
转载机器之心编辑:亚鹂、Panda
龙年即将结束,但有些股民可能无心过春节了。受低成本推理模型 DeepSeek-R1 热潮影响,美股昨日开盘后迎来重挫。周一,**英伟达市值大幅下跌,损失接近 6000 亿美元,创下美国历史上公司单日市值最大跌幅。**此次股价暴跌幅度达 17%,最终收盘价为 118.58 美元。上周,英伟达才刚刚超越苹果,成为全球市值最高的上市公司。此次股价暴跌直接导致纳斯达克指数下滑了 3.1%。
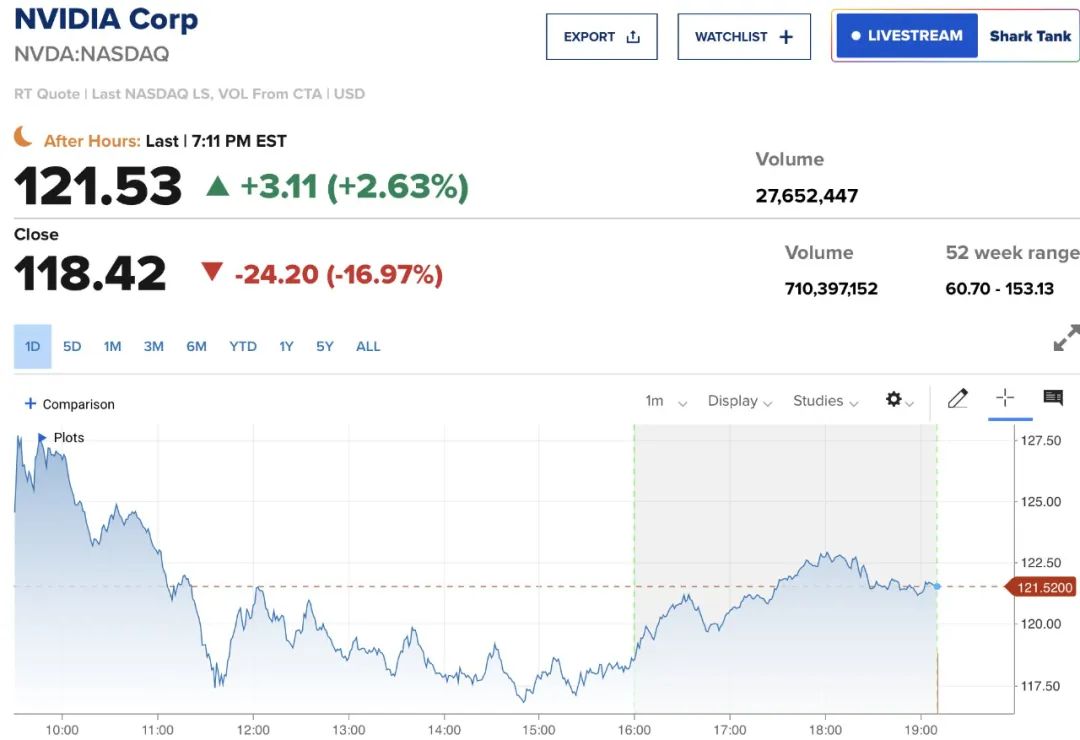
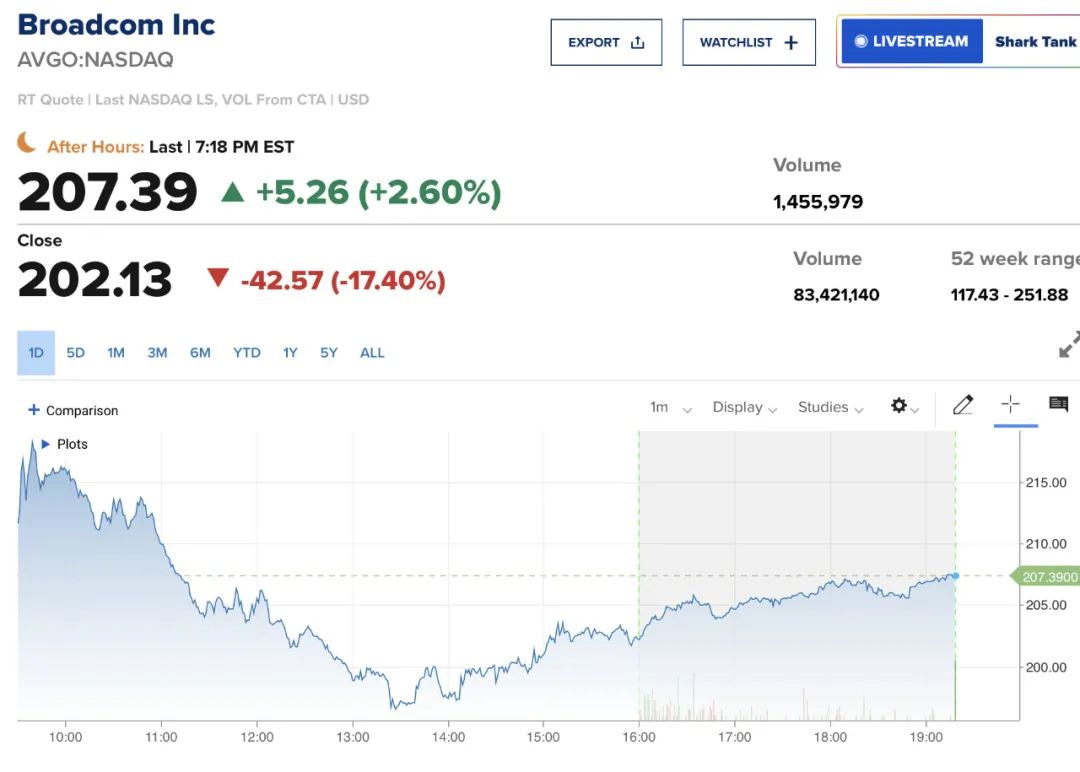
另一家依赖 AI 获得巨额市值增长的美国大型芯片制造商 Broadcom,周一跌幅则达到 17%,市值蒸发了 2000 亿美元。
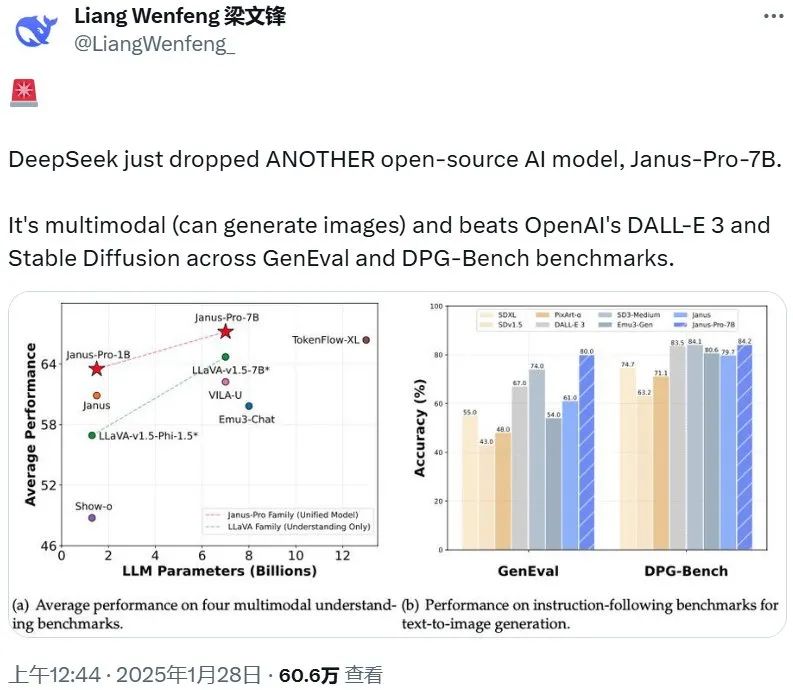
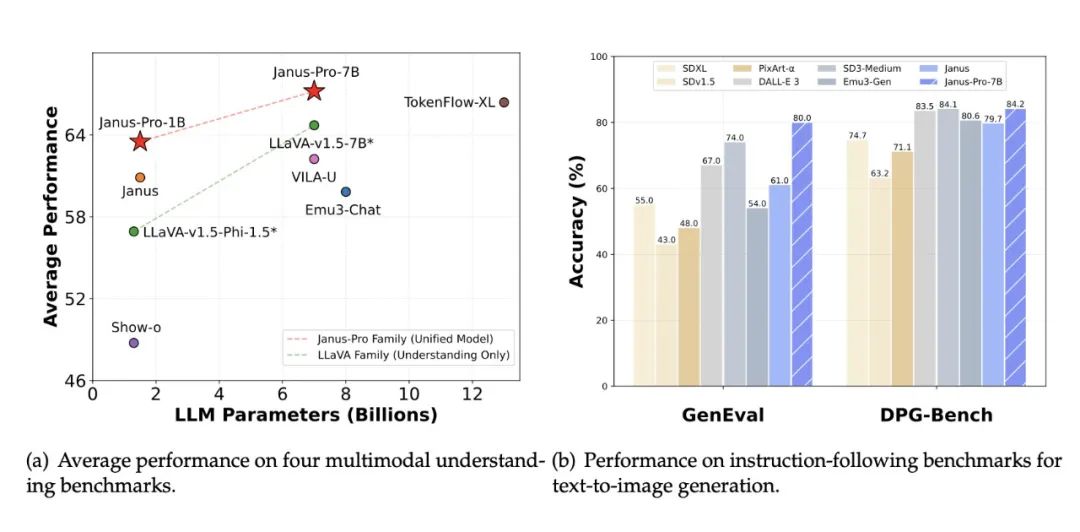
此次抛售的原因,主要是源于中国人工智能实验室 DeepSeek 带来的全球 AI 竞争压力飙增的担忧。去年 12 月,DeepSeek 发布了一个免费的开源大语言模型 ——DeepSeek-V3,训练成本仅仅为 558 万美元,并表示该模型只用了两个月时间完成,使用的还是英伟达的低能力版芯片 H800。 反观 Alphabet、Meta 和亚马逊等科技巨头,为训练和运行 AI 模型,花费了数十亿美元用于购买英伟达最前沿基础设备。 