导语
近年来,采用深度学习对图结构数据建模的方法取得了巨大进展,并改变了模型理解关系结构的能力。在集智俱乐部「图神经网络与组合优化」读书会中,耶鲁大学计算机科学系助理教授应智韬(Rex Ying)介绍了利用图结构在多种机器学习场景中实现复杂推理的探索,尤其是聚焦在基础模型中的应用,包括在对比学习中用邻近图捕捉相似关系,稀疏 Transformer 通过图扩散来扩散注意力、降低模型复杂度,GNN学习分子图表征,思维传播利用关系推理增强大模型的复杂推理能力。本文由社区成员刘佳玮整理成文。************
研究领域:基础模型,多模态,关系推理,图神经网络,对比学习****************************************************************
目录0. 基础模型概述1. 模型架构中的关系结构** - 邻近图捕捉相似关系** - 稀疏 Transformer2. 任务中的关系结构 - GNN学习分子图表征3. 推理中的关系结构** - 思维传播4. 总结**
0. 基础模型概述
“基础模型”(foundation model)一词最初由斯坦福大学的 Bommasani 等人提出,定义为“在广泛的数据上训练且可以被应用于广泛的下游任务的模型”。人工智能向基础模型的范式转变意义重大,允许用更广泛的通用模型替换几个狭窄的任务特定模型,这些模型一旦经过训练就可以快速适应多个应用程序,并且随着模型参数增大,有可能展现出“涌现”能力。
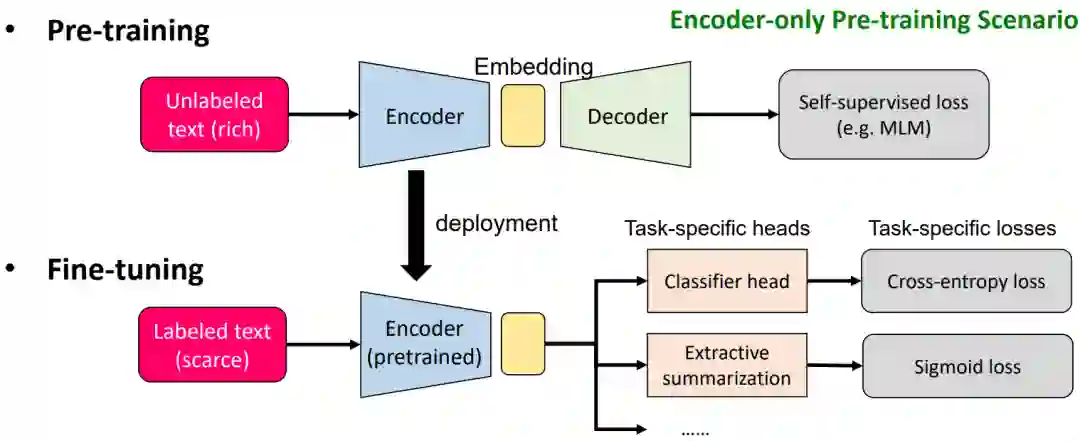
当谈及基础模型时,我们的定义可能会更加广泛,不仅仅包括大语言模型(LLM),还涵盖了基于自监督学习框架的各种基础模型。这些模型通常会在最终任务上进行微调。这种范式在机器学习领域的作用日益增大。以ImageNet为例,它之所以取得成功,主要是因为当时人们普遍崇尚监督学习。ImageNet手动标记了1400万张图像,这为监督学习提供了数据基础,从而推动了视觉领域的巨大进展。然而,在大多数情况下,这种方法并不可行。例如,自然语言处理涉及众多任务和大量翻译工作,不可能让人逐一完成。此外,我们获取的数据往往是无监督的。因此,基础模型的最大优势在于,即使在没有监督的情况下,我们仍然可以利用大量数据来开发通用模型,适用于各种不同的下游任务。下面是一个传统的基础模型框架:
