大型语言模型(LLM)已经发展到一个连人类都难以辨别一篇文本是由另一个人类还是由计算机生成的程度。然而,了解一篇文本是由人类还是人工智能(AI)生成的,对于确定其可信度至关重要,并且在许多领域中有着广泛的应用,包括检测欺诈和学术不端行为,以及打击虚假信息和政治宣传的传播。因此,AI生成文本(AIGT)检测任务既非常具有挑战性,又极为关键。在本综述中,我们总结了AIGT检测的最先进方法,包括水印、统计和风格分析,以及机器学习分类。我们还提供了有关该任务的现有数据集的信息。通过综合研究成果,我们旨在提供有关在不同情景下影响AIGT文本“可检测性”的关键因素的洞察,并为应对这一重要的技术和社会挑战的未来工作提出实用建议。
https://www.zhuanzhi.ai/paper/712212e3de84cd5c001d13371e155007
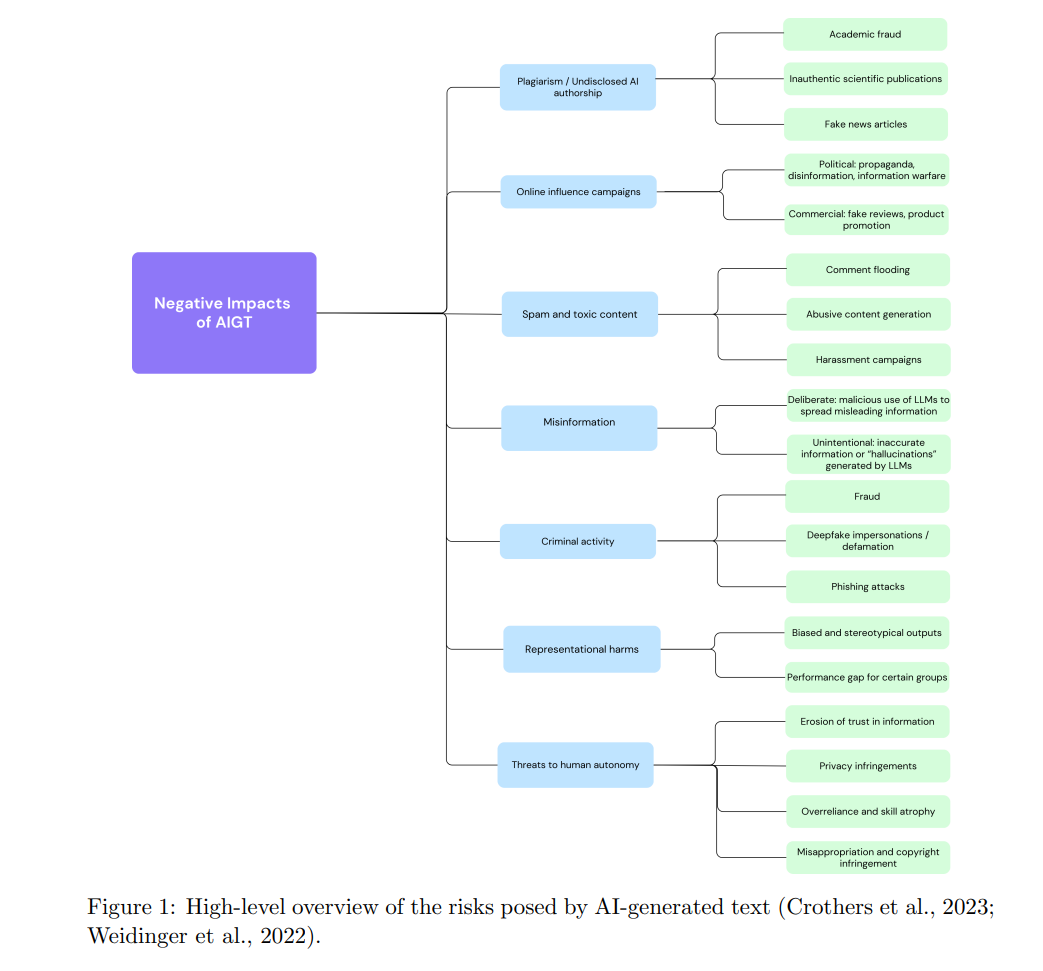
近年来,大型语言模型(LLM)生成流畅、逼真文本的能力取得了显著提高。我们现在已到了人类自身无法可靠地区分由人工智能(AI)生成的文本和由真实人类撰写的文本的地步(Liu et al., 2023; Sarvazyan et al., 2023; Li et al., 2023b)。LLM在提高人类生产力方面有许多机会,可以应用于问答、计算机编程、头脑风暴、校对和信息检索。然而,LLM也存在潜在的滥用领域,如学术不端、职业行为不当和恶意聊天机器人(Crothers et al., 2023; Wu et al., 2023)。生成式AI带来的另一个主要风险是全球范围内的信息污染。这包括故意传播虚假信息以造成危害的虚假信息(disinformation),以及无意中传播的虚假信息(misinformation)(Wardle & Derakhshan, 2017)。这些类别涵盖了广泛的攻击形式,包括宣传、谣言、“假新闻”、欺诈等。当前最先进的生成模型可以生成高质量、流畅的虚假信息,这些信息被认为比人类生成的虚假信息更可信(Zellers et al., 2019; Spitale et al., 2023),而且对人类读者和自动检测系统来说更难识别(Kreps et al., 2022; Zhou et al., 2023; Chen & Shu, 2023)。图1概述了广泛使用AI文本生成工具的一些风险。 为了减轻恶意使用的风险并保护信息生态系统的完整性,开发区分人类撰写文本和AI生成文本(AIGT)的工具至关重要。