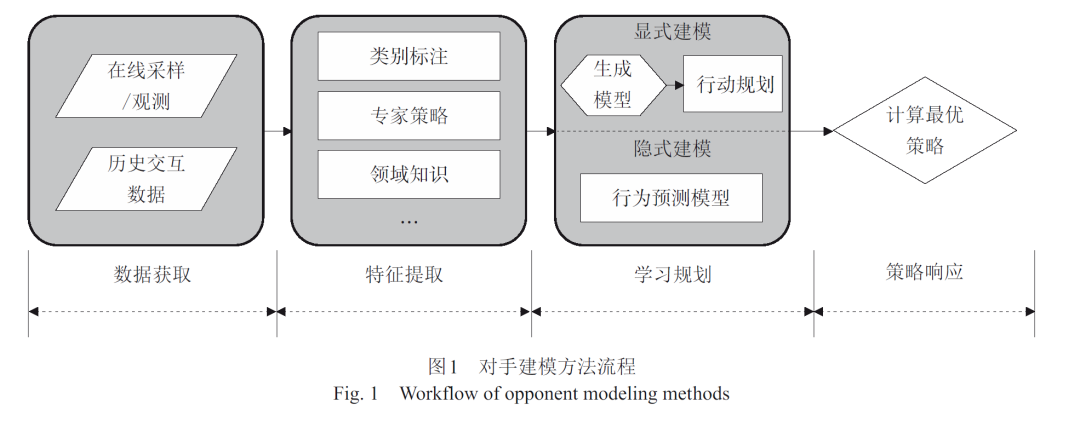
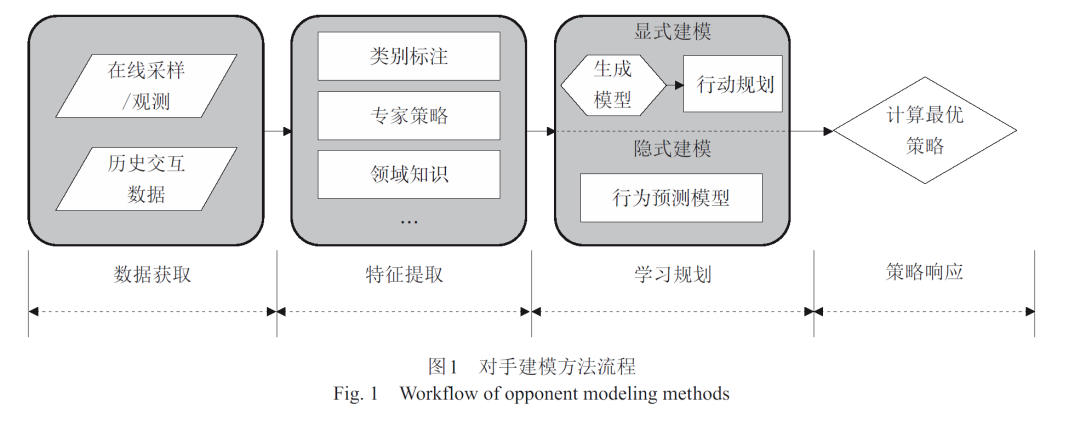
深度强化学习是一种兼具深度学习特征提取能力和强化学习序列决策能力的智能体建模方法,能够弥补传统对手建模方法存在的非平稳性适应差、特征选取复杂、状态空间表示能力不足等问题。将基于深度强化学习的对手建模方法分为显式建模和隐式建模两类,按照类别梳理相应的理论、模型、算法,以及适用场景;介绍基于深度强化学习的对手建模技术在不同领域的应用情况;总结亟需解决的关键问题以及发展方向,为基于深度强化学习的对手建模方法提供较全面的研究综述。
如何在合作、竞争的复杂任务场景中自主决策是当前人工智能领域所要解决的关键问题。在游戏人工智能、军事仿真、自动驾驶、机器人集群控制等应用场景的多智能体系统中,智能体具有感知、记忆、规划、决策、交流、行动等许多能力,其中对其他智能体行为、意图、信念等的推理十分重要。在此过程中,智能体往往需要通过观察其他智能体,建立除自身以外的其他智能体抽象模型,推理其行为、意图、信念等要素,并用于辅助自身决策,此过程涉及到的方法被称为对手建模(opponent modeling, OM)。对手建模不仅关注竞争场景下的敌方智能体建模,而且还考虑合作场景下的友方建模,因此,有些文献又称其为建模其他智能体。从理论上讲,完全理性的智能体能够做出当前条件下的最优策略,实现收益的最大化。然而,现实情况下的智能体通常只具有有限程度理性[1],决策受到情绪、偏好等影响,往往以“满意”作为收益标准。此外,基于规则的智能体,如产生式规则、启发式算法等[2-4],遵循预置规则机制,行为模式僵硬、易于预测、理性程度不足,对手建模技术使智能体能够快速适应对手的行为方式并且在对抗中利用其弱点获取更高收益,或在合作中使团队获得更大回报。现有的对手建模方法如策略重构、类型推理、意图识别、递归推理等方法[5],具有模型可解释、认知推理层次深的特性。然而,要进一步应用于贴近现实的问题场景仍然存在动态环境适应性弱、特征选取复杂、状态空间表示能力不足、方法在规模上的可扩展性不强等诸多缺陷。针对以上不足,研究者们将以深度Q网络(deep Q network, DQN)[6]为代表的深度强化学习算法(deep reinforcement learning, DRL)引入到对手建模领域。其中,强化学习是智能体学习如何与环境交互,达到最大化价值和最优策略的自主决策算法。深度学习则能够从高维感知数据中提取抽象特征,对复杂的价值函数和策略函数具有很强的拟合能力。DRL有机地结合了深度学习与强化学习,前者能够增强感知与表达能力,后者提供最优决策能力,使基于DRL的对手建模(DRL-OM)技术对复杂环境中其他智能体具有更好的认知能力,目前已在德州扑克[7-8]、星际争霸II[9]等多智能体问题场景取得优异的表现。DRL-OM是DRL方法在对手建模应用中的研究分支,涉及人工智能、神经科学、认知心理学、博弈论等众多领域。有别于以往的对手建模方法[10],DRL-OM研究涉及更复杂的应用场景、更多元的领域交叉,在问题特性、建模方式、应用场景上和传统方法具有较大差异。虽然许多现有文献[11-12]将对手建模领域的已有研究进行了汇总分类,但目前尚没有将基于DRL方法的对手建模进行系统研究的综述文章。此外,有关多智能体强化学习的综述研究[13-14]也阐述了对手建模的应用,然而它们的内容普遍较少涉及对手建模原理,也没有系统地分类和总结对手建模方法。随着DRL越来越广泛地应用在对手建模中,领域内涌现出许多崭新的理论和方法,远超现有文献总结的涵盖范围。因此,本文将DRL算法作为研究出发点,基于对手的理性程度和建模机理提出不同于现有文献[11-12]的对手建模分类标准。此外,对手建模技术的更新迭代为现实应用提供了机遇和挑战,为此,本文汇总归纳了DRL-OM方法在应用领域的相关研究工作。