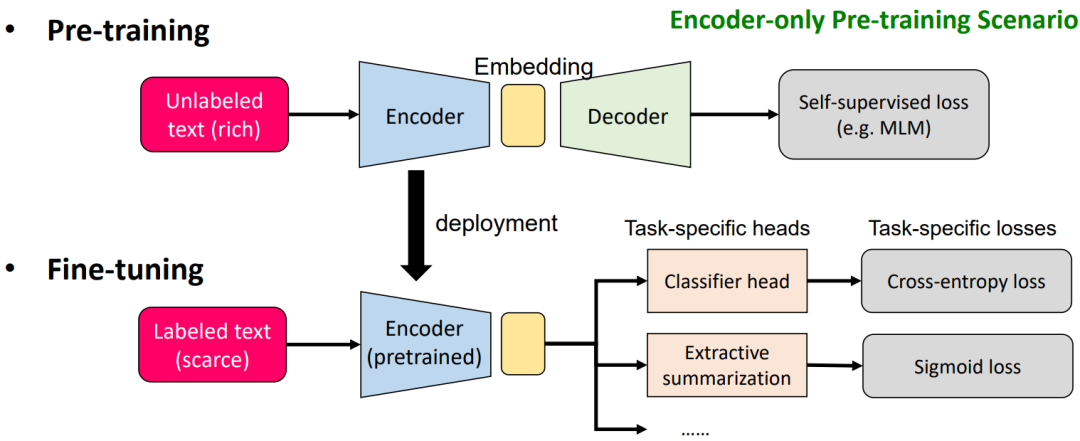
这个过程主要分为预训练(pre-training)和微调(finetuning)两个步骤。在预训练阶段,我们采用自监督学习方法,例如使用语言模型。首先,我们使用一个编码器,例如 transformer,对输入数据进行编码,然后得到一些嵌入(embedding)。接着,我们再从这个嵌入进行解码。在解码后,我们会采用一种自监督损失函数,例如掩码语言模型(mask language model)。完成预训练后,在微调阶段,我们将编码器固定下来,不再需要对该部分进行优化或仅优化很小一部分。然后,我们将输入数据直接通过这个编码器得到一个embedding,再从这个embedding进行各种下游任务的处理,包括文本分类、摘要和翻译等。在此过程中,我们会采用各种损失函数来微调下游任务。
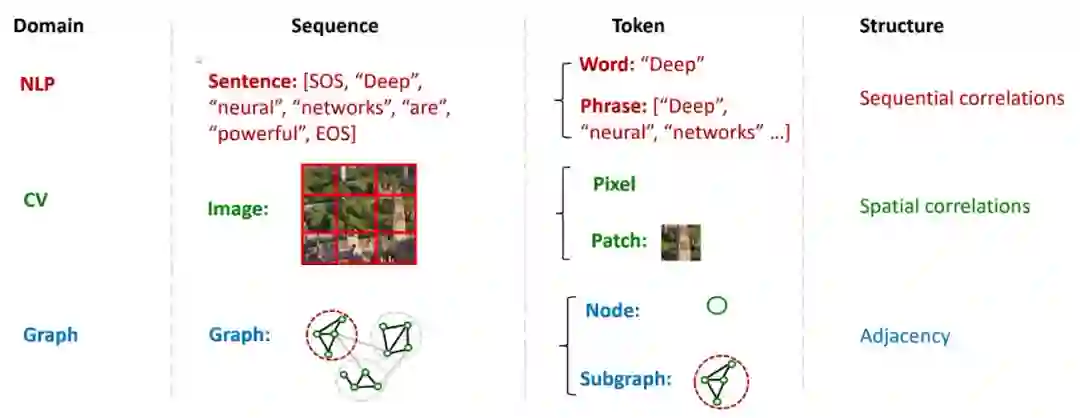
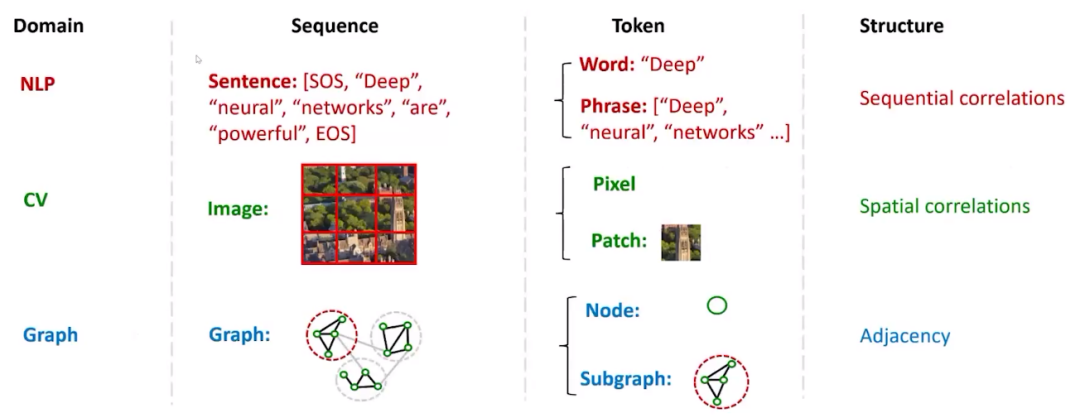
需要注意的是,如果是GPT模型,需要迁移的部分不再是编码器,而是解码器(decoder)。然而,整体框架基本保持不变。对于图像基础模型的训练,同样可以采用这个框架。只需将输入数据从文字转换为图片,并采用编码器-解码器架构来获得自监督损失。在微调阶段,同样可以将编码器迁移过来,训练各种下游任务。这个框架在不同类型的数据(图、图像、文字等)中具有很高的通用性。 接下来,我们要考虑不同数据的模态。在**自然语言处理(NLP)领域,文本通常以句子的形式呈现。在每个句子中,我们能看到不同的单词,它们组成了不同的词组。类似地,在计算机视觉(CV)领域,数据则以图片的形式出现,而图片的基本单元可能是像素。在图****(Graph)**中,图的构成单元是节点,许多节点组成一个子图。
1. 预训练中的关系结构
我们从预训练开始谈起,也就是自监督学习。自监督学习通常分为两大类:生成式和对比式。生成式的任务主要是掩码语言模型,即将数据的一部分进行掩码,然后让模型进行恢复。而对比式则不是生成被掩码掉的内容,而是去区分相似的和不相似的数据。对比式自监督算法通常具有较高的有效性,因此我们今天分享的第一项工作是关于对比学习(contrastive learning)的形式。
