随着现代软件的复杂性不断升级,软件工程已经成为一项越来越令人生畏且容易出错的工作。近年来,神经代码智能(NCI)领域已经成为一种有前途的解决方案,利用深度学习技术的力量来解决源代码的分析任务,目标是提高编程效率,并最大限度地减少软件行业中的人为错误。预训练语言模型已经成为NCI研究的主导力量,在广泛的任务中始终如一地提供最先进的结果,包括代码摘要、生成和翻译。在本文中,我们对NCI领域进行了全面的调研,包括对预训练技术、任务、数据集和模型架构的全面回顾。我们希望这篇论文能成为自然语言和编程语言社区之间的桥梁,为这一快速发展领域的未来研究提供见解。
https://www.zhuanzhi.ai/paper/d0c79cc69bdb9171339f34e916fc7c12
1. 引言
编程语言(Pierce, 2002)作为软件的基础,使人类能够与计算机交流并指导计算机进行计算。使用编程语言开发软件的过程,即软件开发,已经成为一个蓬勃发展的行业,在现代数字世界中发挥着至关重要的作用。然而,软件开发还包括编程之外的一系列任务,包括测试、文档编写和bug修复,众所周知,这些任务具有挑战性,需要高水平的人类专业知识(Brooks, 1978)。
为了简化软件开发,代码智能工具作为一种自动分析源代码并解决软件工程任务的计算机辅助方法应运而生。以前,这些工具大多基于静态分析技术。例如,Microsoft Intellisense是一个代码智能工具,它通过静态分析用户代码和构建定义、引用、类型签名等数据库来提供代码补全建议和提示函数签名。还有一些工具可以自动检测源代码中的漏洞(Ayewah et al., 2008;Engler and Musuvathi, 2004)。虽然这些工具在工业中被广泛采用,但它们有局限性。主要的限制之一是,这些工具通常是为特定的编程语言构建的,需要大量的工作才能将它们迁移到新语言。此外,像Python这样的动态语言很难进行静态分析,这使得传统的代码智能工具对开发人员来说效率较低。
最近,研究人员已经开始将语言模型和预训练策略应用于代码智能任务,如程序合成(Chen et al., 2021; Wang et al., 2021b);,文档生成(Wang et al., 2021b; Alon et al., 2019a; Feng et al., 2020),缺陷检测和程序修复,这是受预训练Transformer模型在序列数据建模上的成功启发(Krizhevsky et al., 2017; Vaswani et al., 2017)。受软件自然性假设的启发(Hindle et al., 2016; Buratti et al., 2020),这表明编程语言可以像自然语言一样被理解和生成,研究人员将源代码视为顺序数据并应用顺序神经架构,如Transformer模型(Vaswani et al., 2017),以理解和生成程序(Feng et al., 2020;Guo et al., 2021)。在自然语言处理(NLP)社区中,人们观察到,当有大量未注释数据可用时,预训练范式使模型能够学习高质量的上下文token嵌入,并显著提高下游性能(Krizhevsky等人,2017;Brown等人,2020)。同样,可以在GitHub等开源平台上找到大量编程语言的代码片段(Chen et al., 2021)。