

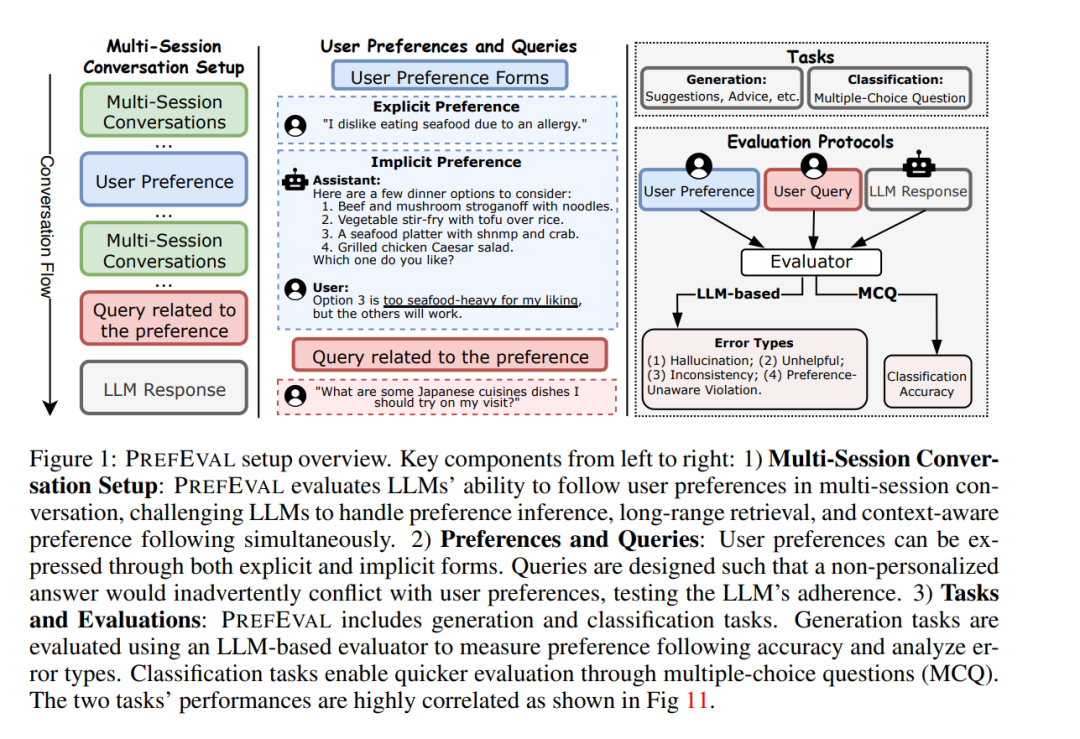
大语言模型(LLMs)越来越多地被用作聊天机器人,但其在根据用户偏好个性化响应方面的能力仍然有限。我们提出了PREFEVAL,这是一个用于评估LLMs在长上下文对话环境中推断、记忆和遵循用户偏好能力的基准。PREFEVAL包含3,000对人工整理的用户偏好和查询对,涵盖20个主题。PREFEVAL以显式和隐式形式包含用户个性化或偏好信息,并通过生成任务和分类任务评估LLM的表现。 利用PREFEVAL,我们在多轮对话中评估了10个开源和专有LLMs的上述偏好遵循能力,上下文长度从短到长(最高达100k标记)。我们通过多种提示方法、迭代反馈和检索增强生成方法进行了基准测试。我们的基准测试表明,最先进的LLMs在主动遵循用户偏好的对话中面临显著挑战。特别是在零样本设置中,大多数评估模型的偏好遵循准确率在仅10轮对话(约3k标记)后降至10%以下。即使使用高级提示和检索方法,偏好遵循能力在长上下文对话中仍然会下降。
此外,我们展示了在PREFEVAL上进行微调可以显著提高性能。我们相信,PREFEVAL将成为衡量、理解和增强LLMs偏好遵循能力的重要资源,为个性化对话代理的发展铺平道路。我们的代码和数据集可在https://prefeval.github.io/获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
85+阅读 · 2023年3月21日