

摘要
语音合成(TTS),也称为文本转语音,是一项重要的研究领域,旨在从文本生成自然的语音。近年来,随着工业需求的增加,TTS技术已从简单的人类语音合成发展到可控语音生成。这包括对合成语音中各种属性(如情感、韵律、音色和时长)的细粒度控制。此外,深度学习领域的进展,尤其是扩散模型和大语言模型,极大地提升了可控TTS的效果。本文全面综述了可控TTS的研究进展,涵盖了从基本控制技术到利用自然语言提示的方法,旨在为当前的研究状态提供清晰的理解。我们探讨了通用的可控TTS流程、面临的挑战、模型架构和控制策略,并提供了现有方法的全面分类。此外,我们还详细总结了数据集和评估指标,并探讨了可控TTS的应用和未来发展方向。据我们所知,本文是首次对新兴的可控TTS方法进行全面综述,既可以为学术研究人员提供有价值的资源,也可为行业从业者提供参考。
关键词
文本转语音、可控TTS、语音合成、TTS综述、大语言模型、扩散模型
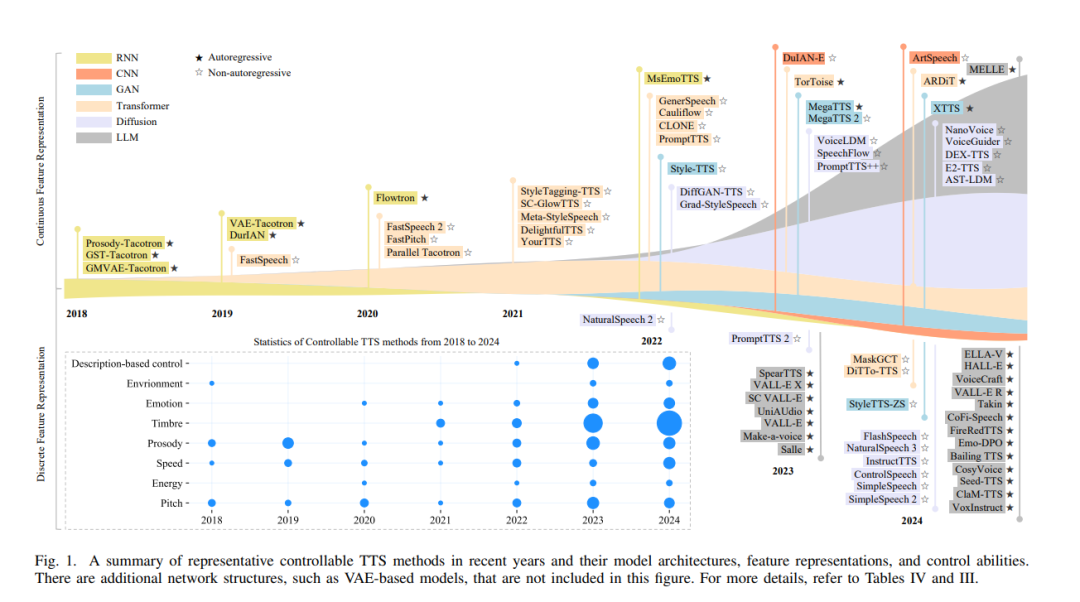
I. 引言
语音合成(TTS),也称为文本转语音,是一项长期发展的技术,旨在从文本生成类人语音[1][2],并广泛应用于我们的日常生活中,如健康护理[3][4]、个人助手[5]、娱乐[6][7]和机器人[8][9]等领域。近年来,随着大语言模型(LLM)驱动的聊天机器人(如ChatGPT[10]和Llama[11])的兴起,TTS技术因其自然性和便捷性,成为了人机交互中备受关注的技术。与此同时,能够对合成语音的属性进行细粒度控制(如情感、韵律、音色和时长)已成为学术界和工业界的热点研究方向,因其在多种应用中的广泛潜力。 在过去的十年里,深度学习[12]取得了显著进展,尤其是GPU等计算资源的指数级增长[13],促使TTS领域涌现出大量优秀的研究成果[14]–[17]。这些方法不仅能够生成更高质量的语音[14],还能够对生成的语音进行细粒度的控制[18]–[22]。此外,一些最新的研究开始尝试在多模态输入(如面部图像[23][24]、卡通[7]和视频[25])的支持下合成语音。随着开源大语言模型(LLMs)[11][26]–[29]的快速发展,部分研究者提出了通过自然语言描述生成可控语音的新方法[30]–[32],开创了生成定制语音的新途径。 此外,将语音合成与LLMs结合也成为近年来的热门研究方向[33]–[35]。随着TTS方法的不断发展,研究者迫切需要对当前的研究趋势,特别是可控TTS,进行全面的了解,以便在这一快速发展的领域中识别未来可能的研究方向。因此,迫切需要一篇关于TTS技术的最新综述。尽管已有几篇综述涵盖了基于参数的方法[36]–[41]和基于深度学习的TTS[42]–[48],但这些综述大多忽视了TTS的可控性问题,且没有覆盖近年来的最新进展,如基于自然语言描述的TTS方法。 本文提供了一篇全面且深入的综述,重点介绍现有及新兴的TTS技术,特别是可控TTS方法。图1展示了近年来可控TTS方法的发展,展示了其核心框架、特征表示和控制能力。本文的其余部分将简要对比本综述与先前的研究综述,概述可控TTS技术的发展历史,并从早期的里程碑到最新的先进技术,介绍可控TTS的研究进展。最后,我们介绍了本文的分类和组织结构。 A. 与现有综述的比较
