基于图片内容的深度学习图片检索(一)
(点击上方公众号,快速关注一起学AI)

基于内容的图片检索(CBIR:conten-based image retrieval)系统是根据图像的内容,在已有图像集中找出最相近的图片。这类系统的准确度和速度与两个东西直接相关:图像特征的提取与基于特征的匹配技术,即:
图片特征表达能力
近似邻近的查找
我们从检索系统的原理来看:
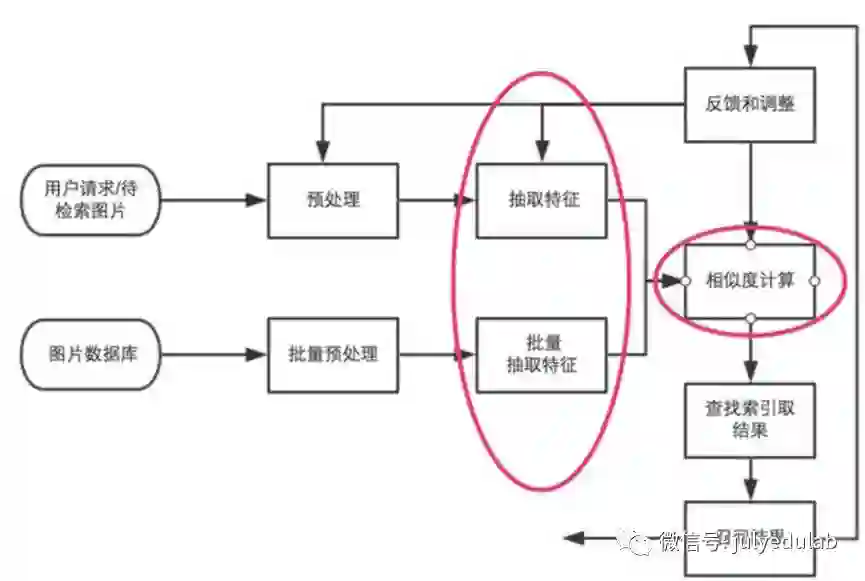
图像检索过程简单说来就是对图片数据库的每张图片抽取特征(一般形式为特征向量),存储于数据库中,对于待检索图片,抽取同样的特征向量,然后并对该向量和数据库中向量的距离,找出最接近的一些特征向量,其对应的图片即为检索结果。这其中我们可以看出红圈标注的就是整个系统的核心。
图像特征表达能力即特征向量的提取。图像的特征包括图像的文本特征、视觉特征,所谓图像的文本特征是指与图像相关的文本信息,比如图像的名称、对图像的注解文字等。图像的视觉特征是指图像本身所拥有的视觉信息,又可以进一步分为通用的视觉特征和领域特征,如颜色、纹理、形状等属于图像通用特征,而光谱特征则属于地理科学中遥感影像独有的特征。
从发展演变历程来看,根据图像检索系统所提取图像特征可分为两类,第一类即基于图像文本特征的检索,TBIR,第二类即基于图像视觉特征的内容检索,CBIR。
传统的TBIR技术应用于早期的图像检索,其研究主要在数据库领域中进行,首先对图像用文本进行手工注解,然后用基于文本的数据库管理系统进行检索。这种方法实现容易被广泛应用,但是它依赖于人对图像的注解,当图像数量急剧增大时,人工注解的方法所需工作量太大,而且不同人对同一幅图像的理解角度也是不同的,注解的主观性导致检索的查全率偏低。
20世纪70年代末是文本形式的图片标签,用关键字或普通文本对图片进行描述并存储,用户搜索图片时往往是用文字搜索。后来到了90年代初,基于内容的图片检索才真正出现,代替先前人工标注的是自动提取每幅图像的内容特征作为索引。
图像的内容包括图像的视觉信息等物理特征,还包括视觉特征所带来的高层语义特征。物理特征属于低层视觉信息,主要包括颜色、纹理、形状;语义信息属于图像的高层视觉信息,主要包括对象、空间关系、场景、行为、情感等图像内容。
CBIR的基本原理形式化定义:任给定一个检索图像示例P,计算其特征向量F=(F1,F2,F3,…Fn),其中Fi为图像的第i种特征;根据F检索图像特征索引库,得到与F距离最小的特征向量F’,则F’所对应的图像P’即为与P最相似的检索结果。CBIR系统主要包括用户界面、检索和存储系统三部分,其中图像特征索引技术和相似度匹配技术是系统的核心部分,直接影响着系统检索的查全率和查准率。其中检索和存储系统都要对原始图像进行特征向量计算,不同之处在于索引库的生成采用离线方式,而查询检索部分需要实时在线计算。匹配度的计算将决定检索结果的产生以及结果的排序,因此也具有十分重要的意义。除此之外,图像检索一般不是一蹴而就的过程,中间需要用户的干预和交互,应用反馈模型可以增强系统的理解能力,从而提高查准率。
