

近期的AI生成内容(AIGC)在计算机视觉中取得了显著的成功,其中扩散模型在这一成就中扮演了至关重要的角色。由于其出色的生成能力,扩散模型正逐渐取代基于GANs和自回归Transformers的方法,在图像生成和编辑方面展现出卓越的性能,而且在视频相关研究领域也是如此。然而,现有的综述主要集中在图像生成的扩散模型背景下,对于它们在视频领域的应用很少有最新的评述。为了解决这一缺陷,本文呈现了AIGC时代视频扩散模型的全面综述。具体来说,我们从扩散模型的基础和演变进行简要介绍。随后,我们对视频领域的扩散模型研究进行了概述,将工作划分为三个关键领域:视频生成、视频编辑和其他视频理解任务。我们对这三个关键领域的文献进行了彻底的综述,包括进一步的分类和领域内的实际贡献。最后,我们讨论了这个领域研究所面临的挑战,并概述了潜在的未来发展趋势。本次综述中研究的视频扩散模型的全面列表可以在https://github.com/ChenHsing/Awesome-Video-Diffusion-Models 找到。
AI生成内容(AIGC)目前是计算机视觉和人工智能中最为突出的研究领域之一。它不仅引起了广泛的关注和学术研究,而且在多个行业和其他应用中产生了深远的影响,如计算机图形学、艺术和设计、医学成像等。在这些努力中,由扩散模型 [1–7] 代表的一系列方法特别成功,迅速取代了基于生成对抗网络(GANs)[8–12] 和自回归Transformers [13–16] 的方法,成为图像生成的主要方法。由于它们强大的可控性、逼真的生成和令人印象深刻的多样性,基于扩散的方法也在计算机视觉任务的广泛范围内蓬勃发展,包括图像编辑 [17–20]、密集预测 [21–25] 以及如视频合成 [26–31] 和3D生成 [32–34] 等多样化领域。作为最重要的媒介之一,视频在互联网上崭露头角。与纯文本和静态图像相比,视频提供了丰富的动态信息,为用户提供了更为全面和沉浸式的视觉体验。基于扩散模型的视频任务研究逐渐受到关注。如图1所示,自2022年以来,视频扩散模型的研究出版物数量显著增加,可以划分为三大类:视频生成 [26, 27, 29–31, 35, 36]、视频编辑 [37–41] 和视频理解 [42–45]。
