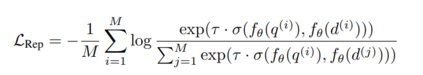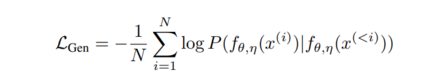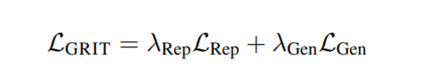https://www.zhuanzhi.ai/paper/7bd3e811fb05397ac95b4053d94f04cd
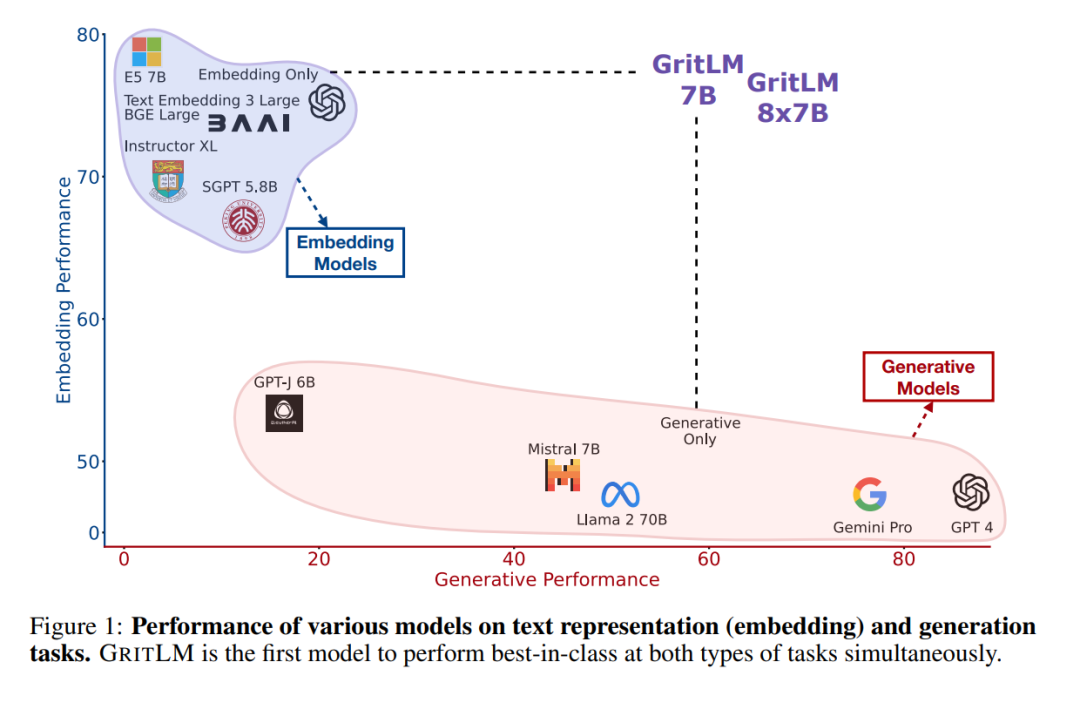
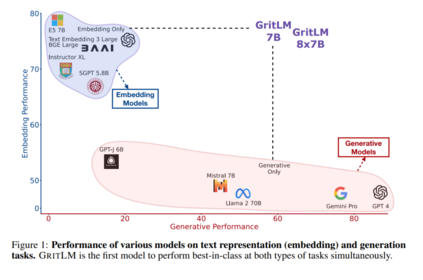
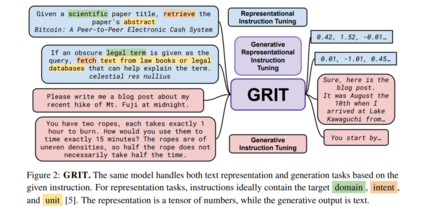
创建一个在广泛任务范围内表现良好的单一通用模型,一直是人工智能领域的长期目标[73, 67, 21, 130, 139]。最近,大型语言模型(Large Language Models, LLMs)已成为单一多任务模型的有希望方向[125, 13]。先前的工作认为,所有基于文本的语言问题都可以简化为生成问题,因此可以通过单一LLM处理[128, 38]。然而,使用嵌入的任务,如聚类或检索[107],从这一视角大多被忽视。如今,文本嵌入支持许多关键的现实世界应用,从搜索引擎到面向用户的聊天机器人[63, 144]。虽然将文本嵌入整合到生成范式中是可能的,通过生成一系列数字来形成嵌入张量,但由于嵌入的高维度和精度要求,这变得不切实际。