AIGT检测任务是一个具有挑战性的问题,目标不断变化:随着研究人员开发出有效的方法来检测当前可用的LLM生成的文本,更新和更大的模型被发布,循环继续。此外,试图掩盖其使用AI工具的恶意行为者同时开发针对检测方法的对抗攻击,旨在修改其AIGT使其对当前方法不可检测(Ghosal et al., 2023)。 本手稿概述了AIGT检测领域的现状、最先进的方法、可用的数据资源和在线工具,以及现有的挑战。在本次综述中,我们包括了在同行评审期刊和会议论文集上发表的论文,以及在arXiv等预印本服务器上发布的论文。虽然预印本手稿尚未正式通过同行评审,但我们将其纳入,以覆盖一个快速变化领域中的最新进展。我们主要关注2023年和2024年发表的论文,同时参考了一些早期的奠基性论文。我们仅包括那些专注于AIGT检测的NLP方法的论文,排除依赖其他特征(如发帖频率或社交网络分析)的方法。然而,在NLP领域内,我们广泛搜寻,包括来自不同数据域(社交媒体、新闻报道、学术论文、科学摘要)的方法,旨在提供一个广泛且高水平的领域现状概述。 其他关于AIGT检测的综述也存在,我们建议感兴趣的读者查阅这些文献以获取更多信息。Liu et al. (2023a) 和 Zhang et al. (2024a) 专注于LLM的水印技术。Crothers et al. (2023) 提供了对AI生成文本风险的广泛分析,并评估了检测预ChatGPT模型生成文本的方法。Ghosal et al. (2023) 提供了关于AIGT检测的可能性(检测方法)和不可能性(规避方法)的概述。Uchendu et al. (2023) 更专注于涉及多个人类或AI作者及其组合的作者归属和作者混淆任务。Tang et al. (2024) 提供了对AIGT检测领域主要见解和挑战的易懂总结。两份最近的预印本综述及其相关的GitHub页面也是有用的资源:Yang et al. (2023) 和 Wu et al. (2023)。在当前的工作中,我们希望在现有研究的基础上实现以下目标:(1) 总结快速变化领域中的新兴和最先进的方法;(2) 从更实用的角度看待问题,通过检查在任何特定使用情况下影响可检测性的因素,考虑到并非所有AIGT都是等同的,且检测软件的用户往往对生成文本的模型、输入到模型的提示、底层解码策略以及可能采取的掩盖文本来源的步骤了解不完整。因此,我们希望通过强调AI生成文本的不同特征如何影响不同检测算法的性能,来为AI从业者和研究人员制作一份易懂且有用的文档。 我们首先定义AIGT检测任务并讨论其关键特性(第2节)。