

检索增强生成(RAG)是一种先进的技术,旨在解决人工智能生成内容(AIGC)面临的挑战。通过将上下文检索与内容生成相结合,RAG提供了可靠且最新的外部知识,减少了幻觉现象,并确保在广泛任务中的相关上下文。然而,尽管RAG取得了成功并展现出潜力,最近的研究表明,RAG范式也带来了新的风险,包括鲁棒性问题、隐私问题、对抗性攻击以及问责问题。解决这些风险对RAG系统的未来应用至关重要,因为它们直接影响到系统的可信度。尽管已经开发了多种方法来提高RAG方法的可信度,但目前缺乏一个统一的研究视角和框架。因此,本文旨在填补这一空白,通过提供一条全面的路线图来发展可信赖的RAG系统。我们将讨论集中在五个关键视角上:可靠性、隐私、安全性、公平性、可解释性和问责制。对于每个视角,我们提出了一个通用框架和分类法,提供了一种结构化的方法来理解当前的挑战、评估现有的解决方案,并识别有前景的未来研究方向。为了鼓励更广泛的采用和创新,我们还强调了可信赖的RAG系统在下游应用中的重要影响。如需更多关于本次调查的信息,请访问我们的GitHub仓库*。
1 引言
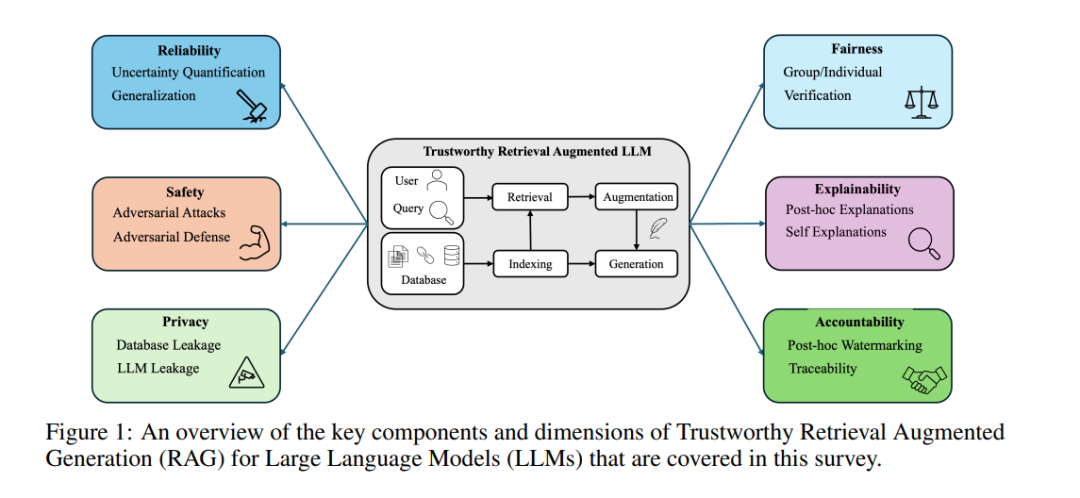
检索增强生成(RAG)已成为解决大型语言模型(LLM)面临的挑战的有前途的技术,例如幻觉现象、依赖过时的知识和缺乏可解释性[55, 223]。通过将外部信息融入生成上下文中,RAG提高了生成内容的准确性和可靠性。信息的时效性还使得模型能够通过最小化训练成本,减少对整个系统的广泛再训练需求,从而保持与时俱进。这些优势对现实世界的应用具有深远的意义。例如,RAG已在医疗问答[195, 216, 162]、法律文书起草[190, 132]、教育聊天机器人[172]和财务报告摘要[208]等领域中得到有效应用,因其在各个领域的适应性。可信度的定义通常取决于讨论的上下文[102, 191, 95, 58, 36, 107, 219, 105]。在机器学习和人工智能的背景下,可信的AI系统必须具备使其值得信赖的特征。2022年,美国国家标准与技术研究院(NIST)发布了可信AI的指南,从多个角度定义了可信度[169]:可靠性、隐私性、可解释性、公平性、问责制和安全性。可靠性确保系统在各种条件下始终如一地表现并产生准确的结果。它包括解决诸如不确定性量化和鲁棒性泛化等挑战,这对于提高系统的可靠性至关重要。例如,在法律案例分析系统中,可靠性涉及平衡不确定性量化(例如,检索到的法律引用的置信度和检索到的法律引用数量)和鲁棒性泛化(例如,应用先例到新案件)以确保律师在案件准备过程中不会受到误导。隐私性侧重于保护用户数据,确保对个人信息的控制。由于RAG已应用于医疗等敏感领域,因此保护患者信息至关重要。例如,当医疗助手检索医疗记录或生成治疗建议时,系统必须防止数据泄露,确保嵌入语言模型中的敏感患者信息保持安全。