大型语言模型(LLMs)由于依赖静态训练数据,常常面临幻觉和过时知识的问题。检索增强生成(RAG)通过整合外部动态信息来缓解这些问题,从而增强事实性和更新性基础。最近的多模态学习进展促成了多模态RAG的发展,结合了文本、图像、音频和视频等多种模态,以增强生成的输出。然而,跨模态对齐和推理为多模态RAG带来了独特的挑战,这使其与传统的单模态RAG有所不同。本综述提供了对多模态RAG系统的结构化和全面分析,涵盖了数据集、度量标准、基准测试、评估、方法论以及在检索、融合、增强和生成中的创新。我们精确回顾了训练策略、鲁棒性增强和损失函数,同时也探讨了多样化的多模态RAG场景。此外,我们讨论了支持该领域进展的开放挑战和未来研究方向。本综述为开发更强大、更可靠的AI系统奠定了基础,这些系统能够有效利用多模态动态外部知识库。资源可在 https://github.com/llm-lab-org/Multimodal-RAG-Survey 获取。 1 引言与背景
近年来,语言模型取得了显著的突破,主要得益于变换器(Vaswani et al., 2017)的出现、计算能力的增强以及大规模训练数据的可用性(Naveed et al., 2024)。基础性大型语言模型(LLMs)(Ouyang et al., 2022;Grattafiori et al., 2024;Touvron et al., 2023;Qwen et al., 2025;Anil et al., 2023)的出现彻底改变了自然语言处理(NLP),展现了在广泛任务中的前所未有的能力,包括指令跟随(Qin et al., 2024)、复杂推理(Wei et al., 2024)、上下文学习(Brown et al., 2020)以及多语言机器翻译(Zhu et al., 2024a)。这些进展提升了各种NLP任务的表现,开辟了新的研究和应用途径。尽管取得了显著成就,LLMs仍面临重大挑战,包括幻觉、过时的内部知识以及缺乏可验证的推理(Huang et al., 2024a;Xu et al., 2024b)。它们依赖于参数化内存,限制了访问最新知识的能力,使其在知识密集型任务中的表现不如任务特定架构。此外,提供其决策的来源并更新世界知识仍然是关键的开放问题(Lewis et al., 2020)。 检索增强生成(RAG)
检索增强生成(RAG)(Lewis et al., 2020)作为一种有前景的解决方案应运而生,通过使LLMs能够检索和整合外部知识,从而提高事实准确性并减少幻觉(Shuster et al., 2021;Ding et al., 2024a)。通过动态访问庞大的外部知识库,RAG系统在增强知识密集型任务的同时,确保响应保持在可验证的来源中(Gao et al., 2023)。在实践中,RAG系统通过检索器-生成器管道运作。检索器利用嵌入模型(Chen et al., 2024b;Rau et al., 2024)从外部知识库中识别相关段落,并可选地应用重新排序技术以提高检索精度(Dong et al., 2024a)。这些检索到的段落随后传递给生成器,生成器结合外部上下文生成知情响应。RAG框架的最新进展(Asai et al., 2023;An et al., 2024;Lee et al., 2024;Liu et al., 2024c)引入了迭代推理过程,通过优化检索和生成阶段,使回答更加准确和可靠。然而,传统的RAG架构主要设计用于文本信息,这限制了其处理多模态挑战的能力,而多模态挑战需要整合多种数据格式。 多模态学习