对比学习是一个非常简单的原则。在许多数据中,有些数据点是相似的,有些则相距甚远。如果模型能够区分出哪些东西相似和哪些东西相距甚远,我们就达到了自监督学习的目的。如果这个嵌入空间能够捕捉到这样的属性,那它就是一个很好的嵌入方式。因此,在训练时,我们会使用这样的目标:输入一些相似的数据点和一些不相似的数据点,将这些数据全部编码到嵌入空间,然后在嵌入空间上进行对比学习。这样做的结果是,我们需要把相似数据的嵌入变得尽可能接近,不相似的数据的嵌入尽可能远离。这是一个大致的原则,比较容易理解。
一般来说,对于每个需要进行对比学习的数据点,我们定义一个锚点(author)。锚点的意思是,我们可以创造一些正例(positive example),就是一些跟自己很相似的东西,还有一些负例(negative example),一些跟自己很不相似的东西。我们可以通过把嵌入空间里面相似的拉近、不相似的拉远来做自监督学习。如果没有标签监督的情况下我们怎么样去找哪些是正例哪些是负例呢?一般来说,做这种对比的方式,就是我可以对自己的锚点做一些变换。比如图片不管怎么旋转、位移,进行各种各样的变换,这个图片的语义不会有什么区别,变换以后我们依然能够认出来它是同一个物体。所以经过变换可以创造一些正例,这样的准则在图里面也经常会用。比如一些图对比学习的方法,会把一个节点的邻居进行随机游走来进行采样。然后把它作为对邻居的扰动,可以得到一些类似的邻居,那这些就是我们的正例。有了这个以后,我们就可以定义各种对比学习的损失函数(例如 InfoNCE),然后在这个InfoNCE的框架下,我们不光是要找正例,还得找负例,怎么找负例是一个问题。
我们想象什么样的负例会更有用,看一下可能会出现什么样的负例。我们可以有简单负例(easy negative),例如图3中最左边的负例跟一开始的图像完全不同。即便这个模型非常笨它也能够区分出它们不同。然后中间是稍微难一些的负例,这些负例就比较有趣,比如说它们可能都是猫科动物,但是它们可能是不同的动物,那这些就是一些困****难负例(hard negative),因为模型需要有更多的知识才能发现它们是不同的东西。