

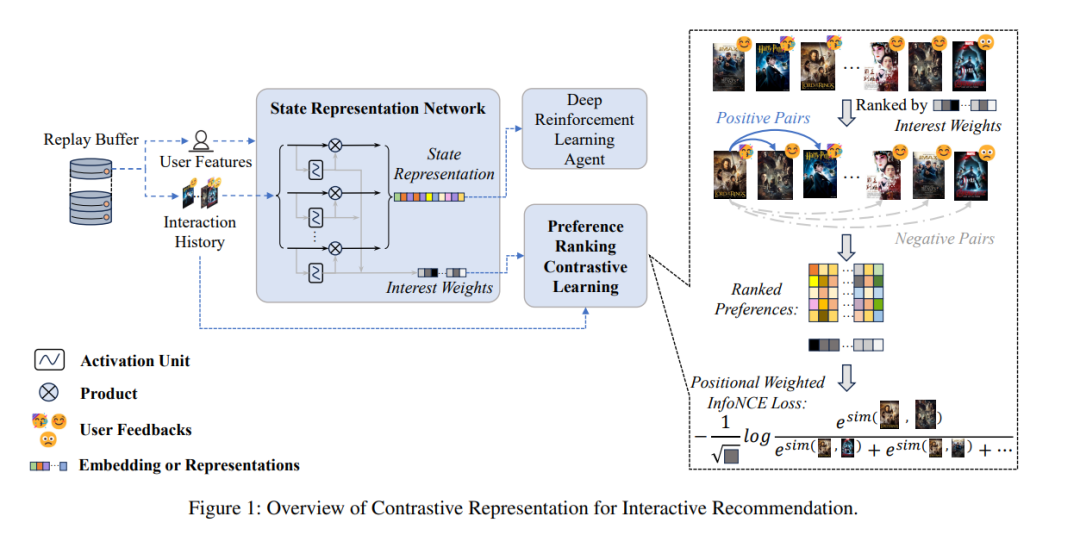
互动推荐(IR)最近因其能够迅速捕捉动态兴趣并优化短期和长期目标而受到广泛关注。IR代理通常通过深度强化学习(DRL)实现,因为DRL本质上与IR的动态特性兼容。然而,DRL目前并不完全适用于IR。由于动作空间庞大和样本效率低下的问题,训练DRL推荐代理是一个挑战。关键问题在于,无法提取有用的特征作为高质量表示,供推荐代理优化其策略。为了解决这个问题,我们提出了用于互动推荐的对比表示(CRIR)。CRIR能够高效地从显式交互中提取潜在的高级偏好排序特征,并利用这些特征来增强用户表示。具体来说,CRIR通过一个表示网络提供表示,并通过我们提出的偏好排序对比学习(PRCL)进行优化。PRCL的关键理念是,它可以在不依赖于涉及高级表示或庞大潜在动作集的计算的情况下进行对比学习。此外,我们还提出了一种数据利用机制和代理训练机制,以更好地将CRIR适应于DRL骨架。通过广泛的实验,我们的方法在训练基于DRL的IR代理时,展现了在样本效率上的显著提升。 https://arxiv.org/abs/2412.18396
成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日