

摘要—视觉目标跟踪(VOT)是计算机视觉领域一个具有吸引力且重要的研究方向,其目标是在视频序列中识别和跟踪特定目标,且目标对象是任意的、与类别无关的。VOT技术可以应用于多种场景,处理多种模态的数据,如RGB图像、热红外图像和点云数据。此外,由于没有单一传感器能够应对所有动态和变化的环境,因此多模态VOT也成为了研究的重点。本文全面综述了近年来单模态和多模态VOT的最新进展,特别是深度学习方法的应用。具体而言,本文首先回顾了三种主流的单模态VOT,包括RGB图像、热红外图像和点云跟踪。特别地,我们总结了四种广泛使用的单模态框架,抽象出其架构,并对现有的继承方法进行了分类。接着,我们总结了四种多模态VOT,包括RGB-深度、RGB-热红外、RGB-LiDAR和RGB-语言。此外,本文还呈现了所讨论模态在多个VOT基准测试中的对比结果。最后,我们提出了建议和深刻的观察,旨在激发这一快速发展的领域的未来发展。 关键词—视觉目标跟踪,深度学习,综述,单模态,多模态
https://www.zhuanzhi.ai/paper/2edd0971ae625f759822052af4d569fd
1 引言
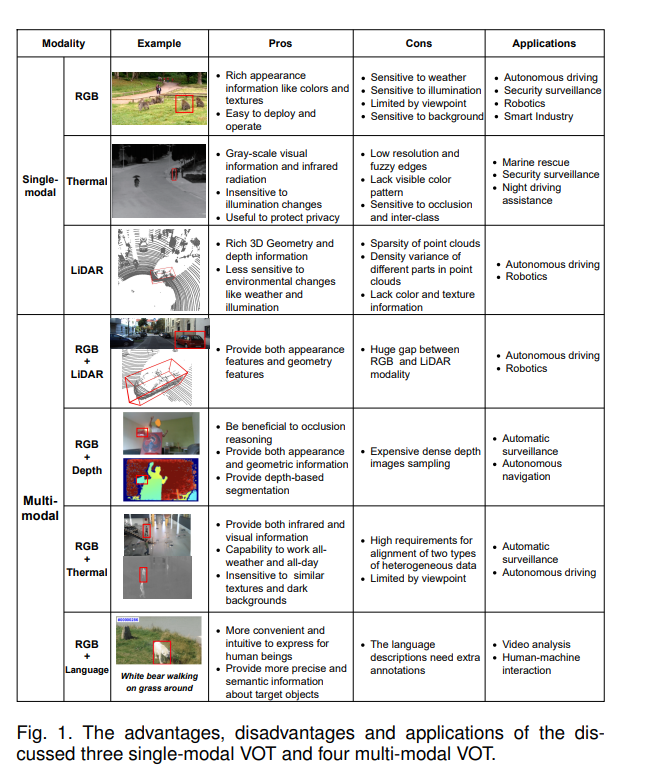
视觉目标跟踪(VOT)是过去几十年来计算机视觉领域的一个高度活跃的研究课题,因其在视频监控 [1]、[2]、[3]、自动驾驶 [4]、[5]、移动机器人 [6]、[7]、人机交互 [8]、[9] 等广泛场景中的重要应用而受到关注。VOT任务的定义是:给定目标在第一帧中的边界框位置,跟踪器需要在随后的所有帧中持续且鲁棒地识别和定位该目标,其中目标可以是任意实例且不依赖于类别。这个任务非常具有挑战性,因为:1)目标可能经历诸如形变、旋转、尺度变化、运动模糊和视野丢失等复杂的外观变化;2)背景可能带来诸如光照变化、相似物体干扰、遮挡和杂乱等无法控制的影响;3)视频捕捉设备可能会震动和移动。 作为计算机视觉中的一项核心任务,VOT有多种数据模态可供选择。最常见的模态是RGB视频,因其普及和易获取性,吸引了大量研究者关注这一任务。RGB模态的VOT提供了在图像坐标系下的大致目标位置,并通过二维边界框为许多高级图像分析任务奠定了基础,例如姿态估计、步态/活动识别、细粒度分类等。基于RGB的VOT的演进 [2]、[10]、[11]、[12] 是持久且历史悠久的,随着深度学习 [13]、[14]、[15]、[16]、[17] 和大规模数据集 [18]、[19]、[20] 的出现,这一进展进一步加速。本文主要关注过去十年中的方法,特别是基于深度神经网络(DNN)的方法。根据其工作流程,我们将主流的RGB跟踪器分为四类:判别性相关滤波器(DCF) [17]、[21],Siamese跟踪器 [22]、[23]、[24],实例分类/检测(ICD) [25]、[26]、[27] 和单流变换器(OST) [1]、[28]、[29]。为了便于说明,图3展示了这四种基于深度学习的框架及其最简化的组件。前两种框架在过去十年中非常流行,而后两种则较少被提及,甚至在以往的综述中没有出现过,因为ICD不像DCF和Siamese那么常见,OST则是一个自2022年才出现的新框架。 另一方面,RGB模态的缺点也非常明显,应用场景受到限制。首先,它在夜间和恶劣天气(如雨天和雪天)下的表现不尽如人意。在这些严酷的视觉条件下,可以使用基于热红外(TIR)的VOT [30]、[31]、[32],通过TIR摄像机捕捉来自生物体的热辐射,在没有光照的情况下跟踪目标。其次,缺乏深度信息使得单一的RGB模态VOT无法感知三维几何和定位信息,这在自动驾驶和移动机器人等应用场景中尤为重要。最近,基于LiDAR的VOT [5]、[33]、[34]、[35] 应运而生,解决了这一问题,通过探索3D点云的内在几何结构来感知目标的深度。LiDAR点的几何结构有助于感知目标物体的深度,从而提供精确的3D形状和位置。