Learning implicit templates for point-based clothed human modeling." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022. [4] Zhang, Hongwen, et al. "Closet: Modeling clothed humans on continuous surface with explicit template decomposition." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. [5] Zhuang, Yiyu, et al. "IDOL: Instant Photorealistic 3D Human Creation from a Single Image." arXiv preprint arXiv:2412.14963 (2024). [6] Hu, Liangxiao, et al. "Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024. [7] Kirillov, Alexander, et al. "Segment anything." Proceedings of the IEEE/CVF international conference on computer vision. 2023. [8] Xie, Chulin, et al. "Style-based point generator with adversarial rendering for point cloud completion." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. [9] Loper, Matthew, et al. "SMPL: A skinned multi-person linear model." Seminal Graphics Papers: Pushing the Boundaries, Volume 2. 2023. 851-866.