然后最右边叫做伪负例(false negative),因为它们其实是同一个物种,所以模型没有必要把它们当做负例。如果是负例的话,通过InfoNCE这些负例之间的距离在嵌入空间上很远,这没必要,因为它们都是同一种。或者说即便我们需要区分,但是它们不应该被拉得非常远。然后在这三种里面什么对增加模型的表现能力更有效?很显然大家都会觉得是困难负例,因为它可能比较像,但是并不完全一样。所以这更能够考验模型的辨识能力。所以困难负例是我们比较关心的,然后它可以是有不同的表现形式。比如说它们可以是背景、花纹比较相似,但其实是不同的动物。

- BatchSampler:用邻近图捕捉相似关系
这个工作是讲者的学生还有唐杰老师的学生一起合作的一个项目,研究的动机是用邻近图(proximity graph)去捕捉相似的关系。就是说,有各种各样的数据点,它们可以是图也可以是图像、文字或者各种想要做对比学习的数据,我们把它转换成图的形式,每个节点代表一个数据点,这些数据点之间的连线就代表他们的相似度,只有当这两个节点非常相近的时候,我们才会把他们连起来。然后我们通过这个图来讨论怎样采样好的困难负例,就是那些看上去很像但其实是不一样的负例。这个图的构造其实非常简单,首先我们有一个正在做对比学习的编码器,然后我们把节点编码到这个嵌入空间,然后做最近邻等操作构建邻近图,基于这个图做一些操作寻找负例。我们的方法通过有重启的随机游走(random walk with restart)来探索局部邻域,它的好处在于灵活性。我们可以想象困难负例一般在哪儿,他肯定不是最近的几个,因为最近的可能是同类,即伪负例。肯定也不是很远的,因为这些点肯定是完全不相关的简单负例。我们的方法可以通过超参数控制重启概率,论文发表在KDD2023上,感兴趣的读者可以看一下。Yang Z, Huang T, Ding M, et al. BatchSampler: Sampling Mini-Batches for Contrastive Learning in Vision, Language, and Graphs[J]. arXiv preprint arXiv:2306.03355, 2023.