无论是基于颜色、纹理、形状的检索方法,还是多特征综合的检索方法,都是属于对图像低层视觉内容表示的方法。基于颜色特征的图像检索技术将图像从计算机的角度看成一个个离散的像元点,像元之间是孤立的,只能表示图像在整体上所呈现的颜色一致性,而无法区分图像内部特征;基于纹理特征的检索是在颜色的基础上,考虑了相邻像元之间的关系,提出了规整度、粗糙度、方向度等来衡量图像的线性特征;基于形状的检索则将图像分割成封闭的区域,屏蔽图像中的诸如背景等细节元素,更加逼近人对图像的认知。
实际上图像是人对世界认知的间接表示,一幅图像充满了丰富语义信息,而不仅仅是颜色、纹理、形状,除此之外,图像上充满了一个个实体对象,对象之间在空间上存在某种关系,一幅或一系列图像可以表示一个具体的场景和动作,甚至某些图像蕴含了著作者丰富的感情色彩和寓意。用户在图像检索时总是存在一个大致的概念,这个概念建立在图像所描述的对象、场景事件以及所表达的情感等图像的高层语义上,包含了人对图像内容的理解,所以近年来出现了对高层的基于语义内容的图像检索技术的研究,成为解决图像简单视觉特征和用户语义之间存在的鸿沟的关键。
随后人们发觉这些视觉特征都是高维信息,需要的存储空间很大,随着图片数量越来越多,降维技术越来越多被人们关注。将一些高维数据降维成二值码(0或1),然后使用汉明距离来对比,是非常流行的做法。
但是随着深度学习的兴起,图片更高层次的特征提取成为可能,我们知道图片在进入DNN模型后就不断进行特征提取,深度学习是一个对图像特征提取和表达都有力的一个框架,其中每一层的中间数据都能表达图像某些维度的信息。因为现在我们可以用深度学习模型产生的特征来代替传统图像特征。
相似图片查找即近似邻近查找,我们已经有了图片的特征信息后,需要将待搜索图片特征信息和已知图片集中的图片特征信息进行对比,最终找到特征值最相似的图片。原理是清晰的,但我们以何种方式评判两个特征信息是否相近,有以何种方式进行评判会使速度最快,这就衍生了许多算法。
ANN(Approximate Nearest Neighbor):近似最邻近,一直都是很热的研究领域。因为在海量样本的情况下,遍历所有样本,计算距离,精确地找出最接近的Top K个样本是一个非常耗时的过程,尤其有时候样本向量的维度也相当高,因此有时候我们会牺牲掉一小部分精度,来完成在很短的时间内找到近似的top K个最近邻,也就是ANN。常见的ANN算法有局部敏感哈希(LSH:locality-sensitive hashing)。
LSH(局部敏感哈希)是一种衡量文本相似度的算法,也是ANN算法中最流行的一种。它主要是从海量的数据中挖掘出相似的数据,可以具体应用到文本相似度检测、网页搜索等领域。
LSH基本思想是:如果两个文本在原有数据空间相似,那么分别经过哈希函数转换后它们也具有很高的相似性;相反,如果它们本身是不相似的那么经过转换后,它们仍不具有相似性。LSH就是可以做到转换前后保持数据相似性的哈希函数。LSH哈希函数将相近的原始数据hash到一个hash桶中,那么在该数据集合中进行近邻查找就变得容易了,我们只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。