将开源进行到底,Janus-Pro 问世在美股一片惨嗥的同时,DeepSeek 再接再厉继续开源,发布了视觉模型 Janus-Pro。该模型是去年 10 月发布的 Janus 的升级版,在质量上实现了飞跃式提升。与此同时,DeepSeek 还发布了一款多模态理解模型 JanusFlow-1.3B。Janus-ProJanus Pro 是基于之前的 Janus 开发的高级版。整体而言,Janus Pro 实现了三大改进:训练策略优化、训练数据扩****展、扩展到了更大模型。有了这些改进, Janus Pro 在多模态理解和文生图指令遵从能力都收获了显著提升 —— 在多个基准上超越了 DALL-E 3 与 Stable Diffusion,同时文生图的稳定性也得到了加强。此次,DeepSeek 一次性发布了 7B 和 1B 两个版本。刚刚注册 𝕏 帐号的 DeepSeek 创始人梁文峰(目前还无法验证该帐号的真实性)也宣布了此消息。
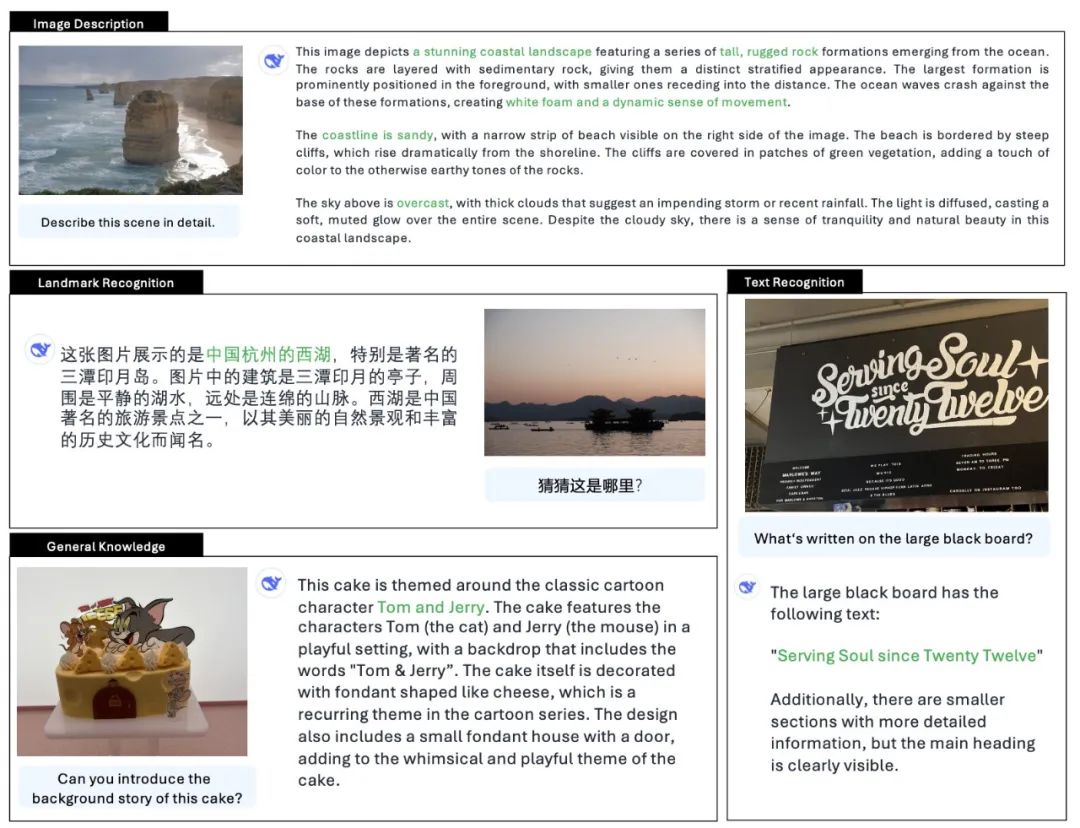
已经有不少网友尝试过该模型了,比如生成一个看起来像网球的小鸟,绒毛形态十分逼真。

或者由「美丽的汉字」五个字符组成的图画:

这个同时兼具视觉理解和生成的模型着实再一次震惊了中外 AI 社区,毕竟这个表现如此卓越的模型仅有 7B 大小!

- 论文标题:Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
- 论文地址:https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
