
文/李文斌
摘 要:
当前机器学习方法往往依赖大规模标注数据,无法像人类那样从少量样本和标记中进行高效的学习和泛化。本文针对开放场景下存在的样本稀缺、标记稀缺和计算资源稀缺等挑战,提出局部表征与度量的小样本学习方法体系、基于亲和矩阵的自监督对比学习框架和基于类中心化约束的数据集蒸馏技术,增强了开放场景下机器学习技术应用能力。此外,简要介绍以上研究所取得的代表性成果。 关键词:
新型机器学习;小样本学习;对比学习;数据集蒸馏
近年来,随着计算设备计算能力的增强,大型标注数据的出现,以及深度学习的迅猛发展,机器学习特别是深度学习,在计算机视觉和自然语言处理等领域取得了显著的进步和成功。机器学习算法已经在不少领域远远超越了人类,例如,残差网络ResNet 在 ImageNet 数据集上的分类准确率已经远超过人类,AlphaGo 在围棋游戏上也远胜于人类围棋冠军。然而,现有机器学习方法往往是在数据充足、标记完备,以及计算资源充裕的闭式场景下进行研究和验证的,忽略了真实开放场景下数据可能是稀缺的、标记是不完备的,甚至计算资源是有限的。在真实开放应用场景下,一方面数据常常呈现不规则及长尾分布的情况,对于某些特定的类别,数据往往是稀少的,即小样本问题;另一方面,在某些场景中尽管能够获得大量数据,但是标注的代价却是昂贵的,即无标记问题。此外,在很多资源受限的应用场景中,硬件的计算资源也是有限的,无法针对大量训练数据进行学习。在这些开放场景问题中,现有机器学习的能力远远达不到人类的智能。相反,人类能够在开放环境中与周围的环境进行交互,然后不断学习和进化。特别地,人类能够从很少的实例中学习新的概念,甚至从幼儿发育开始就能进行无监督学习,并拥有很强的泛化能力。因此,如何利用有限少量的标注数据和大量无标注数据,在有限的计算资源下进行学习,并使模型具有较高的泛化能力就成为一个很重要的研究问题。
1 样本稀缺场景下的小样本学习
针对开放场景中新类样本稀缺的问题,即小样本问题,现有研究主要构建小样本学习理论与方法进行解决,其核心是如何从一个额外的辅助数据集中学习和迁移有用的表征和知识来帮助解决目标新类的学习和识别。其中主要存在四个难点:① 知识迁移,如何从辅助数据集上学习和迁移知识或者特征表示?② 概念表征,如何精确且有效地表征一个类别?③ 图像表征,如何精确且有效地表征一张图像?④ 关系度量,如何有效地度量一个查询图像与一个类别之间的关系?
针对上述问题和难点,我们针对性地提出一套以局部表征学习为基底、新型度量函数设计为核心、元学习为驱动力的小样本学习方法体系,相对于全局表征技术,局部表征能够天然扩充百倍样本空间,有效缓解开放场景下机器学习算法对数据依赖过强的问题。小样本学习问题中由于标记数据匮乏,采用传统全局特征学习的方式,难以缓解由数据不足带来的过拟合问题,我们创新地在小样本学习中引入局部表征与局部度量学习,并产生了下述一系列创新成果。