因此,研究人员采用了预训练范式(Devlin等人,2019)来解决各种代码分析任务(Feng et al., 2020; Guo et al., 2021; Chen et al., 2021)。与静态分析器相比,这种数据驱动的方法大大节省了开发支持不同任务和适应新的编程语言的代码智能工具的工作量。迄今为止,预训练代码语言模型在广泛的任务上取得了最先进的性能,并在不同语言中表现出令人满意的泛化能力(Wang等人,2021b;Chen等人,2021;Li等人,2022)。值得注意的是,Codex (Chen等人,2021)在程序合成方面取得了一个重要的里程碑,并增强了Copilot2等编程智能工具的能力,这些工具甚至被应用于解决线性代数和数学应用题(Tang et al., 2021; Drori and Verma, 2021)。
尽管将预训练语言模型应用于代码智能任务取得了成功,该领域的研究也在蓬勃发展,但一直缺乏对不断增长的文献进行分类的系统综述。之前的工作既没有充分考虑基于语言的代码模型,也没有对现有的模型设计、下游任务和数据集进行全面的审查(Xu et al., 2022; Wu et al., 2022a; Allamanis et al., 2018)。为了建模和理解编程语言的语义,有必要讨论预训练和下游任务的可用数据集,以及如何设计合适的神经架构和有效的训练方案。此外,由于源代码本身具有丰富的结构信息(Xu等人,2022;Guo et al., 2021),如何在设计代码智能模型时提取并利用这些结构作为先验知识是一个至关重要的问题。这需要编程语言社区的理论和技术背景知识。Wu等人(2022b)综述了用于结构化代码理解的深度学习方法,并讨论了基于序列和基于图的建模技术。然而,这项工作更关注程序的结构方面,缺乏对语言模型和预训练策略的深入讨论。
为了连接NLP和PL社区的知识,本文将现有的用于代码智能的预训练语言模型分组为神经代码智能(NCI),并对该领域进行了系统的回顾。从预处理技术、模型架构和学习范式方面回顾了编程语言的神经建模技术。讨论了NCI的各种下游任务,以及用于训练和评估代码语言模型的可用数据集。探讨了将语言建模方法应用于代码智能的挑战和机遇。此外,我们在GitHub存储库中维护了一个NCI研究、新闻和工具的列表3。希望该工作可以阐明该领域当前的研究前景,帮助新人了解最近的研究进展,并为未来的研究提供见解。
代码语言模型预训练
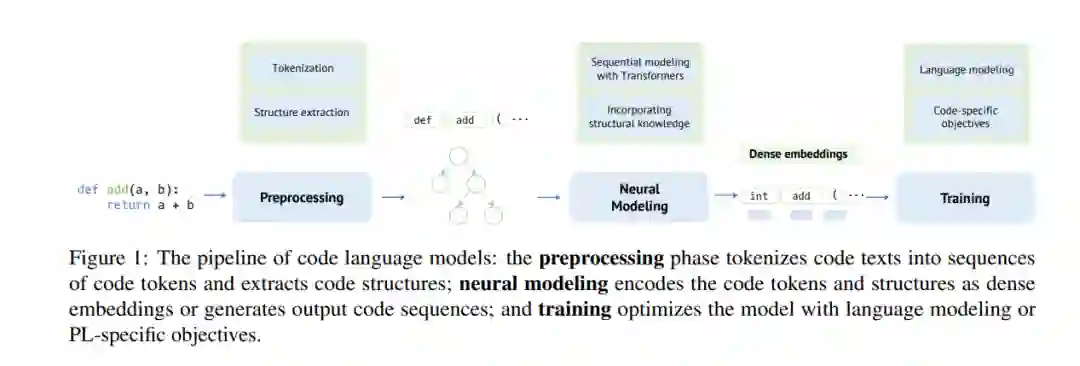
在本节中,我们将回顾代码语言模型的设计和训练。为了系统地回顾现有的文献,将代码语言建模方法拆分为一个由三个阶段组成的管道:预处理、顺序建模和训练。流程如图1所示,我们将依次介绍它们。
**预处理。**对于代码语言模型,输入将是预训练语料库中的源代码片段或稍后在下游数据集上的源代码片段。它必须首先对输入代码进行预处理,包括在代码上运行标记化,并可选地从编程语言中提取先验知识。
顺序建模。然后,它将预处理的结果(主要是标记序列)输入到语言模型中,将代码编码为密集表示,预测其属性,或从中生成代码序列。
预训练和微调。用无监督目标训练模型,并在下游任务上进一步微调。在预训练阶段,模型从大量的代码语料库中学习,没有人工注释,以获得源代码结构和语义的通用和可迁移的知识。然后,针对特定的下游任务对预训练模型进行微调。除了上述的预训练和微调策略,其他学习范式包括零样本、少样本和多任务学习也可以用于训练模型。