- 7B 版本:https://huggingface.co/deepseek-ai/Janus-Pro-7B
- 1B 版本:https://huggingface.co/deepseek-ai/Janus-Pro-1B
- Hugging Face 试用链接:https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
DeepSeek 如今正将其影响力从语言处理,扩展到计算机视觉领域。据随模型发布的技术论文介绍,Janus Pro 7B 在效率和多功能性方面经过精心设计,能够在一系列视觉任务中表现出色:从生成逼真的图像到执行复杂的视觉推理任务。 

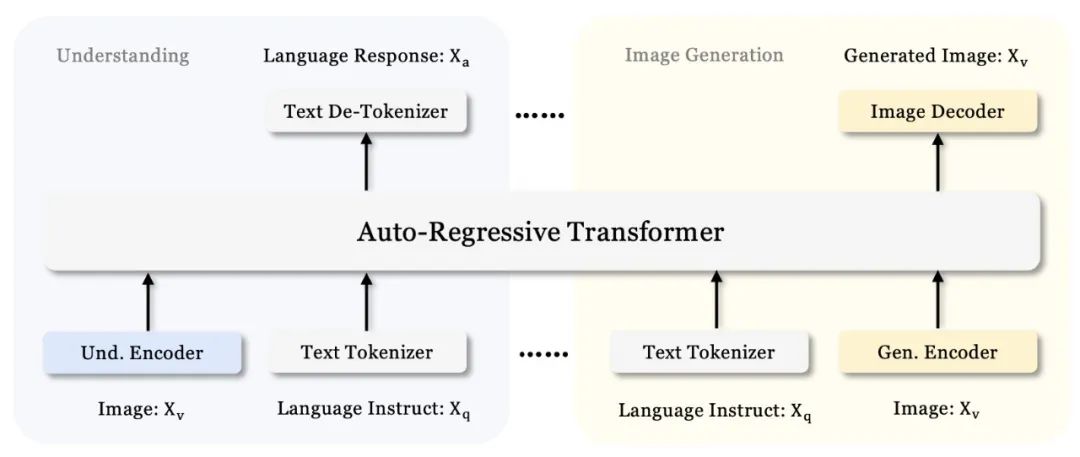
- Janus Pro 架构 对效率的强调是 Janus Pro 7B 区别于其他大规模、高资源需求 AI 模型的关键优势。与一些最大且最耗资源的 AI 模型不同,Janus Pro 7B 通过其 70 亿参数设计,能够提供高水平的性能,同时避免了对庞大计算资源的需求。 Janus-Pro 的架构与 Janus 相同。如下图所示,整体架构的核心设计原则是将多模态理解与生成的视觉编码解耦。研究者应用独立的编码方法将原始输入转换为特征,这些特征随后由一个统一的自回归 Transformer 处理。
Janus-Pro 架构
- 训练策略优化 Janus 的前一个版本采用了三阶段训练过程:
