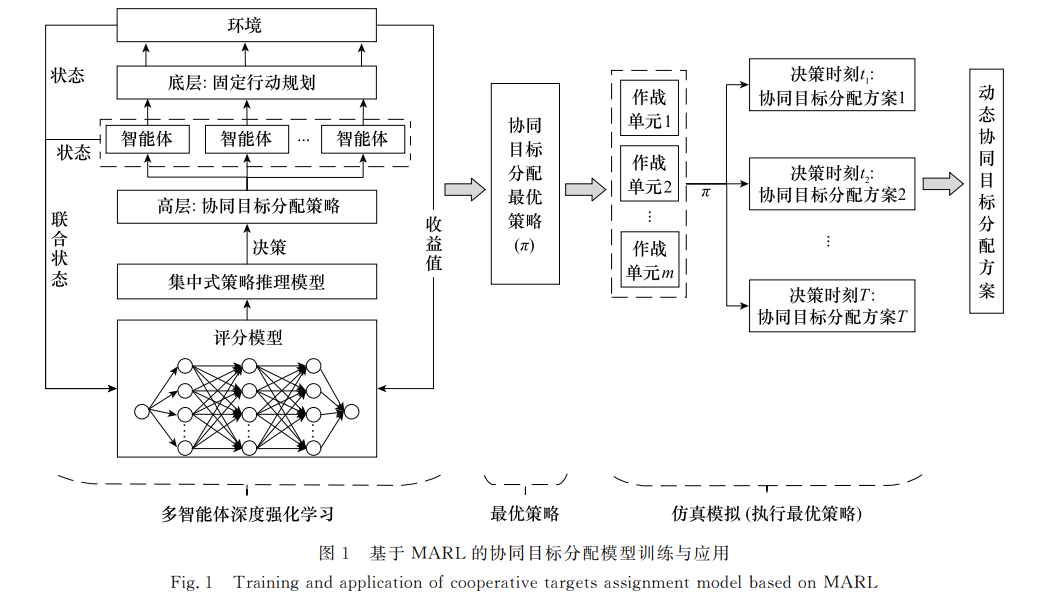
针对传统方法难以适用于动态不确定环境下的大规模协同目标分配问题, 提出一种基于多智能体强化学习的协同目标分配模型及训练方法。通过对相关概念和数学模型的描述, 将协同目标分配转化为多智能体协作问题。聚焦于顶层分配策略的学习, 构建了策略评分模型和策略推理模型, 采用Advantage Actor-Critic算法进行策略优化。仿真实验结果表明, 所提方法能够准确刻画作战单元之间的协同演化内因, 有效地实现了大规模协同目标分配方案的动态生成。
协同目标分配, 决定了兵力运用的科学性和合理性, 是将作战意图落地为作战行动的关键环节[1]。在同一时间或空间范围内, 多个作战单元为完成同一项作战任务或相互之间存在逻辑关系的多个作战任务时, 需从时间、空间和效果等角度考虑, 进行目标或火力的合理分配, 以最大作战效费比和最小作战风险获得最优打击效果。
协同目标分配是一种典型的非线性多项式完全问题, 决策空间随问题规模(即作战单元数目和作战目标数目)增大呈指数级增长, 求解结果的的实时性、准确性和有效性将直接影响军事对抗中能否取得最佳作战效果。在军事运筹领域, 协同目标分配通常被规约为兵力分配、火力分配或武器目标分配(weapon target assignment, WTA)等问题[2-3], 常用求解方法可分为传统规划方法[4]、模拟退火(simulated annealing, SA)算法[5-6]、蚁群优化(ant colony optimization, ACO)算法[7]、粒子群优化(partical swarm optimization, PSO)算法[8-11]、进化算法(evolutionary algorithm, EA)[12-15]和合同网协议(contract net protocol, CNP)[16]。现有研究虽从不同角度对各种算法进行了改进, 并成功应用于不同场景, 但关于动态不确定环境下的协同目标分配研究较少, 且难以保证大规模目标分配问题的求解效率。
在分布式作战自同步理论中[17], 协同关系体现为作战单元“自底向上组织复杂战争的行为”。将作战单元构建为智能体, 协同目标分配问题便转化为多智能体协作(multi-agent cooperation, MAC)问题, 多智能体强化学习(multi-agent reinforcement learning, MARL)[18]在解决类似协作问题上有着广泛应用[19-23]。据此, 通过分析协同目标分配的军事内涵, 构建了基于MARL的协同目标分配模型, 采用局部策略评分和集中式策略推理, 利用Advantage Actor-Critic算法进行策略学习, 以期能够实现简单场景中训练好的模型直接泛化应用到复杂场景, 从而有效实现大规模目标分配。