已有几篇综述论文回顾了TTS技术,涵盖了从早期方法到最近的进展[36][37][40][49]。然而,本文是首次专门关注可控TTS。与以往的研究综述相比,本文的主要区别如下: * 不同的范围。Klatt等人[36]提供了关于共振峰、拼接和发音TTS方法的首个全面综述,重点关注文本分析。进入2010年代初,Tabet等人[49]和King等人[40]探索了基于规则、拼接和HMM的方法。随着深度学习的出现,许多基于神经网络的TTS方法应运而生。Ning等人[43]和Tan等人[42]分别对基于神经网络的声学模型和声码器进行了详细的综述,Zhang等人[50]则介绍了基于扩散模型的TTS技术的首个综述。然而,这些研究对TTS系统的可控性讨论较少。为填补这一空白,本文首次从可控性的角度对TTS方法进行了全面综述,深入分析了模型架构和合成语音的控制策略。 * 贴近当前需求。随着硬件(如GPU)和人工智能技术(如变换器、LLMs、扩散模型)的快速发展,TTS技术对可控性需求的迫切性日益增强,尤其在电影制作、游戏、机器人和个人助手等行业中有广泛应用。尽管这一需求日益增长,但现有的综述未充分关注TTS技术中的控制方法。为填补这一空白,本文对当前的可控TTS方法及其面临的挑战进行了系统分析,并全面理解了该领域的研究现状。 * 新见解与方向。本文通过全面分析可控TTS系统中的模型架构和控制方法,提出了新的见解。此外,我们深入探讨了各种可控TTS任务中的挑战,并探讨了“我们距离实现完全可控的TTS技术有多远?”这一问题,分析了当前TTS方法与工业需求之间的关系和差距。基于这些分析,我们确定了未来TTS技术研究的有前景的方向。
表I总结了代表性综述和本文在主要关注点和发布时间上的比较。 B. 可控TTS的发展历史
可控TTS旨在控制合成语音的各个方面,如音高、能量、速度/时长、韵律、音色、情感、性别或高层次风格。本小节简要回顾了可控TTS从早期方法到近年来的最新进展的历史。 * 早期方法。在深度神经网络(DNNs)流行之前,可控TTS技术主要基于基于规则、拼接和统计的方法。这些方法能够提供一定程度的定制和控制,尽管受限于底层模型和可用计算资源的局限性。
基于规则的TTS系统[51]–[54],如共振峰合成,是早期语音生成的主要方法之一。这些系统通过手工设计规则模拟语音生成过程,控制音高、时长和共振峰频率等声学参数,允许通过调整规则显式地操控韵律和语音的音素细节。 1. 拼接式TTS[55]–[58],在1990年代末和2000年代初主导了TTS领域,通过将预录音的语音片段(如音素或双音素)拼接在一起合成语音[59]。这些方法通过拼接过程中调整音高、时长和音量来改变韵律,也可以通过选择不同说话人的语音单元来实现有限的声音定制。 1. 参数化方法,尤其是基于HMM的TTS[60]–[65],在2000年代末逐渐成为主流。