 Janus-Pro 架构
Janus-Pro 架构- 阶段 I:重点训练适配器和图像头。
- 阶段 II:进行统一预训练。在此过程中,除理解编码器和生成编码器外,所有组件的参数都会被更新。
- 阶段 III:进行监督微调。在阶段 II 的基础上,进一步解锁理解编码器的参数。
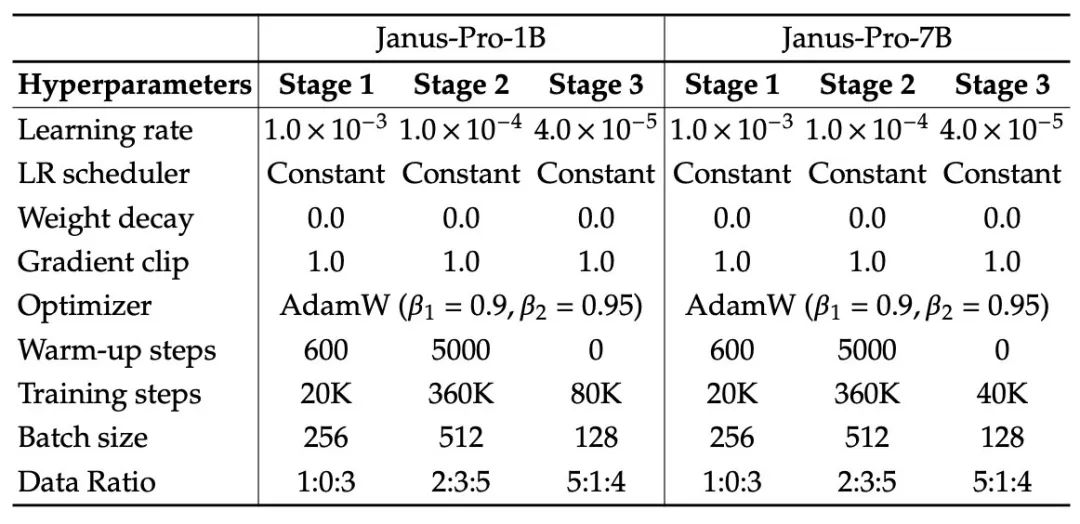
然而,这种训练策略存在一些问题。通过进一步的实验,DeepSeek 研究团队发现这一策略并不最优,并导致了显著的计算效率低下。 为解决此问题,他们在原有基础上进行了两项修改: 在阶段 I 延长训练时间:研究者增加了阶段 I 的训练步数,以确保在 ImageNet 数据集上得到充分的训练。他们经过研究发现,即使固定了大语言模型(LLM)的参数,该模型仍能有效地建模像素间的依赖关系,并根据类别名称生成合理的图像。 在阶段 II 进行重点训练:在阶段 II 中,研究者去除了 ImageNet 数据,直接使用标准的文本生成图像数据来训练模型,从而使模型能够基于详细的描述生成图像。这种重新设计的方法使得阶段 II 能够更高效地利用文本生成图像的数据,并显著提高了训练效率和整体性能。 3. 数据扩展 研究团队在 Janus 的训练数据上进行了扩展,涵盖了多模态理解和视觉生成两个方面:
- 多模态理解:对于阶段 II 的预训练数据,参考 DeepSeek-VL2 ,并增加了大约 9000 万条样本。样本包括图像标注数据集,以及表格、图表和文档理解的数据。
