![]()
摘要:基于自然语言处理中的语言模型基础,下一个令牌预测(NTP)已经发展成为一个多功能的训练目标,广泛应用于各类模态的机器学习任务,并取得了显著的成功。随着大型语言模型(LLMs)发展到能够统一文本模态中的理解和生成任务,近期研究表明,来自不同模态的任务也可以有效地在NTP框架内进行 encapsulate(封装),将多模态信息转化为令牌,并根据上下文预测下一个令牌。本文综述提出了一个全面的分类法,通过NTP的视角统一了多模态学习中的理解和生成任务。该分类法涵盖了五个关键方面:多模态令牌化、多模态NTP模型架构、统一任务表示、数据集与评估以及开放挑战。该新分类法旨在帮助研究人员探索多模态智能。相关的GitHub仓库收集了最新的论文和资源库,网址为:https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction。
![]()
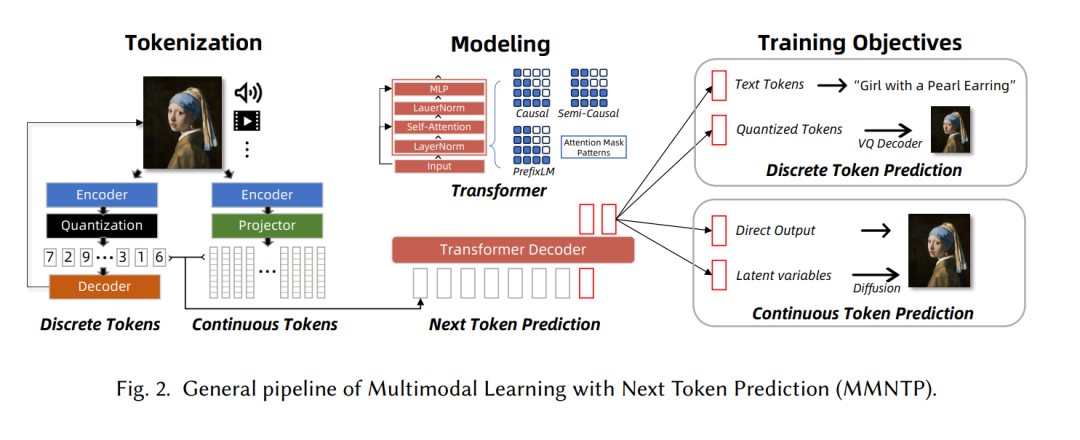
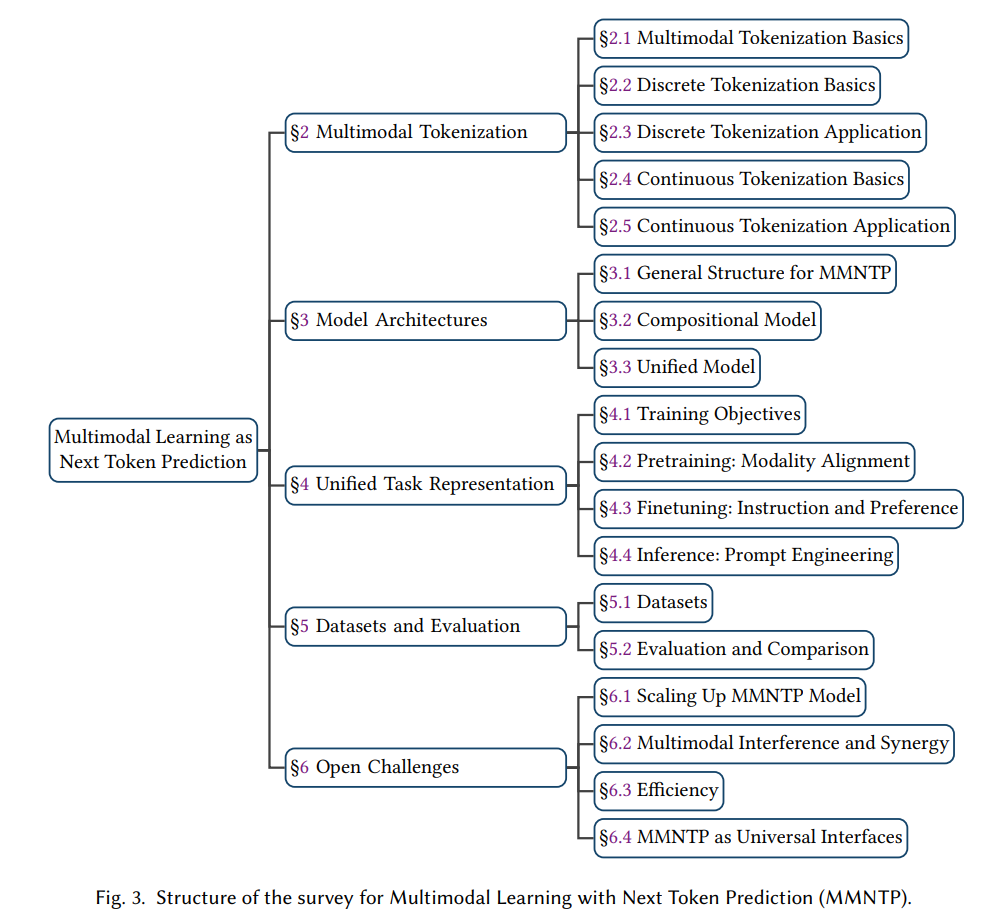
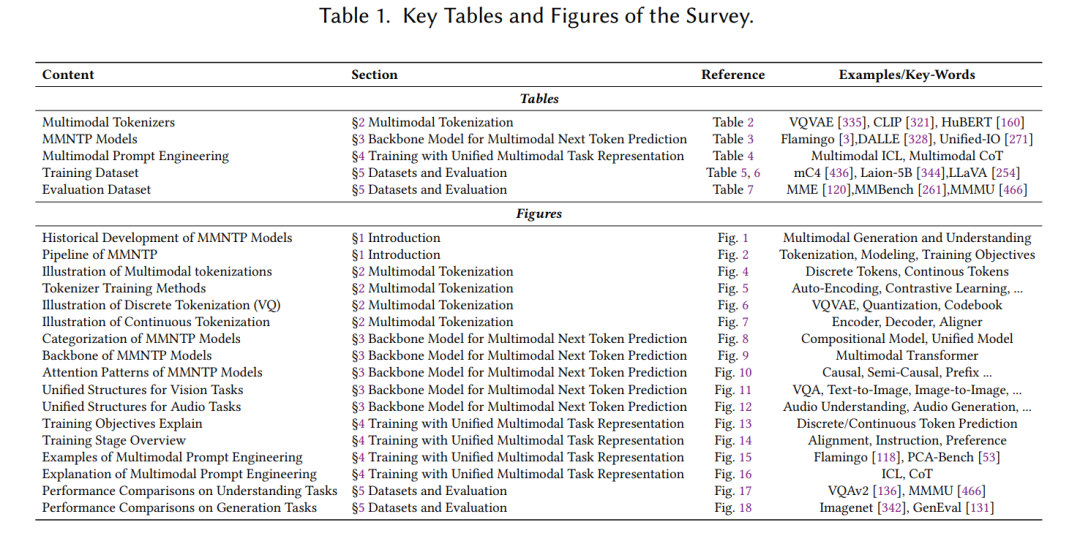
1 引言人类与宇宙的互动是一幅挂毯,交织着各种模态的线条。人类可以看到并绘制画作,阅读并创作史诗,聆听并作曲,触摸并雕刻英雄,沉思并做出行动。这些模态——诸如视觉、声音和语言等特定信息类型——是人类解释和回应世界的渠道。这种多维度的互动凸显了人类体验中感知与回应的紧密关系。作为人工智能(AI)研究中的一个专门领域,多模态学习致力于创建能够理解和生成各种多模态信息的系统[16]。在人工智能领域,已经出现了范式的转变,从专门为单一任务训练的单模态模型,转向处理多样化任务的多功能多模态模型[150]。这一转变主要归功于大型语言模型(LLMs)在自然语言处理(NLP)领域的进展,例如GPT-3 [34]、ChatGPT [300] 和LLaMA [378],它们通过一个统一的下一个令牌预测(NTP)目标,统一了多个自然语言理解和生成任务。NTP的原始任务是基于前面的令牌提供的上下文,预测给定文本序列中的下一个令牌(可以是一个词、子词或字符)。在规模法则研究的视角下,NTP范式已被证明是可扩展的,前提是有充足的数据和计算资源[192, 472]。与此同时,研究人员已探索将非文本输入和输出模态融入大型语言模型,这激发了社区的兴趣,开发具有跨模态任务能力的大型多模态模型(LMMs)[72, 448]。为了更好地理解基于NTP的LMM的历史发展,我们在图1中展示了一个时间线,按模型的理解或生成能力以及不同模态进行分类。 ![]() 在图2中,我们以图像模态为例,说明了多模态学习与NTP(MMNTP)的工作流程。该过程可以分为三个关键组件:令牌化、建模和训练目标,接下来将在本文的其余部分进行详细说明和讨论。