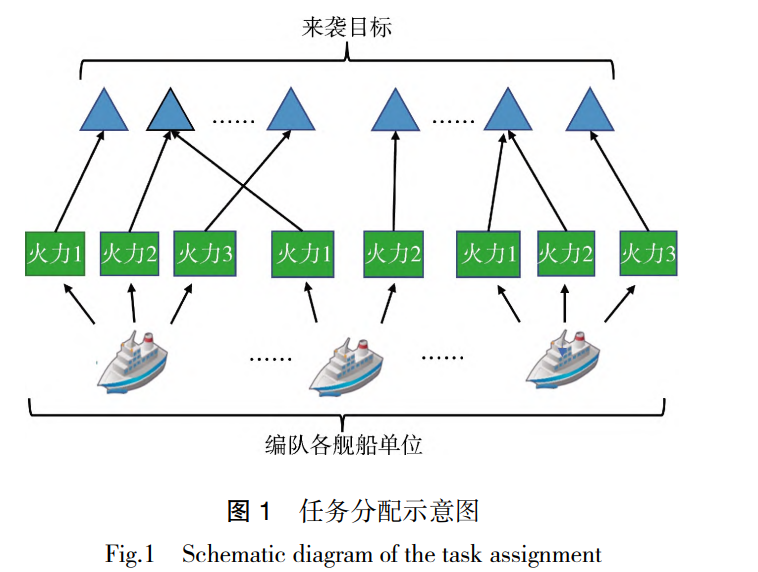
针对目前海上编队防空任务分配综合效益低,实时性较差等问题,提出了一种基于深度强化学习的海上编队防空任务分配方法。考虑来袭目标威胁度和武器数量等因素,从毁伤效能出发,构建任务分配问题优化模型。在此基础上,将问题转换成马尔可夫决策过程,定义深度强化学习求解所需的状态空间,动作空间与奖励函数。使用了两种结构简单的深度强化学习算法DQNReg和DQNClipped对模型进行优化求解,实现较优的任务分配。仿真结果表明,相比于传统的智能优化算法,基于深度强化学习的海上编队防空任务分配方法能够实现综合效益值更高的任务分配,且求解时间更短,证实了所提方法的有效性。
现代空袭目标技战术性能的快速提高给海上 编队协同反导带来了巨大挑战,防空作战形势日趋 严峻。编队间协同目标分配的快速确定和优化,是 提高对空作战能力,保护编队生命力的关键。程明提出一种目标分配方法,基于受限时段资源对舰艇 防空武器进行了合理的调度,得到多目标拦截武器 分配方案[1]。周菁提出的目标分配算法为每个个 体安排最佳的攻击目标,使集群的协同攻击效能最 大[2]。白建保等提出了一种基于命中概率模型的反 舰导弹目标分配方法,完善了相关数学模型[3]。曹 璐提出了基于决策图贝叶斯优化算法的多无人艇 协同目标分配方法,结合约束条件构建了多无人艇 协同目标分配数学模型[4]。孙鹏等研究了基于突发 事件的任务分配,将目标函数设为最小完成时间, 通过贪婪算法进行可执行任务的动态分配,但此研 究忽略了任务截止时间的约束[5]。
上述传统方法虽然快速有效但是理论性不强, 且需要大量的专业知识和试错,无法被广泛使用, 并且这些启发式算法只是针对某一特定环境求取 最优解,面对环境变化时,往往需要重新求解,实时 性差。 而强化学习算法拥有自决策的特点,可以 根据战场状态进行快速响应和调整,但其在解决大 规模问题和维度较高时性能较差,深度强化学习的 出现可以有效解决此难题。MNIH 等提出了 DQN 网络[6],其同时具有强化学习和深度学习的特点, 其有效性在多个领域得到了证实,并不断被更新优 化。朱建文等使用 Q-Learning 算法对导弹的选取和 分配方式进行智能决策[7]。代琪等提出了一种基于 强化学习与深度神经网络的算法,在动态多无人机 任务分配问题的求解中具有良好的性能[8]。黄亭飞 等采用一种基于深度 Q 网络(DQN)的模型对无人 机动态任务分配问题进行了求解[9]。丁振林等提出 一种基于强化学习与深度神经网络的动态目标分 配算法,火力拦截成功率得到明显的提升[10]。龙腾 等提出了一种基于神经网络的防空武器目标智能 分配方法,能得到相对最优的分配方案[11]。相关研 究虽然在一定程度上弥补了传统算法的不足,但缺 乏对实际战场环境下的编队协同防空任务分配数 学模型的适应性改进,综合效益值仍有上升空间。 本文在现有研究的基础上,建立和完善相关数 学优化模型,提出了一种基于深度强化学习的海上 编队协同防空任务分配方法,利用两种结构简单的 深度强化学习算法对模型求解,进行任务分配的决 策,可在时间成本较低的情况下实现较高的任务分 配综合效益值。