- 视觉生成:前一个版本的 Janus 使用的真实世界数据质量较差,且包含大量噪声,导致文本生成图像时不稳定,生成的图像质量较差。在 Janus-Pro 中,研究者加入了大约 7200 万条合成的美学数据样本,在统一预训练阶段,真实数据和合成数据的比例为 1:1。
- 模型扩展 前一个版本的 Janus 通过使用 1.5B 的大语言模型(LLM)验证了视觉编码解耦的有效性。在 Janus-Pro 中,研究团队将模型扩展至 7B,并在其中详细列出了 1.5B 和 7B LLM 的超参数(见下表)。 他们观察到,当扩大 LLM 的规模时,无论是在多模态理解还是视觉生成任务中,损失函数的收敛速度相比于较小的模型都会有显著的提升。
这个发现进一步验证了该方法的强大可扩展性。 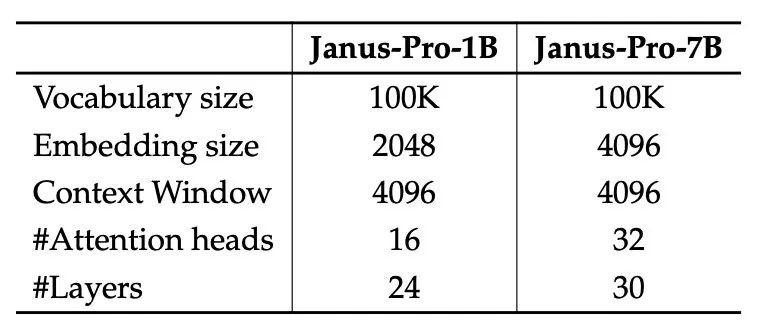
在发布 Janus Pro 的同时,DeepSeek 还发布了一个多模态理解模型 JanusFlow-1.3B。从名字也能看出来,参数量同样不高。 据介绍,JanusFlow 是一个将图像理解和生成统一在一个模型中的强大框架。其引入了一种极简主义架构,将自回归语言模型与校正流(rectified flow,一种生成建模的 SOTA 方法)相结合。 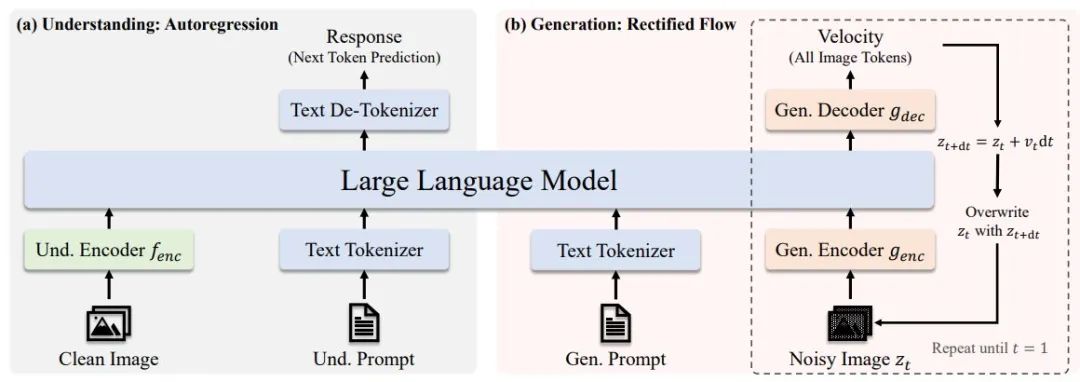

- 论文标题:JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
- 论文地址:https://arxiv.org/pdf/2411.07975
