

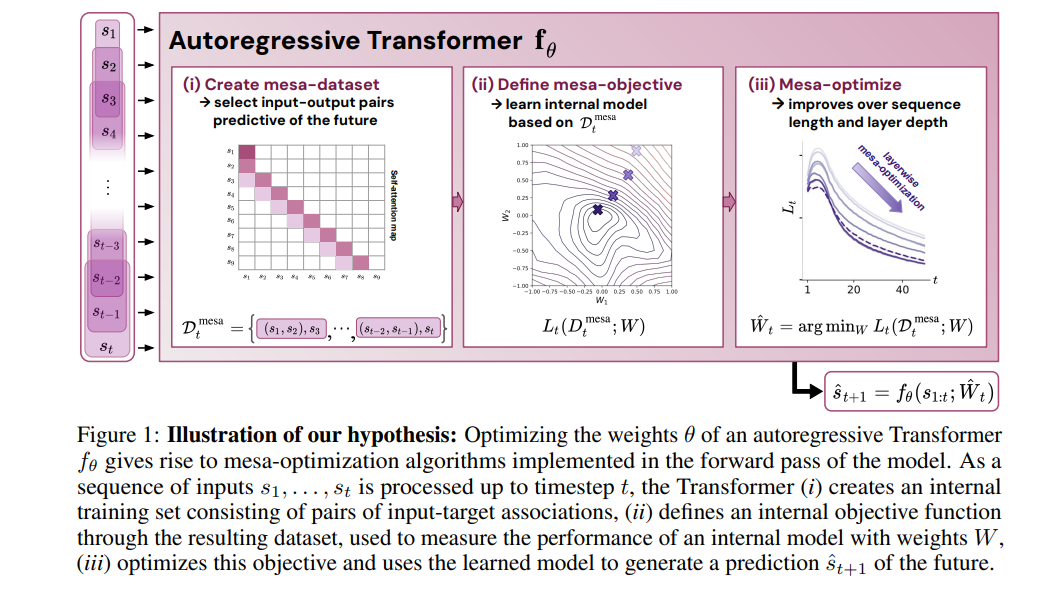
变换器(Transformers)已经成为深度学习中的主导模型,但其优越性能背后的原因尚不清楚。在这里,我们假设变换器的强劲性能源于其对台阶优化(mesa-optimization)的结构偏好,这是一个在模型前向传播过程中运行的学习过程,包括以下两个步骤:(i)构建一个内部学习目标,以及(ii)通过优化找到其相应的解决方案。为了测试这一假设,我们对一系列在简单序列建模任务上训练的自回归变换器进行了逆向工程,揭示了驱动预测生成的基础梯度台阶优化算法。此外,我们展示了学习到的前向传播优化算法可以立即用于解决监督下的少样本任务,这表明台阶优化可能是大型语言模型的上下文学习能力的基础。最后,我们提出了一种新颖的自注意力层,即台阶层(mesa-layer),该层明确且高效地解决在上下文中指定的优化问题。我们发现这一层可以在合成和初步的语言建模实验中提高性能,进一步支持我们的假设,即台阶优化是隐藏在训练有素的变换器权重中的重要操作。
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
Arxiv
0+阅读 · 2023年10月25日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年10月25日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日