因此,更常见且更容易的做法是使用模型的隐藏状态作为嵌入表示,这已经是一个数值张量[104, 158, 102]。然而,对当前生成模型这样做会导致性能不佳。例如,虽然T5模型[128, 134]可以以序列到序列的方式处理任何生成任务,但它需要微调才能使其隐藏状态对文本嵌入有用[111, 112],在此过程中它失去了生成能力。我们引入GRIT(生成性表征指令调整),将嵌入和生成任务统一起来,导致一个在两个任务上都表现出色的模型,如图1所示。图2展示了GRIT如何结合两个之前分离的训练范式:(1)生成性指令调整,模型通过生成一个答案来响应指令进行训练[164, 134];和(2)表征性指令调整,模型根据指令代表提供的输入进行训练[143, 5]。通过指令和分离的损失函数,模型学会区分这两种流。我们在高达47B参数的模型上测试我们的方法,并且由于其简单性,我们期望该方法能泛化到任何LLM,甚至非变换器模型。通过GRIT的统一带来了三个优点:a)** 性能**:我们的统一模型匹配了仅嵌入和仅生成变体的性能,甚至在某些任务上超越它们。在7B参数下,GRITLM在开放模型中在Massive Text Embedding Benchmark[107]上设定了新的艺术状态,并同时在生成任务上超越了更大的模型,如Llama 2 70B。