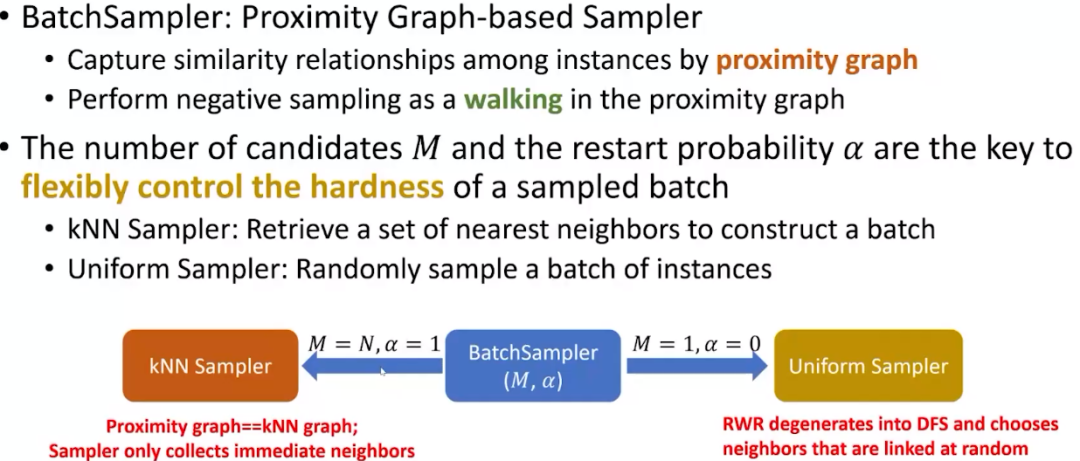
我们把这个方法叫做BatchSampler,它的想法就是通过在邻近图上做随机游走来控制采样到一些很高质量的负例。我们有一些超参数,首先就是最近邻的数量,还有就是随机游走的重启概率。可以想象,当重启概率是1的时候,也就是每走一步就会回到原点,那其实就是找一阶邻居,得到的样例很难。另一个极端是重启概率为0,那就是纯粹的随机游走,很容易走到很远的地方,获得很简单的样例。通过调重启概率,我们就可以找到想要难度的样例,这种方法可以用在各种模态的数据上面。
- 稀疏 Transformer:通过图扩散来扩散注意力,降低模型复杂度
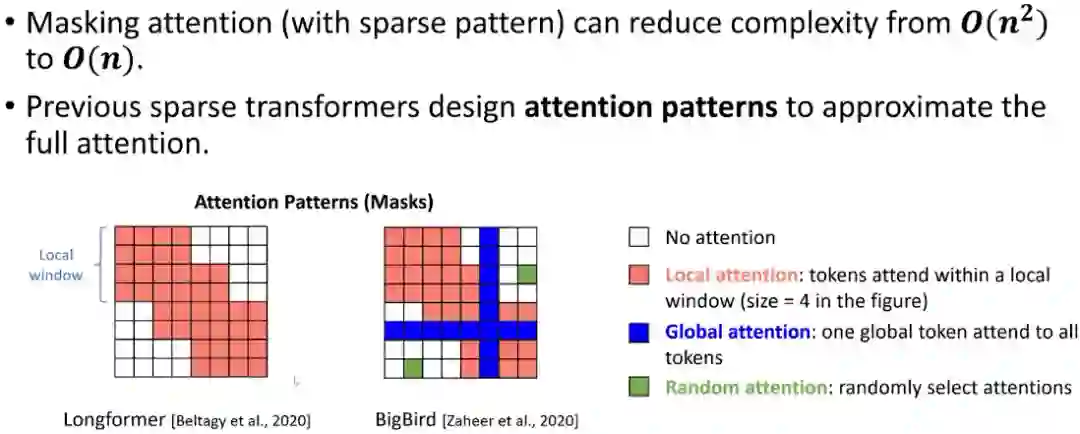
接下来我们用图的角度解释Transformer架构。由于Transformer架构的复杂度主要来自注意力机制,它的复杂度是O (token*token),这给Transformer应用于长序列带来了挑战。稀疏Transformer可以显著降低复杂度,我们可以将其想象成图的形式,这种注意力矩阵很像图的邻接矩阵。稀疏Transformer的核心思想是用局部注意力和随机注意力取代全局注意力,局部注意力是指设置一个很小的窗口,而随机注意力是指随机找一些连接来计算。