特别是,我们强调AIGT并不是一个同质类别;它可以被视为从完全自动生成到具有高度人类影响的文本的光谱(例如,由人类和AI共同撰写的文档,或AI翻译的人类文本)。我们还指定了几个不同的检测场景,以便更好地进行检测算法及其假设的比较分析。然后,我们概述了当前基于NLP的AIGT检测方法(第3节)。这些方法分为三类。第一类是水印技术,涉及LLM的创建者将一个不可检测的信号编码到输出文本中,使得任何拥有水印检测算法的人都可以确定该文本来自该模型。虽然在图像生成中相对简单,但在文本中嵌入水印使其既不可检测又不改变句子含义是一个高度具有挑战性的问题。然后,我们讨论了基于观察到的LLM语言具有不同于人类写作的统计和/或语言特性的途径,即使这些特性并不总是为人类观察者所察觉。许多这些方法利用了LLM构建句子时总是选择在给定上下文中最有可能出现的词的基本原理,而人类在选择上则更为多样。因此,文本统计规律性的度量可以提供有关来源的一些见解。最后,我们还描述了使用预训练语言模型作为文本分类基础的工作。这种方法不需要特征提取步骤,而是直接从人类和AI的文本示例中学习。 我们列出了一份(非详尽的)当前可用的数据集清单,这些数据集包括人类撰写和AI生成的文本,可用于训练和/或测试AIGT检测系统(第4节)。数据集在几个重要轴线上有所不同,包括领域(例如,新闻、社交媒体、学术写作)、语言和生成模型设置。在许多情况下,不同参数之间的泛化能力似乎很低,因此选择适合特定应用的数据集至关重要。 在讨论了方法和数据集之后,我们概述了影响给定AIGT样本可检测性的一些不同因素(第5节)。我们讨论了生成模型的属性(模型大小和解码策略)、文本语言、文档长度、分布内和分布外输入、人类影响程度和对抗策略等因素。这些不同因素的全面表征将帮助用户选择适合特定情景的检测方法和训练数据集。 最后,我们总结了研究成果,并在为特定应用设计解决方案时提供高级建议(第6节)。我们通过强调现有的挑战和未来工作最有希望的方向(第7节)来结束。随着LLM在我们生活中的普及以及其能力和流畅性不断提高,AIGT检测将成为研究人员、政府和公司需要合作解决的一个困难但至关重要的问题。 AIGT方法
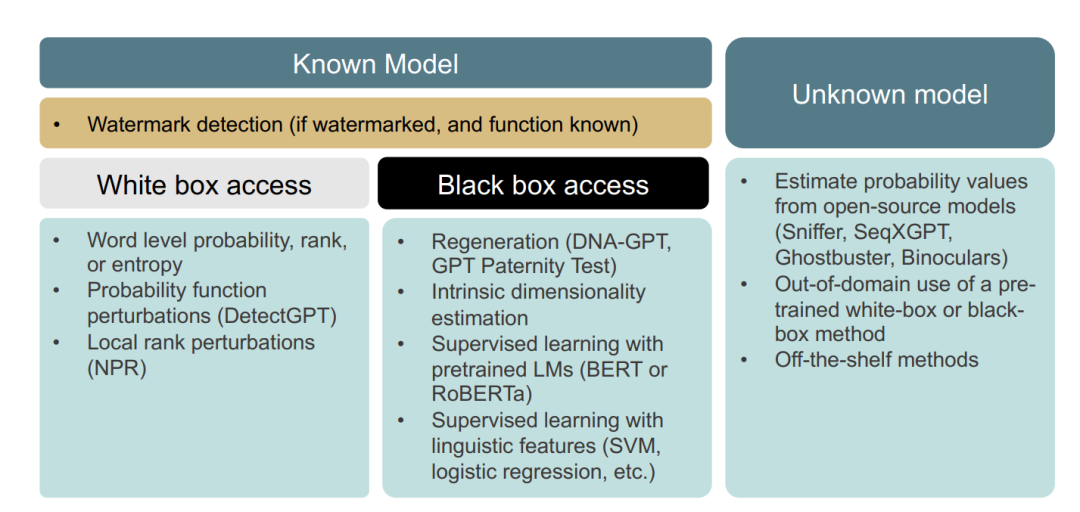
选择使用哪种检测方法取决于许多因素。在第2.3节中,我们概述了最常见的检测场景;现在我们在图3中结合本节介绍的不同方法重新审视这些类别。
水印检测策略
水印检测策略的使用能力当然取决于文本是否首先被添加了水印。在这种情况下,只需要访问水印提取功能,而不需要访问生成模型本身;但是,假设模型是已知的。
已知模型且无水印的检测方法