通过进一步扩展,GRITLM 8X7B是我们任务平均上最好的开放生成语言模型,同时仅在推理时使用13B参数。此外,由于我们的模型使用滑动窗口注意力[20, 9],它们可以处理任意长度的生成和嵌入输入。b)** 效率**:通常一起使用生成和嵌入模型来弥补彼此的不足[56, 84]。一个这样的场景是检索增强生成(RAG)[84],其中使用嵌入模型检索提供给生成模型以回答用户查询的上下文。这需要将用户查询和上下文传递给生成模型和嵌入模型,共计四次前向传递。有了GRITLM,嵌入和生成模型是等价的,允许我们缓存计算并将所需的前向传递次数减半。我们发现这可以使长文档推理时的RAG速度提高60%以上。c) 简单性:目前,如OpenAI这样的API提供商提供单独的生成和嵌入端点。这需要单独的负载平衡、额外的存储和更复杂的服务软件。一个同时处理两种用例的单一模型显著简化了基础设施需求。GRIT的主要缺点是由于使用两个目标函数进行训练,它需要更多的计算。然而,由于微调与预训练相比成本较低,我们认为好处远远超过这个问题,因此建议构建遵循指令的语言模型的实践者在微调期间采用GRIT。
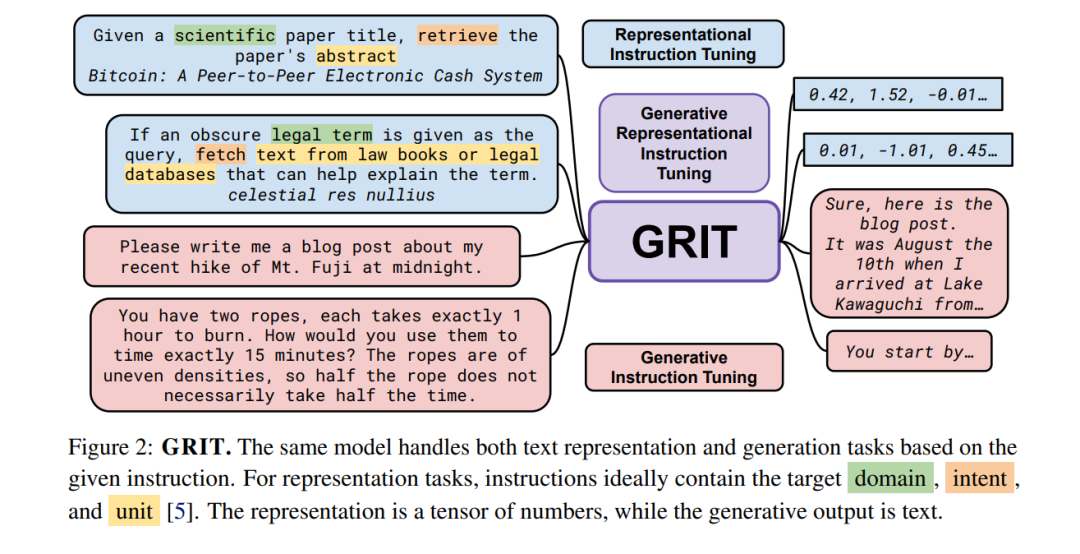
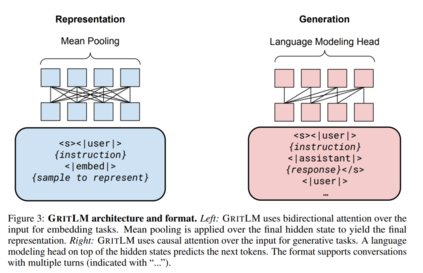
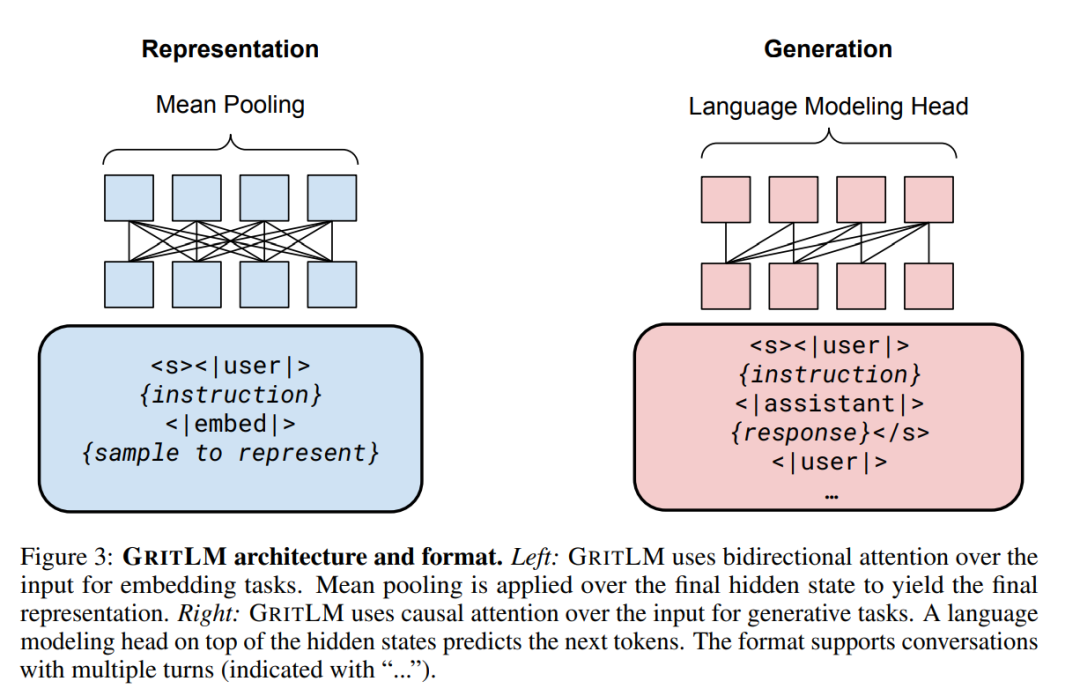
