
解释股票预测通常是传统非生成式深度学习模型的一项艰难任务,在这些模型中,解释仅限于在重要文本上可视化注意力权重。如今,大型语言模型(LLMs)提供了解决这一问题的方法,鉴于它们已知的能力在于为其决策过程生成人类可读的解释。然而,股票预测的任务对LLMs来说仍然充满挑战,因为它需要能力去权衡混乱社会文本对股价的各种影响。随着解释组件的引入,这个问题变得更加困难,这要求LLMs口头解释为什么某些因素比其他因素更重要。另一方面,为了对LLMs进行微调以适应这样的任务,需要在训练集中对每次股票运动的解释有专家注释的样本,这既昂贵又难以扩展。
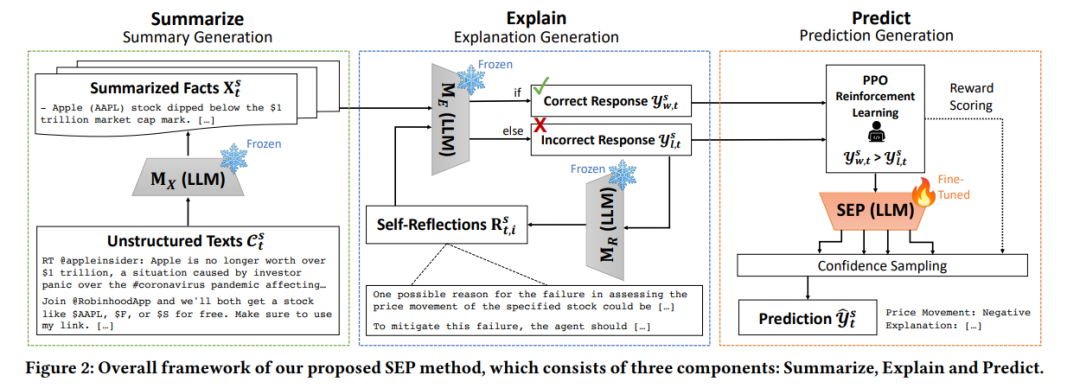
为了解决这些问题,我们提出了我们的摘要-解释-预测(SEP)框架,它利用了一个口头自我反思代理和近端策略优化(PPO),允许LLM自学如何生成可解释的股票预测,以一种完全自主的方式。反思代理通过自我推理过程学习如何解释过去的股票运动,而PPO训练器训练模型在测试时根据输入文本生成最可能的解释。PPO训练器的训练样本也是在反思过程中生成的响应,这消除了对人类注释者的需求。使用我们的SEP框架,我们对一种专门的LLM进行了微调,它在预测准确性和马修斯相关系数上都超过了传统的深度学习和LLM方法,用于股票分类任务。为了证明我们框架的泛化能力,我们进一步在投资组合构建任务上测试它,并通过各种投资组合指标展示其有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2024年3月22日
Arxiv
223+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年3月22日
Arxiv
223+阅读 · 2023年4月7日