(1)针对小样本学习方法通常采用一阶均值信息对类别进行表征的问题,我们提出一种基于丰富局部描述子特征的二阶协方差类别表征方法CovaMNet;此外定义了一个新的深度协方差度量函数 (covariance metric function),可以有效计算查询样本的局部描述子特征与类别概念之间的分布一致性。具体地,CovaMNet 通过引入情景训练来学习可迁移的知识,设计了一个局部协方差表示,并将其嵌入到深度神经网络中来学习表达每个类别。因为协方差表示提取的是二阶统计信息,所以能够天然地捕获每个概念潜在的分布信息,故能够成为一种很好的概念表征方法。
(2)为了更好利用和学习深度局部描述子特征,我们提出使用非量化的深度局部描述子对图像和类别进行表征,以及一种图像到类别的度量方法;专门设计了一个新颖的深度最近邻神经网络(deepnearest neighbor neural network,DN4)模型。DN4遵循情景训练机制,并且是完全端到端训练的。它和现有相关的小样本学习方法最核心的不同之处在于,深度网络中最后分类层中,基于图像级别特征的度量方式被替换成基于局部描述子的图像到类别的度量方式。这种度量方式是通过在局部描述子池中进行 k-NN 搜索实现的,然而在大量的局部描述子的集合中进行最近邻搜索非常耗费时间。幸运的是,小样本学习下每个类别样本不足的缺点反而变成了优点,既能获得较好的性能,又能保证高效的运行效率。
(3)我们发现以往的小样本学习工作主要集中在图像级的特征表示上,由于样本的稀缺性,这种方法理论上无法有效地估计类的分布。因此,在局部表征的基础上,提出非对称分布测量(asymmetricdistribution measure,ADM)方法,采用由均值向量和协方差矩阵构成局部特征分布对图像样本和图像类别进行表征。此外,现有基于度量的小样本学习方法均采用对称假设来度量查询图像与支撑类别之间的关系,并不符合实际理论假设。针对该问题,提出一种非对称度量假设,进而提出一种基于局部特征分布的非对称度量小样本学习方法,证明了这种有偏的非对称度量能取得更好的度量性能。
(4)我们还提出了一个新的防御型小样本学习问题,考虑在小样本场景下如何增强机器学习模型的安全性和鲁棒性。然而,将现有样本充裕场景下的对抗性防御方法直接应用于小样本场景中,并不能有效地解决这一问题。这是因为通常训练集和测试集之间的样本分布一致性的假设,在小样本设置中不再满足。为此研究如何学习鲁棒的小样本学习模型来防御对抗性攻击,并验证了基于情景的对抗训练机制可以迁移对抗防御性知识,通过假设任务级分布一致性来解决跨类别对抗防御问题;另外,验证了基于局部特征的对抗训练技术相对于全局特征更能有效地提高模型的对抗防御能力。
最后,我们发现不同的小样本学习工作可能会使用不同的软件平台、不同的训练技巧、不同的骨干网络,甚至不同的输入图像大小,这给可复现性带来困难,并使得公平比较变得困难。为了解决这些问题,构建并开源了一个统一的小样本学习框架 LibFewshot。如图 1 所示,该框架包含了 25 个2017—2022 年具有代表性的小样本学习算法,为小样本学习领域中算法对比采用统一框架、统一设置、实现公平对比等提供便利。该框架在开源社区受到广泛的关注和讨论,其 GitHub Star 数量 798、Fork数量 157。