GRITGRIT将表征性指令调整[143, 5, 160]和生成性指令调整[164, 134, 108]统一到一个单一模型中。我们使用嵌入和生成指令数据以一致的格式对预训练的大型语言模型[13]进行微调,如图3所示。对于嵌入数据,我们遵循先前的工作,使用批内负例[18, 51]通过对比目标计算损失:
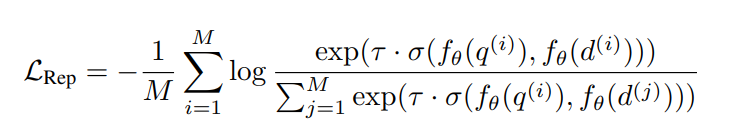
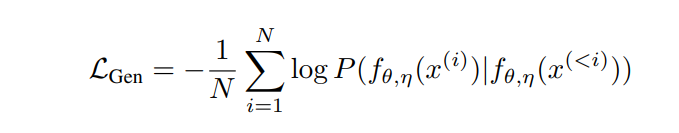
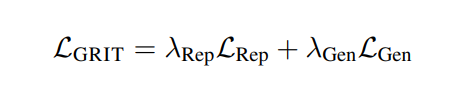
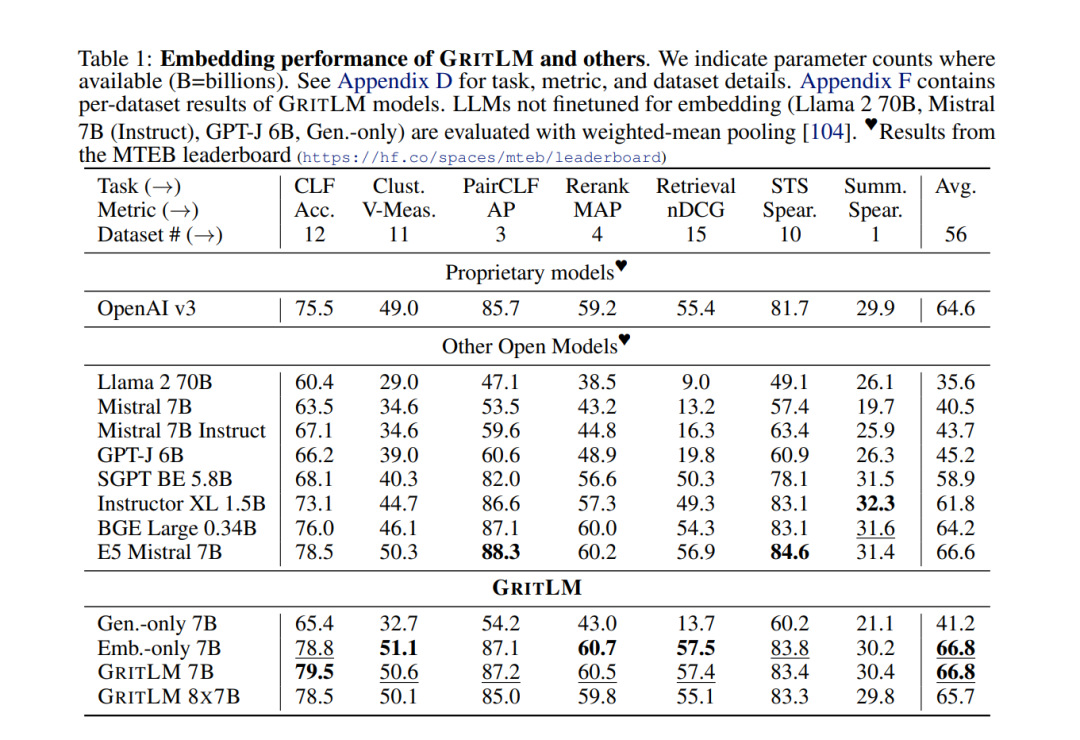
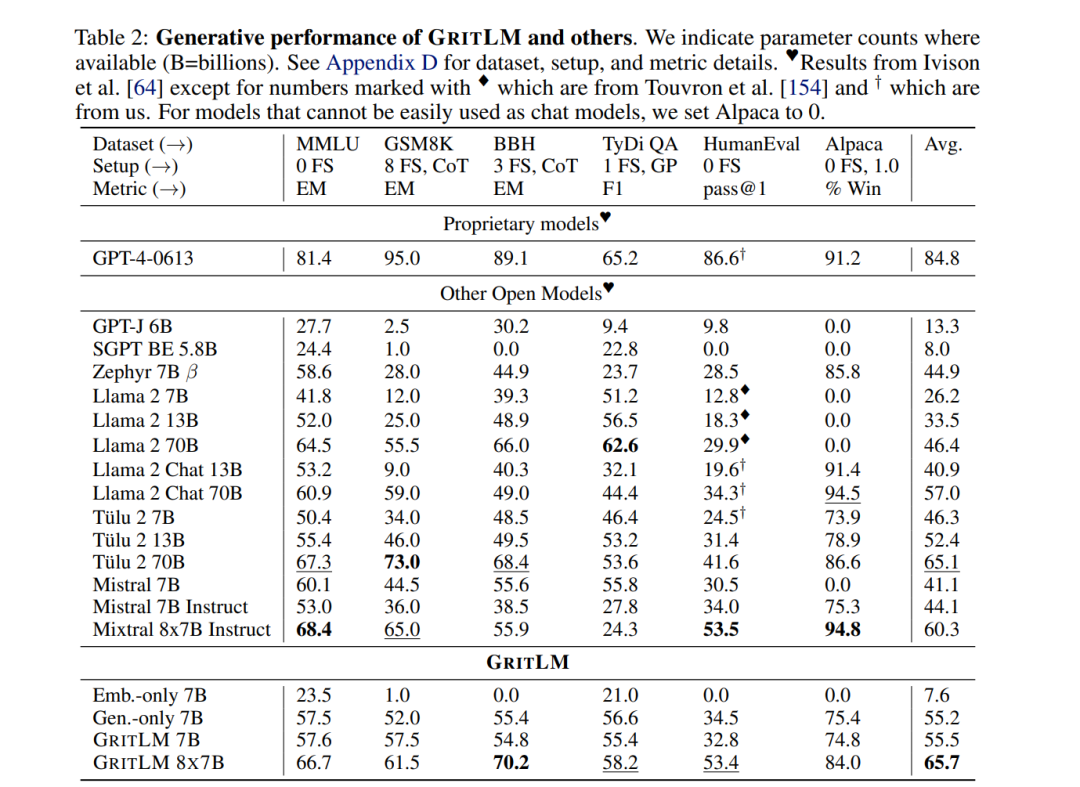
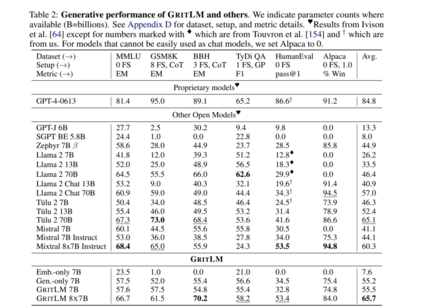
值得注意的是,我们的公式支持不同数量的嵌入样本(M)和生成样本/令牌(N)。这允许显著增加嵌入批量大小,同时保持生成批量大小固定。大的嵌入批量大小通常是文本嵌入模型表现良好的关键[169]。然而,这需要在每一步都增加更多的计算成本。实验GRIT带来了最先进的嵌入和生成模型。我们在表1和表2中对GRITLM 7B、GRITLM 8X7B以及仅生成和仅嵌入的变体与其他模型进行了基准测试。