在模型已知但未加水印的情况下,如果我们可以访问内部参数,则可以使用基于单词或序列的概率、困惑度和熵的方法来帮助检测由该模型生成的文本。另一方面,如果已知未加水印的模型但我们只有黑箱访问,则可以使用重生成策略。另一个针对已知模型、黑箱访问场景的标准方法是监督学习,首先提取语言/风格特征并训练低维分类器,或基于原始文本微调高维预训练语言模型。
未知模型的检测方法
如果生成模型未知,我们必须使用已知模型作为代理。这可以涉及基于开源模型估计概率值,或者使用在其他模型上训练的分类器(或现成工具)。在这些情况下,我们依赖于AIGT的一般特性,这些特性预计无论生成文本的具体模型如何都成立。然而,实验结果表明,当应用于未知模型生成的文本时,大多数方法的检测性能有所下降。 在实践中,还有许多其他因素会影响上述检测方法的性能。这些因素将在第5节中详细讨论。然而,我们首先总结了可用于AIGT检测的现有数据集。
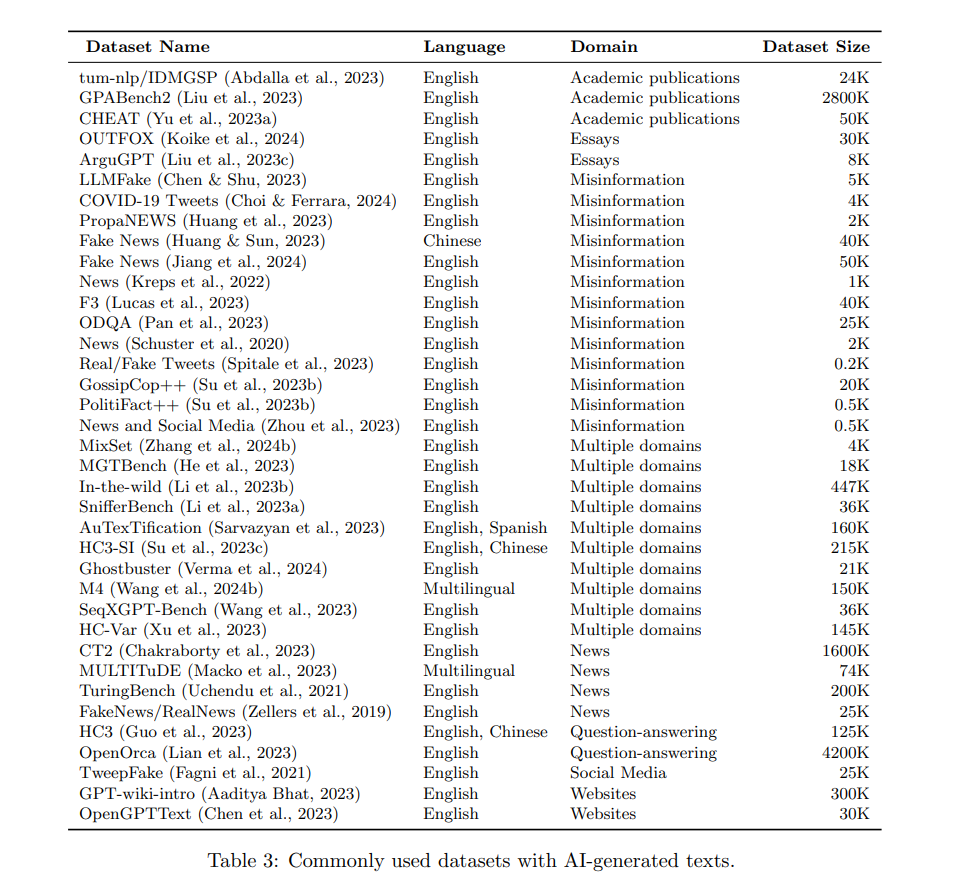
AIGT 数据集
如前文所述,有三种主要方法用于检测AI生成文本(AIGT):水印技术、统计和风格分析,以及使用预训练语言模型(LMs)。检测水印需要了解水印提取算法;除此之外,不需要额外的数据。然而,其他两种广泛的检测方法需要数据来学习区分AIGT和人类撰写文本的模式——理想情况下,一个数据集的正例是由我们希望检测的AI模型生成的,并且在我们期望在现实世界中遇到这些文本的环境中生成。先前的研究表明,最有效的检测器是在与测试数据相同领域(新闻文章、社交媒体帖子、学术论文等)、语言(英语、中文、法语等)和模型设置(解码算法、提示、输出长度等)的数据上训练的。同时,研究也表明,为了最大限度地提高泛化能力和鲁棒性,必须在各种各样的数据上训练检测器,以避免过度拟合到一个非常狭窄的数据样本范围。因此,对于任何特定应用,选择适当的数据来首先训练检测器以及测试检测器的准确性是很重要的:“黑箱检测模型的有效性很大程度上依赖于获得数据的质量和多样性。”(Tang et al., 2024) 表3列出了一些最常用的数据集,这些数据集包括人类撰写和AI生成的文本。我们注意到,绝大多数可用的数据集是英语的,另有相当一部分是多语言的(包括英语以及其他语言)。在自然语言处理(NLP)领域存在一个众所周知的偏见,即许多研究集中在英语上,而忽视了其他语言。这种偏见无疑因许多用于生成这些数据集的大型语言模型(LLMs)最初仅提供英语版本而加剧。然而,随着越来越多的多语言LLMs的出现,我们预计这种情况将继续改变。在英语之外的语言中,中文的代表性最强。