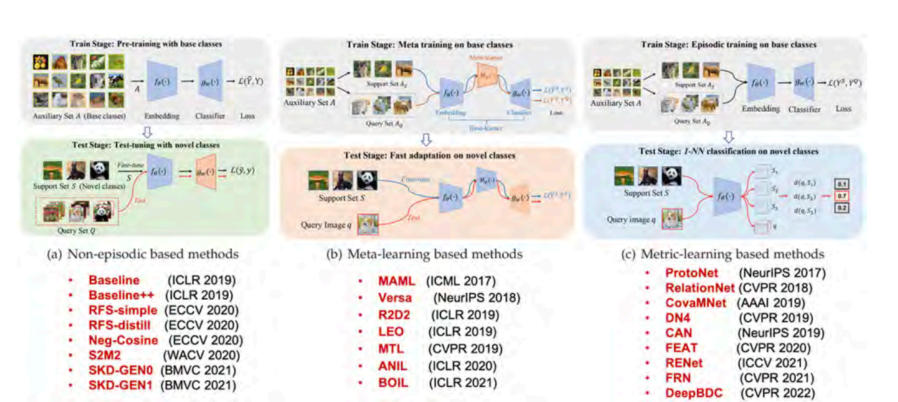
图 1 LibFewshot 框架
**2 **标记稀缺场景下的自监督对比学习
通过在大规模数据上进行训练,机器学习模型在多个任务中展现出了卓越性能。然而,机器学习的这些成功很大程度上依赖于大量完全标注数据,但是在许多实际场景中,很难收集和标注如此大规模的数据集。一方面,我们无法在现实世界中为所有可能的类别收集足够多的数据;另一方面,标注特定种类的数据可能需要专业领域的知识,使得大规模标注非常困难。因此,针对开放场景下标记稀缺的问题,我们将自监督对比学习和新类发现作为主要研究方向,增强在标记稀缺场景下的通用视觉表征能力,并利用有标记样本在无标记数据中发现新的类别。
自监督对比学习通过使用大量无标签数据,利用实例判别的前置任务,训练一个具有通用视觉特征能力的神经网络,能够在下游特定的任务取得接近有监督训练甚至更好的效果。现有自监督对比学习方法可以分成四类,即基于正负样本对比的方法、基于正样本的方法、基于特征去相关的方法和基于一致性正则化的方法。我们提出了一个基于亲和矩阵的自监督对比学习框架 UniCLR,最大化地统一以上的四类方法。尽管这些方法从动机到具体实施的手段都有不同,我们发现从亲和矩阵的角度出发,能够将这些方法通过同一个视角都统一起来。从这个角度来看,当前的绝大多数自监督对比学习方法都可以看作是 UniCLR 的特例或者变体;也就是说,UniCLR 具有较高的灵活性和可扩展性。基于 UniCLR 框架,我们首先提出了 SimAffinity 方法,使用交叉熵损失函数直接优化不同分支特征的亲和矩阵;之后,提出了 SimWhitening 方法,在SimAffinity 的基础上加上了白化操作;最后,基于白化操作的 SimWhitening,进一步提出了 SimTrace方法,去掉了 SimWhitening 中的负样本,仅使用正样本的对比学习进行网络优化。SimTrace 不依赖其他的非对称网络设计,以及其他的正则项来防止模式崩溃。另外还提出了一种新的一致性正则化方法——对称损失,能够加速自监督对比学习的收敛过程。方法结构如图 2 所示,图中,①代表对称损失;②代表基于正负样本对比的 Affinity 损失;③代表白化操作;④代表使用亲和矩阵的负迹损失。
图 2 中,UniCLR 框架使用和其他方法相同的两条分支结构。具体而言,我们将输入图像通过数据增广得到两组不同的图像,并且送入特征提取网络得到两组特征;然后计算两组特征之间的亲和矩阵(相似性矩阵),通过不同方式最大化相似性矩阵对角线上的值,也就是同一对样本的相似度。
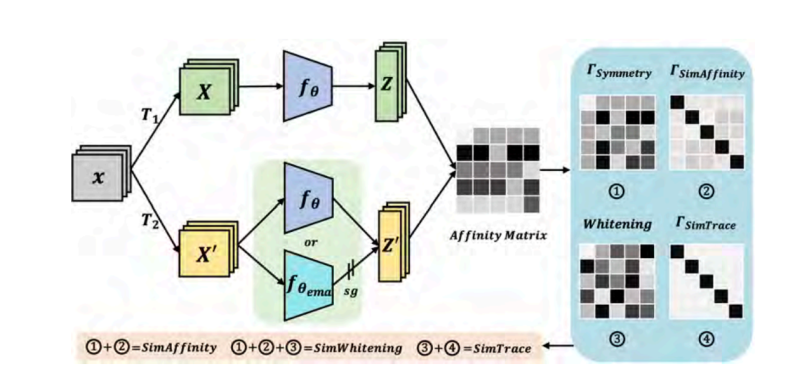
图 2 UniCLR 方法结构
**
**
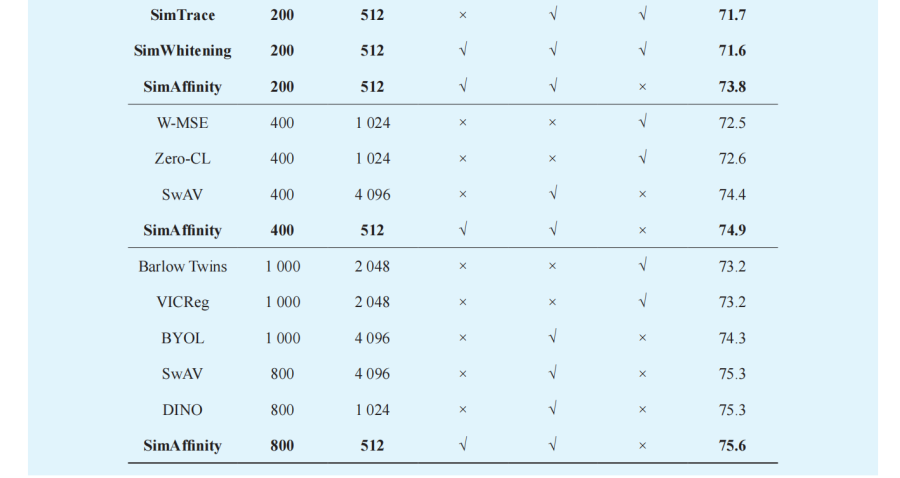