可解释性强调需要透明的决策过程,使用户能够理解输出是如何生成的。例如,基于RAG的大学招生助手应提供清晰的解释,说明学生档案如何与课程要求匹配,提供用户可以轻松理解和验证的见解。公平性侧重于最小化检索和生成阶段引入的偏见,因为这些偏见可能在高风险领域中显著影响结果。近期的进展包括使用重新排序方法来减轻检索中的社会偏见,以及微调技术来平衡人口公平性与系统性能。例如,招生助手必须确保公平对待所有申请者,解决潜在的性别、种族或社会经济地位等偏见问题。问责制涉及AI治理,包括政策制定和法律实施,但也涉及诸如追踪AI生成内容的来源和过程等技术方面。例如,确保新闻生成系统能够追踪其检索的来源,以提高内容的问责制并减少错误信息,是至关重要的。像内容水印这样的技术有助于识别检索信息的来源及生成过程,为未来的验证提供清晰的审计轨迹。安全性涉及系统防止和减轻伤害的能力,特别关注防御对抗性攻击并减少恶意行为者带来的风险。当前的聊天机器人系统通常与高风险用户互动,例如青少年,这些用户可能不知情地暴露于有害或不当的内容中。对抗性攻击和越狱尝试可能会改变聊天机器人的行为,导致错误信息、不当响应,甚至危险建议。因此,构建强大的保障措施,如对抗性训练和伦理防护措施,对于确保安全并防止伤害至关重要。尽管RAG系统近期取得了成功,但关于其可信度的担忧逐渐成为一个日益辩论的话题。首先,RAG系统容易受到可靠性问题的影响,因为开发者必须确保输出准确地依赖于检索到的内容[98, 55]。其次,依赖外部数据库带来了新的攻击面,使系统暴露于一系列对抗性威胁中[198, 45, 194, 214, 215, 227]。因此,需要进行鲁棒性改进以保障系统安全。第三,RAG系统在数据隐私方面带来了新的挑战[158]。外部数据库的集成引入了额外的泄露渠道,必须确保RAG系统在生成过程中不会泄露外部数据库和底层大型语言模型训练数据中的私人信息。此外,RAG系统也可能面临公平性问题[159],无论是在检索过程还是生成过程中。检索数据的选择和使用方式可能显著影响生成内容的公平性。生成过程中隐性偏见可能也会受到检索内容的影响,尤其是当信心提高时[73]。最后,随着大型语言模型(LLM)的崛起和潜在应用,问责制成为政策制定者关注的重点,特别是在使用RAG系统时。尽管已有进展,但这些挑战显著限制了RAG系统在现实场景中的广泛应用,尤其是在高风险领域,如医疗、法律咨询和教育等[195, 216, 190, 172]。因此,在推动RAG系统发展的同时,融入可信度视角至关重要。由于可信AI的重要性,已有大量研究推动了RAG在大型语言模型中的应用,涵盖了异质的定义、巨大的实施差异和不一致的评估指标。然而,目前尚缺乏对这一领域现有进展和挑战的系统性回顾。为组织各个视角,本文对大型语言模型中可信RAG的现状进行了系统讨论。相关论文清单可在我们的GitHub仓库中查阅†。