我们发现GRITLM 7B在Massive Text Embedding Benchmark[107]上超过了所有先前的开放模型,同时在其大小为70亿参数的所有生成模型中仍然表现优异。GRIT模型是唯一能够在嵌入和生成上都实现最佳性能的模型(图1)。例如,使用Llama 70B[154]进行嵌入在MTEB上仅得到35.6的分数,如表1所示。GRITLM几乎将MTEB上的性能翻倍,达到最先进的性能,同时在生成任务上的表现也超过Llama 70B 20%以上(表2)。进一步扩大规模,GRITLM 8X7B在我们的生成平均上超过了所有公开可用的模型。我们还训练了仅使用表征或生成指令调整的GRITLM的嵌入仅和生成仅变体,但在其他方面相同。在表2中,仅通过重新添加在嵌入微调期间去除的语言建模头,将嵌入仅变体或SGPT BE 5.8B[104]在生成任务上进行基准测试,导致性能几乎是随机的(MMLU上的随机基线为25.0)。同样,基准测试仅生成模型的嵌入性能仅在表1中得到41.2的分数。因此,通过GRIT方法的联合优化对于同时实现嵌入和生成的强大性能至关重要。然而,我们注意到,拥有70亿参数的GRITLM 7B运行成本显著高于表1中的许多其他嵌入模型,例如仅有3.35亿参数的BGE Large[169]。此外,GRITLM 7B产生的表示为4096维,需要比BGE Large的1024维嵌入多4倍的存储空间。