对于视觉模态,图像和视频理解能力已经在大型视觉语言模型中得到了证明,如GPT4-V [301]、QwenVL [12]、LLaVA [254]、phi 3.5-Vision [1] 和Gemini [370],同时Emu [363]和Chameleon [369]展示了可以通过NTP方式实现视觉生成。类似地,基于NTP的模型如GPT4-o和Moshi [105, 302]已经实现了端到端的音频理解和生成。为了赋予大型语言模型(LLMs)视觉理解能力,开创性的研究如Flamingo [3]、BLIP2 [227]、GPT4V [301]、MiniGPT4 [509] 和LLaVA [254]表明,LLMs可以通过简单的令牌化模块(如视觉编码器CLIP [321]或简单的线性投影[18])轻松适应处理多模态输入,如图像和视频。随后,这些模型基于图像-查询-回答三元组,使用相同的NTP目标进行多模态指令微调。随着大型语言模型在自然语言处理领域架起了理解与生成任务的桥梁,扩展其能力以生成多模态输出成为了一个广泛关注的话题。近期的进展包括GPT-4o [302],它能够理解和生成文本、音频和图像,使用一个统一的多模态LLM。我们还见证了开源社区的巨大进展。在视觉模态方面,Chameleon [369]和Emu3 [400]是两种独特的多模态模型,统一了语言和图像模态中的理解和生成。对于音频,Moshi [105]能够以NTP方式执行任务,如自动语音识别(ASR)和语音生成,基于预训练的LLM。作为一种通用且基础的方法,NTP也在多样化领域如科学AI(例如设计生物学中的蛋白质[20]和化学中的分子结构[118])中具有潜力。为了使用NTP方法生成多模态内容,必须认识到,与语言不同,语言是由离散符号构成的,多模态数据如图像和声音本质上存在于连续空间中。解决这一挑战的常用技术是量化。向量量化(VQ)是一种经典方法,通过离散向量分布建模连续多模态数据的概率密度函数[138, 306],该方法与NTP建模非常契合。随着深度学习的兴起,神经网络VQ方法如VQVAE [385] 和VQGAN [112]被开发出来,为将视觉和音频生成与NTP关联奠定了基础。借助这些VQ方法和语言建模任务,涌现出了大量重要工作。例如,创新的系统如DALL-E [327]、CogView [91]、CM3Leon [458]、Parti [452]、Muse [43]、VideoPoet [199]、LVM [13]、Chameleon [369]和Infinity [149]等,这些方法通常依赖外部模型,如VQGAN解码器进行图像生成,使得它们的生成方法成为一种间接的多模态生成方式。与此同时,也有一些探索采用NTP目标,直接在连续空间(如VAE的潜在空间[381])中生成图像,或者通过模拟扩散过程[233, 507]来实现。与间接方法不同,只有少数几项计划(如ImageGPT [55])通过从零开始预测像素进行直接的多模态生成。此外,NTP模型还可以通过结合各种外部模型来增强多模态生成。