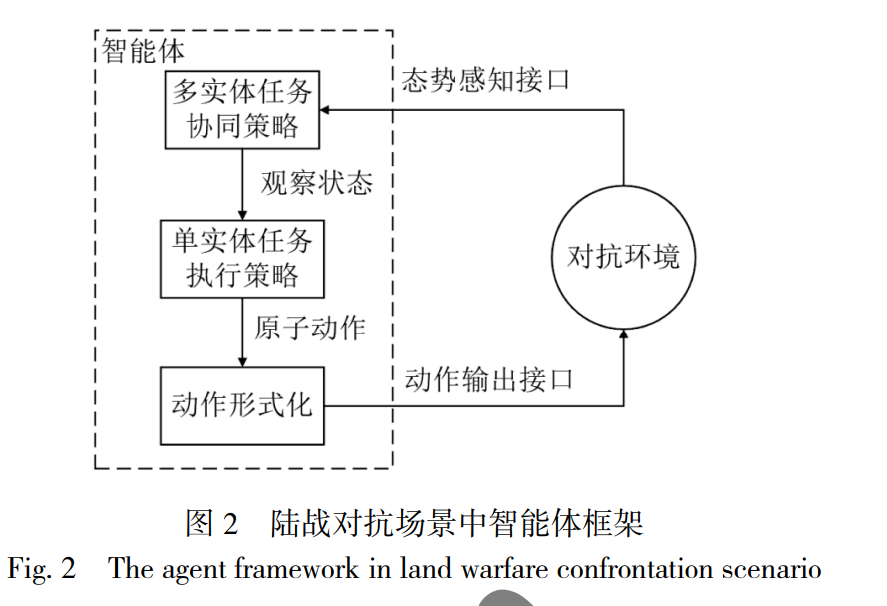
针对陆战对抗中智能体状态动作空间复杂和行为模式固定的问题, 提出任务分层架构下的博弈策略生成方法. 使用策略 式博弈模型对陆战对抗问题进行分析建模, 给出智能体任务执行中的收益矩阵构建方法, 并通过求解混合策略, 使智能体行为同 时具有合理性和多样性. 以陆军战术对抗兵棋推演为平台进行测试, 实验证明智能体策略可解释性强, 行为模式多样, 在与 AI 和 人类选手对抗时都具有较高的胜率. 智能体是人工智能的一个基本术语, 广义的智 能体包括人类、机器人、软件程序等[1] . 狭义的智能 体是能感知环境, 根据环境变化作出合理判断和行 动, 从而实现某些目标的计算机程序. 从感知序列集 合到执行动作集合的映射也称为智能体的策略[2] . 智 能体策略的研究对实现无人系统自主能力[3]和人机混 合智能[4]具有重要意义. 决策指根据一定目标选择备选方案或动作的过 程. 传统使用脚本规则[5]、有限状态机[6]、行为树[7]等 方法进行智能体决策行为建模, 决策模型对应了智 能体的策略. 这类智能体的策略具有较强的可解释 性, 但是其需要大量的领域专家知识. 另一方面上述 智能体通常使用基于专家知识的纯策略, 其行为模 式是固定的, 在复杂对抗场景中存在适应性不强和 灵活度不够的问题. 近年, 深度强化学习成为智能体 策略生成的重要方法, 在 Atari 游戏[8]、围棋[9-11]、德 州扑克[12]、无人驾驶[13]等领域取得了突破进展, 部分 场景中已经达到或超越了人类专家水平. 然而基于 强化学习的智能体在更为复杂的场景中面临着感知 状态空间巨大、奖励稀疏、长程决策动作组合空间 爆炸等难题[14] . 战争对抗作为一种复杂对抗场景, 一直是智能 体策略生成研究的重点, 并越来越受到关注[15-17] , 但 当前研究还缺少实质性的进展, 特别是在人机对抗 中[18] , 人类对手策略变化造成的环境非静态性会使智 能体显得呆板、缺少应变能力. 针对陆军战术级对抗场景中智能体状态动作空 间复杂和行为模式固定的问题, 以中科院“庙算·智胜 即时策略人机对抗平台”陆军战术对抗兵棋(以下简 称“庙算”陆战对抗兵棋)为实验平台, 提出了基于博 弈混合策略的智能体对抗策略生成方法. 本文工作 主要有 3 个方面: 1)对陆战对抗中实体动作进行抽象、分层, 建 立智能体任务分层框架, 降低问题求解的复杂度. 2)对陆战对抗实体任务中关键要素进行分析, 构建对抗问题博弈模型, 并给出收益矩阵的计算 方法. 3)给出陆战对抗兵棋推演场景中智能体混合策略均衡的求解方法, 对本文所提方法的可行性进行 了验证.