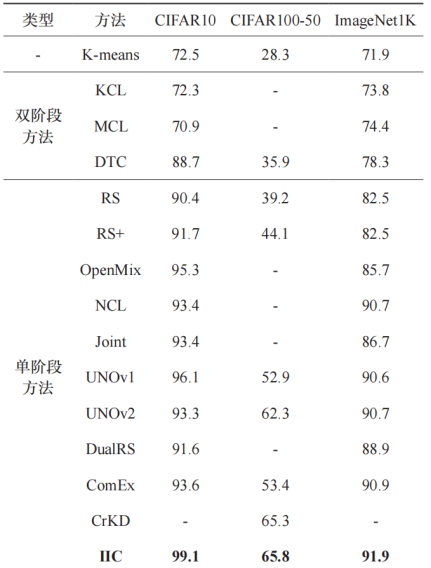
表 1 展示了我们在 ImageNet1K 数据集上和其他先进方法的对比结果。从结果中可以看到,我们方法的三种变体都能够取得较高的结果。在 200 轮次的自监督预训练的测试结果中,SimAffinity、SimWhitening 和 SimTrace 都能够取得相较于已有的方法来说更高的结果。SimAffinity 能够取得 73.8%的 Top-1 准确率,相较于 SimSiam、DINO,以及BYOL 能够分别取得 3.8%、3.6% 和 3.2% 的提升。当进行更长(400、800 轮)的训练时,UniCLR 也能够取得更好的结果。例如,当进行 800 轮的训练时,SimAffinity 可以取得 75.6% 的准确率,超过了SwAV 以及 DINO 相同训练轮次的结果,同时超过了 Barlow Twins、VICReg 和 BYOL 训练 1 000 轮的结果。
表 1 在 ImageNet1K 上自监督预训练的结果与先进结果的对比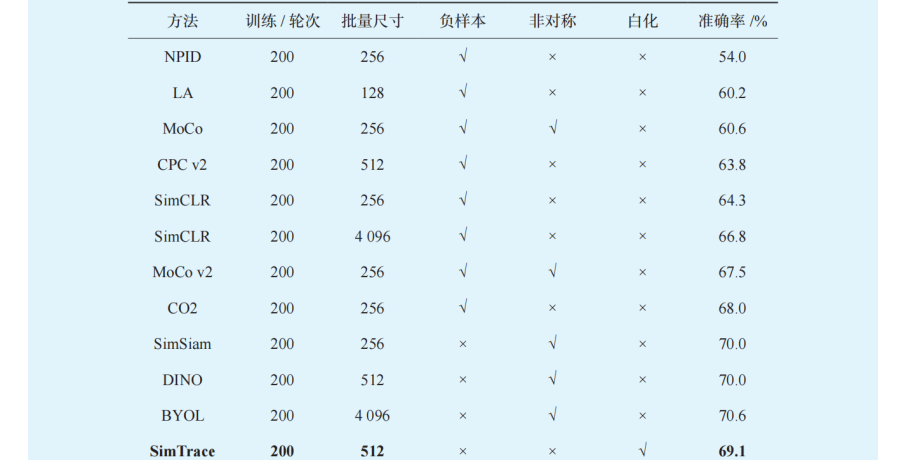
新类发现任务,试图利用已有的标注数据,在无标注数据中自动发现新的视觉类别。给定一个有标签数据集和一个无标签数据集,新类发现的目标是通过有标签数据集中蕴含的潜在语义信息,训练深度学习模型,使其能够将这些信息迁移至无标签数据集,从而识别其中的新类别。我们基于对称 KL 散 度(symmetric Kullback-Leiblerdivergence,sKLD)提出了 IIC(inter-class and intra class constraints)方法,来对新类发现任务中的类间和类内约束进行建模。具体来说,首先提出了一个类间约束来有效地利用有标签类别和无标签类别之间的不相交关系,保证不同类别在嵌入空间中的可分性;其次还提出了一个类内约束,用于确保每个样本与其增广样本之间的内部关系,同时该约束也可以保证整个模型训练过程的稳定性。整体方法结构,如图 3 所示。
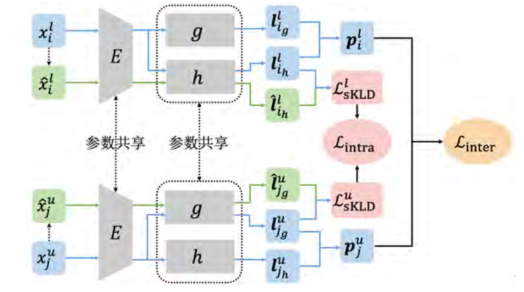
图 3 IIC 方法结构
**
**
图 3 中,蓝色表示“原始部分”(包括有标签样本 xil、无标签样本 xiu 及其对应的原始预测值和概率分布);绿色表示“增广部分”(包括有标签样本的增广 、无标签样本的增广及其对应的原始预测值和概率分布)。IIC 方法整体结构由一个编码器 E,以及两个分类头 h 和 g 两部分组成。编码器 E 在具体实验中被实现为一个标准的卷积神经网络(CNN),它将输入的图像转换为对应的特征向量。用于有标签数据的分类头 h,被实现为一个拥有 cl个输出单元的线性分类器;而用于无标签数据的分类头 g,由一个多层感知机(MLP)和一个拥有 cu 个输出单元的线性分类器组成。在训练阶段,每个样本 xi 首先被 E 编码为特征向量,然后分别通过两个分类头获得对应的原始预测值(logits)