值得注意的例子包括Emu [362]、MiniGPT5 [506]和CoDi2 [368],这些方法利用NTP框架结合外部扩散模型进行图像生成,展示了另一种间接的多模态生成方式。我们已经涵盖了能够理解或生成跨模态信息的强大模型,这些模型都处于NTP范式内。然而,开发一个既能理解又能生成跨多个模态信息的单一模型,类似于人类的能力,仍然是追求人工通用智能(AGI)过程中的一个引人入胜的目标。最近,出现了一种新的研究趋势,专注于开发统一多模态理解和生成的LMMs,在NTP范式内。例如,Unified-IO [269, 270]、Chameleon [369]、Transfusion [507]、Show-o [422]、Moshi [106]和Emu3 [401]等是一些著名的例子。统一理解和生成面临着独特的挑战,包括模态的多样性以及如何解决它们之间的冲突。我们将在第六节中进一步讨论这些问题。1.1 综述的整体结构本综述的结构如图3所示。第二节聚焦于多模态令牌化,强调令牌化作为原始多模态数据与其表示之间的桥梁的重要性,并区分了使用向量量化的离散令牌与连续令牌。第三节深入探讨了NTP的多模态骨干模型,指出使用自回归模型(通常类似于大型语言模型)来捕捉多模态令牌,并利用不同的注意力掩码来处理不同模态,以考虑它们的特定特征。第四节讨论了统一多模态任务表示的训练,解释了从离散到连续令牌预测的训练目标,通过VQ解码器或直接生成条件来实现多模态输出,支持如扩散模型或VAE等模型的生成条件。该节还涉及了从LLM研究中借用的多模态NTP模型的提示工程技术,如上下文学习(In-Context Learning)和链式推理(Chain-of-Thought)。第五节介绍了数据集和评估指标,并指出NTP模型在理解和生成任务中的优越表现。最后,第六节概述了多模态NTP研究中尚未解决的挑战,如扩大规模、多模态NTP的自发能力、模态特定偏差、模态间干扰,以及多模态NTP作为通用接口的问题,并讨论了缓解这些挑战的方法。表1概述了我们综述中的关键表格和图示。
在图2中,我们以图像模态为例,说明了多模态学习与NTP(MMNTP)的工作流程。该过程可以分为三个关键组件:令牌化、建模和训练目标,接下来将在本文的其余部分进行详细说明和讨论。对于视觉模态,图像和视频理解能力已经在大型视觉语言模型中得到了证明,如GPT4-V [301]、QwenVL [12]、LLaVA [254]、phi 3.5-Vision [1] 和Gemini [370],同时Emu [363]和Chameleon [369]展示了可以通过NTP方式实现视觉生成。类似地,基于NTP的模型如GPT4-o和Moshi [105, 302]已经实现了端到端的音频理解和生成。为了赋予大型语言模型(LLMs)视觉理解能力,开创性的研究如Flamingo [3]、BLIP2 [227]、GPT4V [301]、MiniGPT4 [509] 和LLaVA [254]表明,LLMs可以通过简单的令牌化模块(如视觉编码器CLIP [321]或简单的线性投影[18])轻松适应处理多模态输入,如图像和视频。