随着视频扩散模型[27]的快速进步及其展示的令人印象深刻的结果,跟踪和比较这一主题上的最新研究变得非常重要。已有几篇综述文章涵盖了AIGC时代的基础模型[46, 47],包括扩散模型本身[48, 49]和多模态学习[50–52]。还有一些特定聚焦于文本到图像[53]研究和文本到3D[54]应用的综述。然而,这些综述要么只粗略地涵盖视频扩散模型,要么更多地强调图像模型[49, 50, 53]。因此,在这项工作中,我们旨在填补这一空白,对扩散模型的方法论、实验设置、基准数据集和其他视频应用进行全面回顾。 贡献:在本综述中,我们系统地跟踪和总结了关于视频扩散模型的最近文献,涵盖了如视频生成、编辑以及其他视频理解方面的领域。通过提取共享的技术细节,本综述涵盖了该领域最具代表性的作品。我们还介绍了关于视频扩散模型的背景和相关的初步知识。此外,我们对视频生成的基准和设置进行了全面的分析和比较。据我们所知,我们是首个专注于这个特定领域的团队。更重要的是,鉴于视频扩散的快速发展,我们可能没有涵盖本综述中的所有最新进展。因此,我们鼓励研究者与我们联系,与我们分享这一领域的新发现,使我们能够保持最新。这些新的贡献将被纳入修订版进行讨论。
综述流程:在第2节中,我们将介绍背景知识,包括问题定义、数据集、评估指标和相关研究领域。随后,在第3节中,我们主要介绍视频生成领域的方法概览。在第4节中,我们深入探讨关于视频编辑任务的主要研究。在第5节中,我们阐述了利用扩散模型进行视频理解的各种方向。在第6节中,我们突出了现有的研究挑战和潜在的未来发展方向,并在第7节中总结我们的结论性观点。
视频生成
在这一部分,我们将视频生成划分为四个类别,并为每个类别提供详细的评论:通用文本到视频(T2V)生成(第3.1节)、带其他条件的视频生成(第3.2节)、无条件视频生成(第3.3节)以及视频完成(第3.4节)。最后,我们总结了设置和评估指标,并在第3.5节中对各种模型进行了全面比较。视频生成的分类细节在图2中展示。
带文本条件的视频生成
如近期研究[1, 2, 171] 所证明的,生成型AI与自然语言之间的互动至关重要。尽管在从文本生成图像[1–3, 16] 方面取得了重大进展,但文本到视频(T2V)方法的发展仍处于初级阶段。在这个背景下,我们首先简要概述了一些非扩散方法[172, 173],然后深入介绍了基于训练和无需训练的扩散技术的T2V模型。
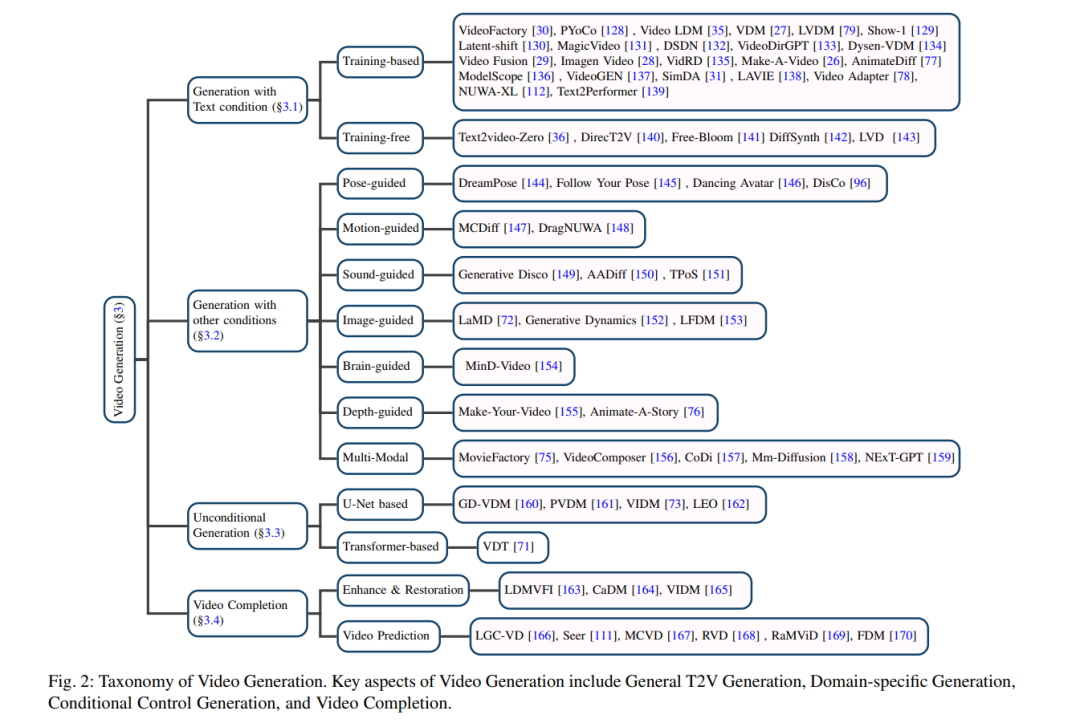
带其他条件的视频生成
之前介绍的大多数方法都与文本到视频生成有关。在这个小节中,我们关注于基于其他模态(例如姿态、声音和深度)的视频生成。我们在图3中展示了受条件控制的视频生成示例。