当时的实验结果表明,JanusFlow 在不同的领域中都实现了与专门模型相当或更优异的性能,同时在标准基准上明显优于现有的统一方法。因此,可以说,这项研究代表着向更高效和多功能的视觉语言模型迈出的重要一步。下图展示了其一些基准测试结果数据以及生成结果。

DeepSeek 两连击:提升市场焦虑与竞争压力
Janus Pro 7B 的发布引发了不少讨论,比如 VentureBeat 认为:「Janus Pro 7B 的发布时机放大了其影响力。这是紧随 R1 模型和随之而来的市场动荡之后,它强化了这样的叙事:DeepSeek 是能够颠覆 AI 既定秩序的创新者。」 该媒体还认为:「Janus Pro 7B 的开源性质会加剧这种颠覆。与之前的开源运动一样,这会让人们更容易使用高级 AI。大型科技公司以外的企业将受益:无需供应商锁定或高额费用即可获得顶级 AI。对于 AI 巨头来说,DeepSeek 构成了直接威胁:**他们的专有高级模型能否在免费、高质量的替代品面前生存下来?**当前的股市抛售情况表明投资者对此表示怀疑。」对于 DeepSeek 正在给 AI 社区以及投资市场带来的影响,你有什么看法,请与我们分享。参考链接https://venturebeat.com/ai/deepseek-unleashes-janus-pro-7b-vision-model-amidst-ai-stock-bloodbath-igniting-fresh-fears-of-chinese-tech-dominance/