随后,这些模型基于图像-查询-回答三元组,使用相同的NTP目标进行多模态指令微调。随着大型语言模型在自然语言处理领域架起了理解与生成任务的桥梁,扩展其能力以生成多模态输出成为了一个广泛关注的话题。近期的进展包括GPT-4o [302],它能够理解和生成文本、音频和图像,使用一个统一的多模态LLM。我们还见证了开源社区的巨大进展。在视觉模态方面,Chameleon [369]和Emu3 [400]是两种独特的多模态模型,统一了语言和图像模态中的理解和生成。对于音频,Moshi [105]能够以NTP方式执行任务,如自动语音识别(ASR)和语音生成,基于预训练的LLM。作为一种通用且基础的方法,NTP也在多样化领域如科学AI(例如设计生物学中的蛋白质[20]和化学中的分子结构[118])中具有潜力。为了使用NTP方法生成多模态内容,必须认识到,与语言不同,语言是由离散符号构成的,多模态数据如图像和声音本质上存在于连续空间中。解决这一挑战的常用技术是量化。向量量化(VQ)是一种经典方法,通过离散向量分布建模连续多模态数据的概率密度函数[138, 306],该方法与NTP建模非常契合。随着深度学习的兴起,神经网络VQ方法如VQVAE [385] 和VQGAN [112]被开发出来,为将视觉和音频生成与NTP关联奠定了基础。借助这些VQ方法和语言建模任务,涌现出了大量重要工作。例如,创新的系统如DALL-E [327]、CogView [91]、CM3Leon [458]、Parti [452]、Muse [43]、VideoPoet [199]、LVM [13]、Chameleon [369]和Infinity [149]等,这些方法通常依赖外部模型,如VQGAN解码器进行图像生成,使得它们的生成方法成为一种间接的多模态生成方式。与此同时,也有一些探索采用NTP目标,直接在连续空间(如VAE的潜在空间[381])中生成图像,或者通过模拟扩散过程[233, 507]来实现。与间接方法不同,只有少数几项计划(如ImageGPT [55])通过从零开始预测像素进行直接的多模态生成。此外,NTP模型还可以通过结合各种外部模型来增强多模态生成。值得注意的例子包括Emu [362]、MiniGPT5 [506]和CoDi2 [368],这些方法利用NTP框架结合外部扩散模型进行图像生成,展示了另一种间接的多模态生成方式。我们已经涵盖了能够理解或生成跨模态信息的强大模型,这些模型都处于NTP范式内。然而,开发一个既能理解又能生成跨多个模态信息的单一模型,类似于人类的能力,仍然是追求人工通用智能(AGI)过程中的一个引人入胜的目标。最近,出现了一种新的研究趋势,专注于开发统一多模态理解和生成的LMMs,在NTP范式内。