那具有怎样特点的hash functions才能够使得原本相邻的两个数据点经过hash变换后会落入相同的桶内?这些hash function需要满足以下两个条件:
1)如果d(x,y) ≤ d1, 则h(x) = h(y)的概率至少为p1;
2)如果d(x,y) ≥ d2, 则h(x) = h(y)的概率至多为p2;
其中d(x,y)表示x和y之间的距离,d1 < d2, h(x)和h(y)分别表示对x和y进行hash变换。
满足以上两个条件的hash functions称为(d1,d2,p1,p2)-sensitive。而通过一个或多个(d1,d2,p1,p2)-sensitive的hash function对原始数据集合进行hashing生成一个或多个hash table的过程称为局部敏感哈希。
使用LSH进行对海量数据建立索引(Hash table)并通过索引来进行近似最近邻查找的过程如下:
1. 离线建立索引
(1)选取满足(d1,d2,p1,p2)-sensitive的LSH hash functions;
(2)根据对查找结果的准确率(即相邻的数据被查找到的概率)确定hash table的个数L,每个table内的hash functions的个数K,以及跟LSH hash function自身有关的参数;
(3)将所有数据经过LSH hash function哈希到相应的桶内,构成了一个或多个hash table;
2. 在线查找
(1)将查询数据经过LSH hash function哈希得到相应的桶号;
(2)将桶号中对应的数据取出;(为了保证查找速度,通常只需要取出前2L个数据即可);
(3)计算查询数据与这2L个数据之间的相似度或距离,返回最近邻的数据;
前面已经提到过,有效的特征表达和相似度衡量对基于内容的图片检索(CBIR:content-based image retrieval)系统的检索性能来说是至关重要的,尽管数十年来,无数研究者都致力于此,但它仍是CBIR系统成功应用于商业界的公开挑战的最大问题之一。该问题中最关键的挑战常被认为是众所周知的“语义鸿沟”,“语义鸿沟”即机器能捕捉到的低级图片像素和人所理解的高层次的概念上(包含感情或知识)的感知之间的差异。从长期来看,在各种技术中机器学习是一个可能弥补“语义鸿沟”的最有前景的方向,因为消除语义鸿沟,从更高层次来看就是这就是更基础的挑战:人工智能,即如何构建和训练一个像人类一样处理现实世界的任务。下图就是将机器学习中的深度学习框架应用于CBIR应用的一个框架。
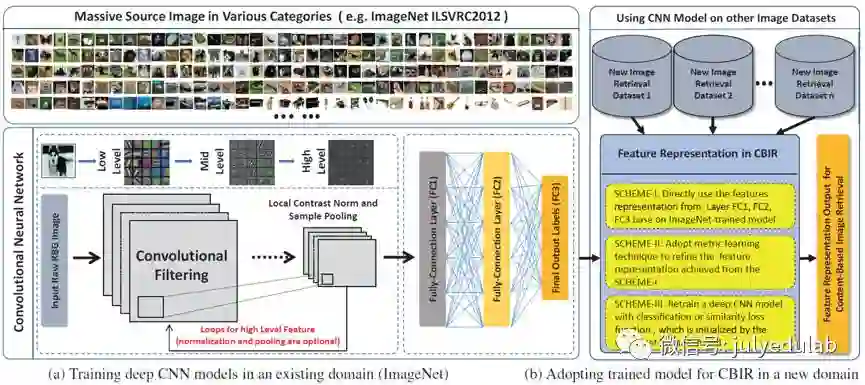
上图可以看出,CBIR应用主要是使用深度学习对图片的特征提取,有三种使用方式:1)直接使用;2)通过相似性学习来进行改善;3)通过重新训练模型来进行改善。
参考文献:Deep Learning for Content-Based Image Retrieval: AComprehensive Study.Ji Wan
http://blog.csdn.net/icvpr/article/details/12342159
欢迎投稿/提建议。
投稿请联系微信号:julyedukefu(稿件一经采用,你将收获高额稿酬&专属学习大礼包)