与这些发展并行,多模态学习的显著进展通过使系统能够整合和分析异构数据源,为信息的整体表示提供了新的视角,从而重塑了人工智能。CLIP(对比语言-图像预训练)(Radford et al., 2021)的引入标志着连接视觉和文本信息的关键时刻,通过对比学习促进了后续许多模型和应用的发展(Alayrac et al., 2024;Wang et al., 2023;Pramanick et al., 2023)。这些突破推动了各个领域的进展,包括情感分析(Das and Singh, 2023)和前沿的生物医学研究(Hemker et al., 2024),证明了多模态方法的价值。通过使系统能够处理和理解文本、图像、音频和视频等多种数据类型,多模态学习已成为推动人工通用智能(AGI)(Song et al., 2025)发展的关键。 多模态RAG
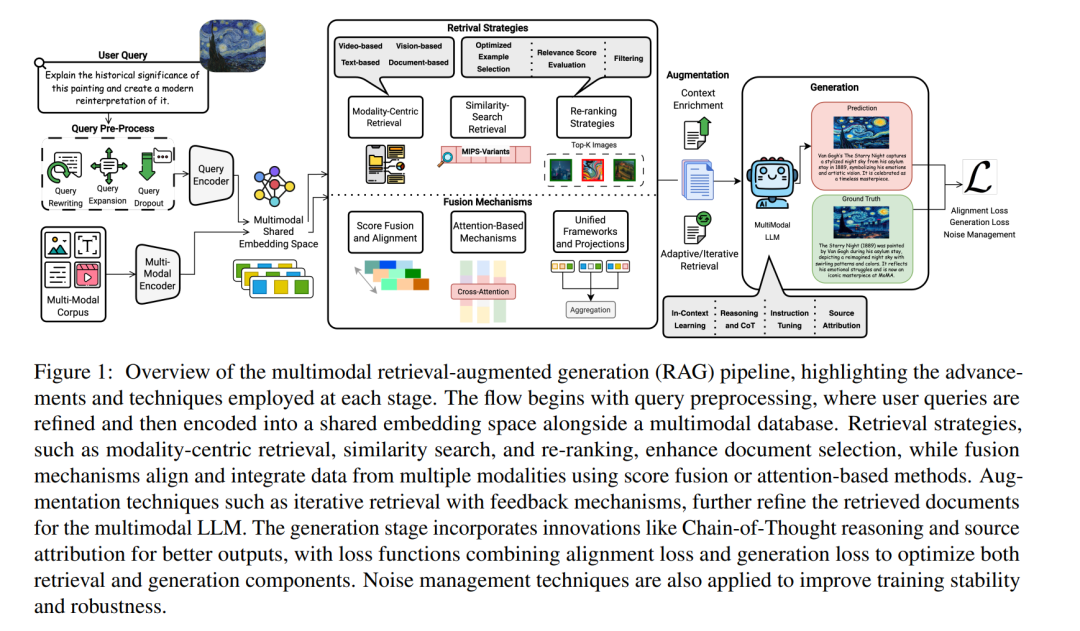
将LLMs扩展到多模态LLMs(MLLMs)进一步增强了其能力,使其能够跨多种模态进行处理、推理和生成输出(Liu et al., 2023a;Team et al., 2024;Li et al., 2023b)。例如,GPT-4(OpenAI et al., 2024)通过接受文本和图像两种输入,在多个基准测试中表现出人类级别的性能,标志着多模态感知和交互的一个重要里程碑。在此基础上,多模态RAG系统通过结合图像和音频等多模态知识源,扩展了传统RAG框架,为生成提供丰富的上下文(Hu et al., 2023;Chen et al., 2022a)。这种整合不仅增强了生成输出的精度,同时利用多模态线索提高了MLLMs的推理能力。多模态RAG管道的基本流程如图1所示。然而,这些多模态系统也带来了独特的挑战,包括确定检索哪些模态、有效融合多种数据类型以及处理跨模态相关性的复杂性(Zhao et al., 2023)。 任务公式化
我们给出了多模态RAG系统的通用任务数学公式。这些系统针对一个查询q(通常是文本格式)生成一个多模态响应r。 设D = {d1, d2, ..., dn}为一个由n个多模态文档组成的语料库。每个文档di ∈ D与一个模态Mdi关联,并通过模态特定的编码器EncMdi处理:

相关工作
由于多模态RAG领域是新兴且迅速发展的,特别是在近年来,对于探索这些系统的当前创新和前沿的综述需求迫切。尽管已有超过十篇关于RAG相关主题的综述文章(如代理RAG(Singh et al., 2025)),但没有一篇详细全面地概述多模态RAG的进展。迄今为止唯一的相关综述(Zhao et al., 2023)通过根据应用和模态对相关文献进行分类。然而,我们的综述提供了一个更详细且创新驱动的视角,提供了详细的分类法,并深入探讨了新兴趋势和挑战。此外,自该综述发布以来,领域内已经取得了显著进展,对该主题的研究兴趣也显著增长。在本综述中,我们回顾了近年来发表的100多篇关于多模态RAG的论文,主要来自ACL文集和其他如ACM数字图书馆等资源库。 贡献
在本研究中,(i)我们提供了对多模态RAG领域的全面回顾,涵盖了任务公式化、数据集、基准、任务和领域特定应用、评估以及检索、融合、增强、生成、训练策略和损失函数的关键创新。(ii)我们引入了一个精确的结构化分类法(图2),根据其主要贡献对最先进的模型进行了分类,突出方法学进展和新兴前沿。(iii)为了支持进一步的研究,我们公开了包括数据集、基准和关键创新在内的资源。(iv)我们识别了当前的研究趋势和知识空白,提供了见解和建议,以指导该不断发展的领域的未来进展。