例如,Unified-IO [269, 270]、Chameleon [369]、Transfusion [507]、Show-o [422]、Moshi [106]和Emu3 [401]等是一些著名的例子。统一理解和生成面临着独特的挑战,包括模态的多样性以及如何解决它们之间的冲突。我们将在第六节中进一步讨论这些问题。1.1 综述的整体结构本综述的结构如图3所示。第二节聚焦于多模态令牌化,强调令牌化作为原始多模态数据与其表示之间的桥梁的重要性,并区分了使用向量量化的离散令牌与连续令牌。第三节深入探讨了NTP的多模态骨干模型,指出使用自回归模型(通常类似于大型语言模型)来捕捉多模态令牌,并利用不同的注意力掩码来处理不同模态,以考虑它们的特定特征。第四节讨论了统一多模态任务表示的训练,解释了从离散到连续令牌预测的训练目标,通过VQ解码器或直接生成条件来实现多模态输出,支持如扩散模型或VAE等模型的生成条件。该节还涉及了从LLM研究中借用的多模态NTP模型的提示工程技术,如上下文学习(In-Context Learning)和链式推理(Chain-of-Thought)。第五节介绍了数据集和评估指标,并指出NTP模型在理解和生成任务中的优越表现。最后,第六节概述了多模态NTP研究中尚未解决的挑战,如扩大规模、多模态NTP的自发能力、模态特定偏差、模态间干扰,以及多模态NTP作为通用接口的问题,并讨论了缓解这些挑战的方法。表1概述了我们综述中的关键表格和图示。
![]()
1.2 相关工作最近,几篇工作回顾了多模态学习中的大型多模态模型(LMMs)。例如,Yin等人[448]深入探讨了早期视觉语言模型的理解能力。类似地,Awais等人[8]、Bordes等人[27]、Ghosh等人[130]、Caffagni等人[36] 和 Zhang等人[477]进一步探索了多模态学习的最新进展,重点讨论了模型架构、训练策略、数据集、评估指标等内容。此外,还有几篇综述回顾了视觉语言任务中的多模态学习,包括预训练[36]、迁移学习[479]、推理[402]和基于人类反馈的强化学习(RLHF)[479]。除了讨论大型多模态模型的整体变革外,一些专业的综述还调查了LMMs在多模态代理[224, 421]和自动驾驶[72]等领域的应用。近期的综述也讨论了多模态学习中的关键问题,如LMMs中的幻觉[256, 334]和LMMs的效率[185, 429]。与先前主要关注多模态LLMs理解能力的研究不同,我们的综述采用系统化的视角,通过下一个令牌预测范式将理解与生成统一起来,进行多模态学习的整合性评估。据我们所知,这是第一篇从下一个令牌预测角度回顾LMMs的综述,旨在帮助研究人员探索多模态智能。总之,本综述旨在全面回顾当前依赖下一个令牌预测的多模态模型。相关的GitHub链接收录了最新的论文,网址为:https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction。
![]()