简介
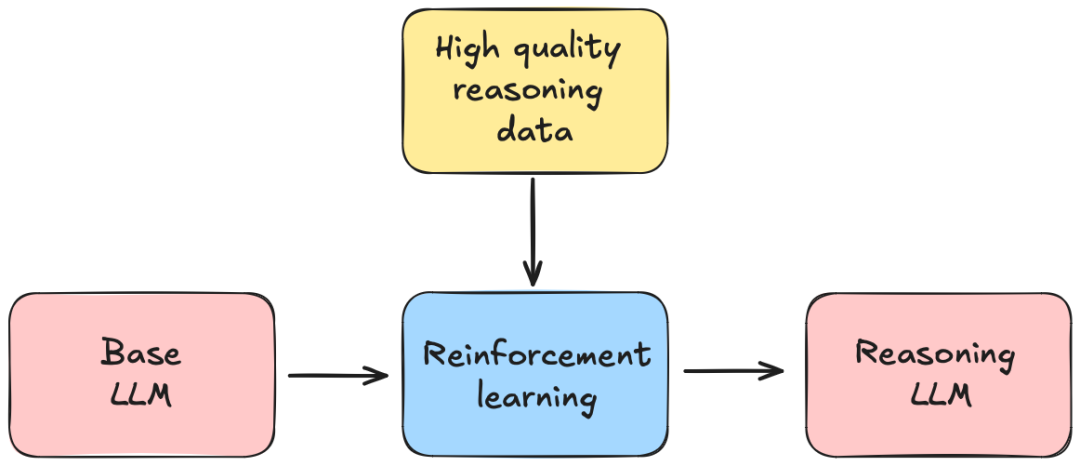
DeepSeek-R1 代表了具备推理能力的大型语言模型(LLM)的一项重要突破。该模型以 MIT 许可协议发布,与 OpenAI 的 o1 系列等封闭源代码巨头竞争,同时开创了一种基于强化学习(RL)的推理任务框架。 DeepSeek-R1 利用在《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》一文中提出的组相对策略优化(GRPO),取代了传统的 PPO 方法,使得训练更加高效且具可扩展性。DeepSeek-R1 还采用了在 DeepSeek-V3 中引入的多头潜在注意力(MLA),通过将键-查询-值(KQV)矩阵投影到低维潜在空间,减少了长上下文处理时的计算和内存低效问题。此外,DeepSeek-R1 展示了通过 RL 推理能力的自然涌现,而无需依赖大规模的监督微调(SFT)。 DeepSeek-R1 重新定义了开源 AI,证明了推理能力可以仅通过 RL 自然涌现。通过诸如 GRPO、FP8 量化和涌现的 CoT 推理等创新,它与封闭源代码模型相媲美,同时促进了透明度和可访问性。随着研究社区在这些创新基础上不断发展,DeepSeek-R1 标志着朝着高效、推理驱动的 AI 迈出了重要的一步,并使所有人都能接触到这一技术。 本报告将探讨其架构、阶段性训练流程、GRPO 机制和涌现推理行为,以及蒸馏如何将推理能力传递到较小的模型中。架构基础
DeepSeek-R1 构建于 DeepSeek-V3-Base 模型之上,集成了优化训练效率和推理性能的前沿架构创新。这些基础增强包括专家混合(MoE)、多头潜在注意力(MLA)、FP8 量化和多标记预测(MTP)。本节详细介绍了每个组件。 DeepSeek-R1 的架构基础代表了最先进技术的综合应用,集合这些创新使其在推理密集型任务中的表现得到了优化。这些创新使其成为领先的开源大型语言模型,在效率和推理能力上与专有模型竞争。专家混合(MoE)
概述:专家混合(MoE)机制仅激活每个 Transformer 块中的部分参数,从而在保持模型质量的同时,实现了显著的计算节省。这种选择性激活对于在不成比例增加计算成本的情况下扩大模型参数非常有利。DeepSeek-V3 实现:DeepSeek-V3 在 MoE 中使用稀疏路由机制,其中一个门控网络为每个标记选择 top-k 专家。这确保了在任何给定时间,只有部分参数被激活,从而大大减少了计算量,同时保持了性能。DeepSeek-R1 的增强与实现细节:
- 动态专家分配:根据标记上下文动态选择专家,减少过度专业化的风险。
- 强化学习优化:实现了强化学习指导的专家利用,平衡计算负载并优化推理速度。
- 稀疏激活约束:引入稀疏性约束,以在保持模型表现力的同时最小化计算开销。