这些系统通过建模语言特征和声学参数之间的关系,为控制韵律、音高、语速和音色提供了更多灵活性。一些HMM系统还支持说话人适应[66][67]和语音转换[68][69],在一定程度上实现了语音克隆。此外,一些方法还能够有限地控制情感[60][70]–[72]。这些方法相比拼接式TTS占用更少的存储空间,并且能提供更平滑的语音单元过渡。 * 基于神经网络的合成。随着深度学习的出现,基于神经网络的TTS技术为该领域带来了巨大的进步,使得语音合成更加灵活、自然和富有表现力。与传统方法不同,基于神经网络的TTS通过DNN建模输入文本和语音之间的复杂关系,从而实现对各种语音特征的细粒度控制。早期的神经TTS系统如WaveNet[73]和Tacotron[74]为可控性奠定了基础。
韵律控制:韵律特征如节奏和语调的控制对于生成富有表现力和语境适应的语音至关重要。基于神经网络的TTS模型通过显式条件化或学习的潜在表示来实现韵律控制[15][75]–[78]。 1. 说话人控制:通过说话人嵌入或适应技术,基于神经网络的TTS在说话人控制方面也得到了显著提升[79]–[82]。 1. 情感控制:情感可控的TTS[20][22][31][32][83]已经成为热门研究话题,得益于DNN强大的建模能力,能够合成具有特定情感色彩(如快乐、悲伤、愤怒或中性)的语音
基于LLM的合成
在本节中,我们特别关注基于 LLM(大语言模型) 的语音合成方法,因为与其他基于神经网络的TTS方法相比,LLM具有更强的上下文建模能力。LLM(如 GPT [97]、T5 [99] 和 PaLM [100])已经通过其生成连贯的、上下文感知的文本的能力,革新了各种 自然语言处理(NLP) 任务。近年来,LLM的应用已经扩展到 可控TTS技术 中 [17],[101]–[104]。例如,用户可以通过描述语音的特征来合成目标语音,例如:“一个年轻女孩用快乐的语气说‘我真的很喜欢,谢谢!’”,使得语音生成变得更加直观和用户友好。具体而言,LLM能够在句子中检测情感意图(例如,“我很激动”→快乐,“这真不幸”→悲伤)。检测到的情感会被编码为TTS模型的辅助输入,从而调节声学特征,如韵律、音高和能量,使其与所表达的情感相匹配。通过利用LLM在理解和生成丰富上下文信息方面的能力,这些系统可以对语音的各种属性(如韵律、情感、风格和说话人特征)实现更精细的控制 [31],[105],[106]。将LLM集成到TTS系统中,代表了一个重要的进步,使得语音合成变得更加动态和富有表现力。
本文结构
本文首先对可控TTS技术进行了全面和系统的回顾,重点关注模型架构、控制方法和特征表示。为建立基础理解,本综述在第二节介绍了TTS管道。虽然本文的重点仍然是可控TTS,但第三节回顾了对该领域发展具有重要影响的经典的不可控TTS工作。第四节深入调查了可控TTS方法,分析了它们的模型架构和控制策略。第五节提供了数据集和评估指标的全面回顾。第六节对实现可控TTS系统所面临的挑战进行了深入分析,并讨论了未来的研究方向。第七节探讨了可控TTS技术的更广泛影响,并确定了有前景的未来研究方向,最后在第八节作出结论。