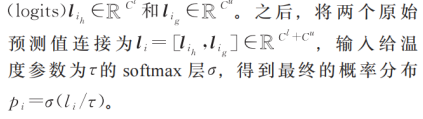
表 2 展示了新类发现方法使用任务感知评估协议在无标签子集的训练图像上的聚类精度,实验结果在标签子集的训练数据上以聚类精度(%)的形式报告,包括均值和标准差两部分。可以看出,所提出的 IIC 方法在所有基准数据集上都优于当前的新类发现方法。
**3 **计算资源稀缺场景下的数据集蒸馏
机器学习方法的成功很大程度依赖于大量训练数据,特别是在当今大模型时代背景下,预训练阶段使用的海量数据集包含从互联网上收集的数十 TB的数据,使用大规模的数据集进行训练意味着需要高昂的计算资源和巨大的时间代价。因此,我们将数据集蒸馏作为一个重要研究方向,通过将大规模数据压缩为一个足够精炼的极小规模数据集,从而减少模型训练所需的计算资源,大大减少训练时间,以适应计算资源稀缺的场景。
表 2 在四个数据集划分上与先进方法进行比较
基于分布匹配方法作为数据集蒸馏的代表性方法之一,通过匹配嵌入空间中的特征分布来实现数据集压缩。但现有的基于分布匹配方法面临两个主要不足,一是合成数据集中同一类内的特征分布分散,降低了类别区分度;二是现有方法仅关注平均特征一致性,缺乏精确性和全面性。我们提出基于样本间关系和特征间关系的数据集蒸馏方法,通过类中心化约束和局部协方差匹配约束来解决上述不足。针对之前方法存在的合成数据集类别区分度不足的问题,我们提出了类中化约束,旨在将从合成数据集中提取的样本特征更靠近类中心,防止特征分散,该约束的损失计算为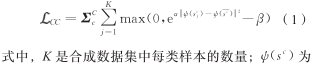
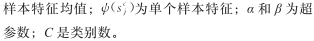


图 4 局部协方差矩阵匹配约束


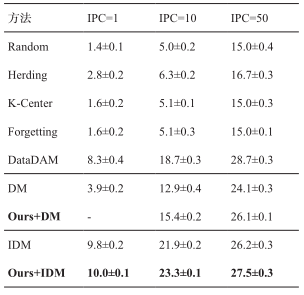
表 3 CIFAR100 数据集上数据集蒸馏任务平均准确率

表 4 TinyImagenet 数据集上数据集蒸馏任务平均准确率
4 结束语
本文主要介绍了我们在开放场景下,针对样本稀缺、标记稀缺和计算资源稀缺等问题开展关于小样本学习、自监督对比学习、新类发现和数据集蒸馏技术的研究,并产生的一系列研究成果。然而,除了上述问题,开放场景中还存在噪音干扰、数据分布偏移、对抗攻击,以及面对序列任务学习时灾难性遗忘等问题。未来,拟针对开放环境下“对抗性攻击 - 鲁棒机器学习、灾难性遗忘 - 持续学习”的问题,为了提高机器学习模型对噪音和对抗性攻击的鲁棒性,以及机器学习模型的持续学习和持续泛化能力,研究防御型机器学习和基于预训练大模型的持续学习技术。 (参考文献略)

李文斌 南京大学副研究员。主要研究方向为新型机器学习、计算机视觉和软硬件协同优化。在IEEE TPAMI、NeurIPS、CVPR、ICCV 等 CCF-A 类国际会议和期刊发表论文 20 余篇。入选中国科协青年人才托举工程。
选自《中国人工智能学会通讯》 2024年第14卷第5期