视频编辑
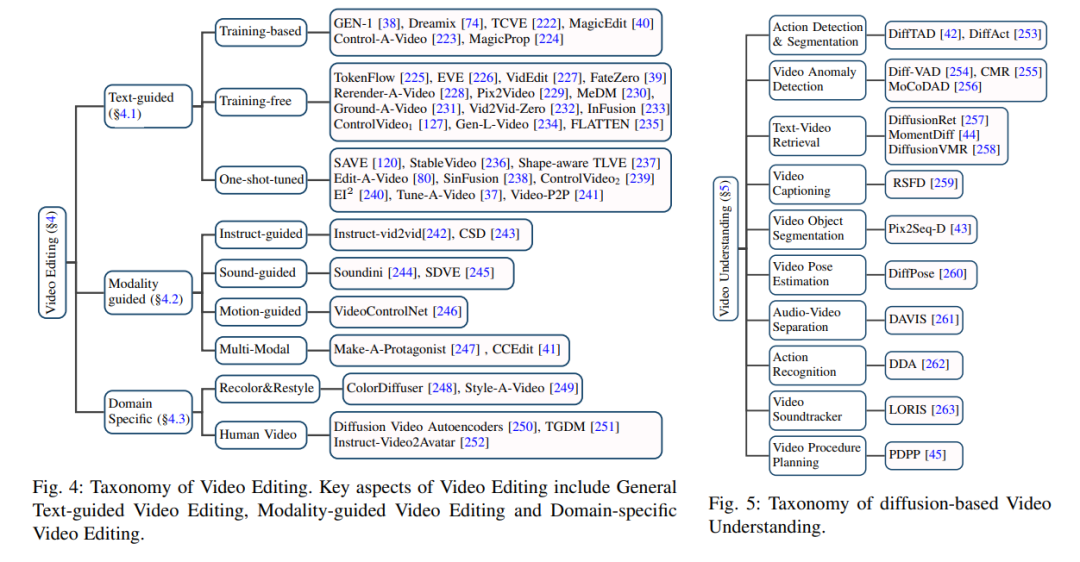
随着扩散模型的发展,视频编辑研究的数量呈指数增长。许多研究[74, 233, 236, 239]的共识是,视频编辑任务应满足以下标准:(1) 保真度:每帧的内容应与原视频的对应帧内容保持一致;(2) 对齐度:输出视频应与输入控制信息对齐;(3) 质量:生成的视频应在时间上保持一致并且质量高。虽然可以利用预训练的图像扩散模型通过逐帧处理进行视频编辑,但帧与帧之间缺乏语义一致性,使得逐帧编辑视频变得不可行,使视频编辑成为一个具有挑战性的任务。在本节中,我们将视频编辑分为三类:文本引导的视频编辑(第4.1节)、模态引导的视频编辑(第4.2节)和特定领域的视频编辑(第4.3节)。视频编辑的分类细节在图4中总结。
文本引导的视频编辑在文本引导的视频编辑中,用户提供一个输入视频和一个描述所需视频属性的文本提示。然而,与图像编辑不同,文本引导的视频编辑带来了帧一致性和时间建模的新挑战。一般来说,文本基视频编辑有两种主要方式:(1) 在大规模文本-视频对数据集上训练T2V扩散模型;(2) 扩展预训练的T2I扩散模型进行视频编辑。后者更受关注,因为大规模文本-视频数据集很难获取,且训练T2V模型在计算上昂贵。为了捕捉视频中的运动,各种时间模块被引入到T2I模型中。然而,扩展T2I模型的方法面临两个关键问题:时间不一致性,其中编辑过的视频在帧与帧之间的视觉上出现闪烁;以及语义差异,即视频没有根据给定文本提示的语义进行更改。几项研究从不同的角度解决了这些问题。
视频理解
除了在生成任务中的应用,例如视频生成和编辑,扩散模型也在基本的视频理解任务中得到了探索,例如视频时间段分割[42, 253]、视频异常检测[254, 255]、文本-视频检索[44, 257]等,这些将在本节中介绍。视频理解的分类细节在图5中总结。
结论
本综述深入探讨了AIGC(AI-生成的内容)时代的最新发展,重点关注视频扩散模型。据我们所知,这是此类工作的首次尝试。我们提供了对扩散过程的基本概念、热门基准数据集以及常用评估指标的全面概述。在此基础上,我们全面地回顾了超过100种不同的工作,这些工作专注于视频生成、编辑和理解的任务,并根据其技术观点和研究目标对它们进行了分类。此外,在实验部分,我们详细描述了实验设置,并对多个基准数据集进行了公正的比较分析。最后,我们提出了关于视频扩散模型未来的几个研究方向。