因此,本文还概述了两种单模态VOT方法(基于TIR和LiDAR的)。此外,容易发现这些模态之间的共同框架,以便更好地理解。例如,基于TIR的跟踪器通常遵循DCF和Siamese框架,因为TIR数据格式与RGB图像非常相似。同样,基于LiDAR的VOT借用了RGB模态中的Siamese框架,并将其发展为主导3D跟踪领域的方法。 此外,由于不同的单模态VOT各有优缺点,因此也提出了融合多模态信息的跟踪器,具有提高精度和鲁棒性的潜力。更具体地说,融合意味着将两种或多种模态的信息结合起来进行目标跟踪。例如,TIR传感器对光照变化、伪装和物体姿态变化不敏感,但在人群中区分不同人的TIR轮廓会比较困难。另一方面,RGB传感器则具有相反的特性。因此,直观地将这两种模态进行融合,可以互相补充 [36]、[37]、[38]。此外,融合选择可能根据不同的应用有所不同。例如,RGB-LiDAR [39]、[40] 可以是适用于机器人跟随的良好选择,因其需要准确的3D信息;而RGB-语言VOT [8]、[9]、[41] 则适用于人机交互。随着实际需求的增加,VOT领域的一些研究者已转向集成多种模态,以构建鲁棒的跟踪系统。 现有关于VOT的综述论文主要集中在单一RGB模态方法的不同方面和分类 [42]、[43]、[44]、[45]、[46]、[47]、[48]、[49]、[50]。例如,最近的综述 [46] 将现有的RGB跟踪器分为生成性跟踪器和判别性跟踪器。Javed等人 [43] 介绍了两种广为人知的RGB基VOT框架,即DCF和Siamese。然而,这些以往的工作未包含最新流行的基于变换器的方法,而这些方法不仅建立了新的最先进的性能,还带来了许多有洞察力的研究方向。此外,ICD框架的展示也不够充分。而且,关于多模态VOT的综述非常少,要么仅讨论了两种模态(RGB-Depth和RGB-TIR) [51],要么侧重于多线索特征的融合(如颜色、梯度、轮廓、空间能量、热轮廓等) [52]、[53]。在过去五年里,我们目睹了多模态VOT的显著进展。同时,新的研究方向如基于LiDAR的VOT、RGB-LiDAR VOT和RGB-语言VOT相继出现。然而,这些研究在以往的VOT综述中未被很好地总结。 本文从数据模态的角度,系统地回顾了VOT方法,考虑了单模态VOT和多模态VOT的最新发展。我们在图1中总结了所回顾的模态及其代表性示例、优缺点和应用。具体而言,我们首先概述了三种常见的单模态VOT方法:基于RGB、基于TIR和基于LiDAR的。接下来,我们介绍了四种多模态融合跟踪方法,包括RGB-Depth、RGB-TIR、RGB-LiDAR和RGB-Language。除了算法外,我们还报告并讨论了不同模态的VOT基准数据集及其结果。本文的主要贡献总结如下:
- 我们从数据模态的角度全面回顾了VOT方法,包括三种常见的单模态(RGB、TIR、LiDAR)和四种多模态(RGB-Depth、RGB-TIR、RGB-LiDAR、RGB-Language)。据我们所知,这是第一篇综述工作,展示了新兴的基于LiDAR、RGB-LiDAR和RGB-Language的VOT方法。
- 我们总结了四种广泛使用的基于深度神经网络的单模态跟踪器框架,抽象出其架构并展示了其对应的定制继承者。
- 我们提供了对VOT社区中300多篇论文的全面回顾,涉及最新和先进的方法,为读者提供了最先进的技术和工作流程。
- 我们对不同模态的现有方法在广泛使用的基准测试中的表现进行了广泛比较,并最终给出了深刻的讨论和有前景的未来研究方向。
本文的其余部分安排如下:第2节介绍现有的VOT综述,并阐述本文的不同方面。第3节回顾了使用不同单一数据模态的VOT方法及其比较结果。第4节总结了多模态VOT方法。第5节介绍了不同模态的VOT数据集。最后,第6节讨论了VOT的未来发展潜力。由于篇幅限制,部分结果表格,包括单模态和所有多模态结果,已移至附录A,且不同模态的VOT数据集介绍见附录B。