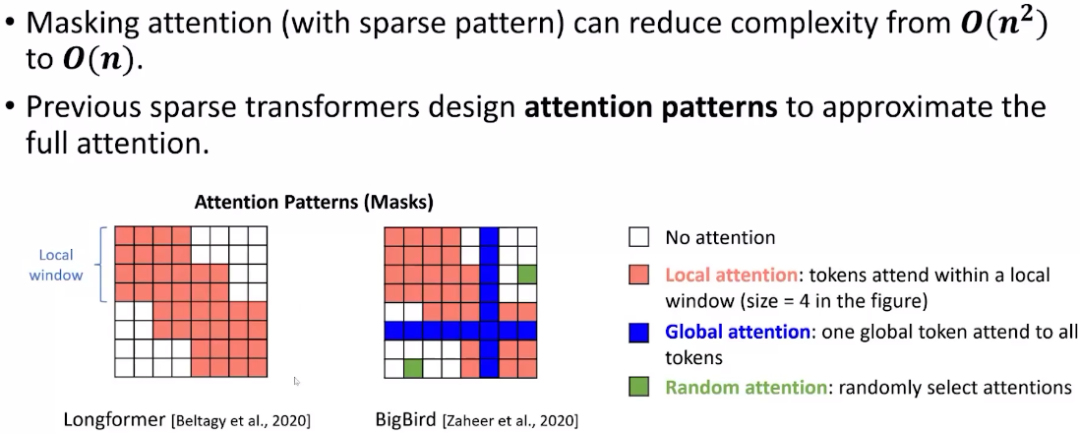
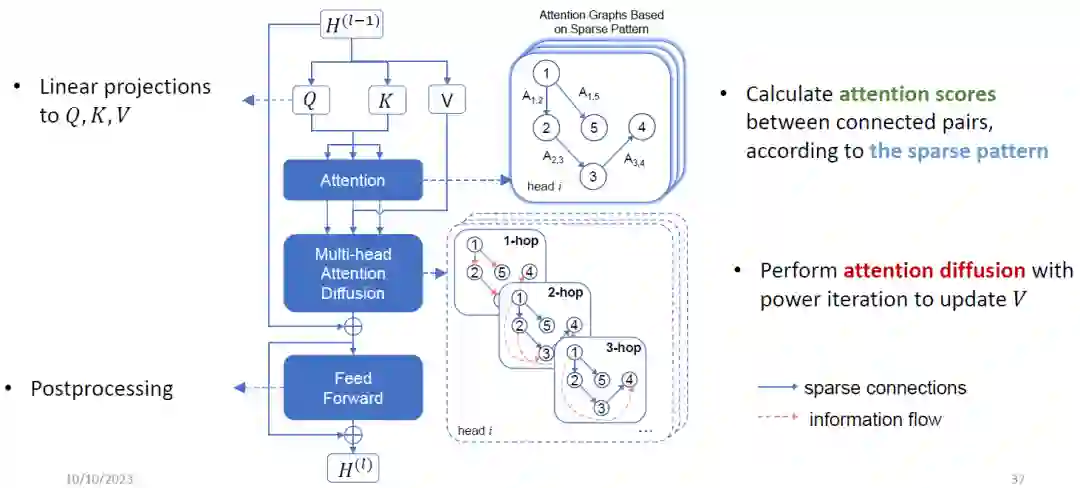
这样做可以节省时间和空间,但也有一些挑战。如果我用局部窗口的话,感受野就会降低,也就是我没法直接在每一层通过算自注意力机制来增加模型的表达能力。还有一个问题是它可能会对序列的扰动敏感,不够鲁棒。为此,我们希望模型能够具有全局注意力,并且降低模型复杂度。在AAAI的工作中,我们把稀疏Transformer当成一个稀疏图,然后通过图扩散的方式来扩散注意力的值,从而在Transformer模型上探索结构。这样做的好处是很多格子是通过扩散算出来的,不需要反向传播,从而能够节省很多计算和存储开销。Feng A, Li I, Jiang Y, et al. Diffuser: efficient transformers with multi-hop attention diffusion for long sequences[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2023, 37(11): 12772-12780. 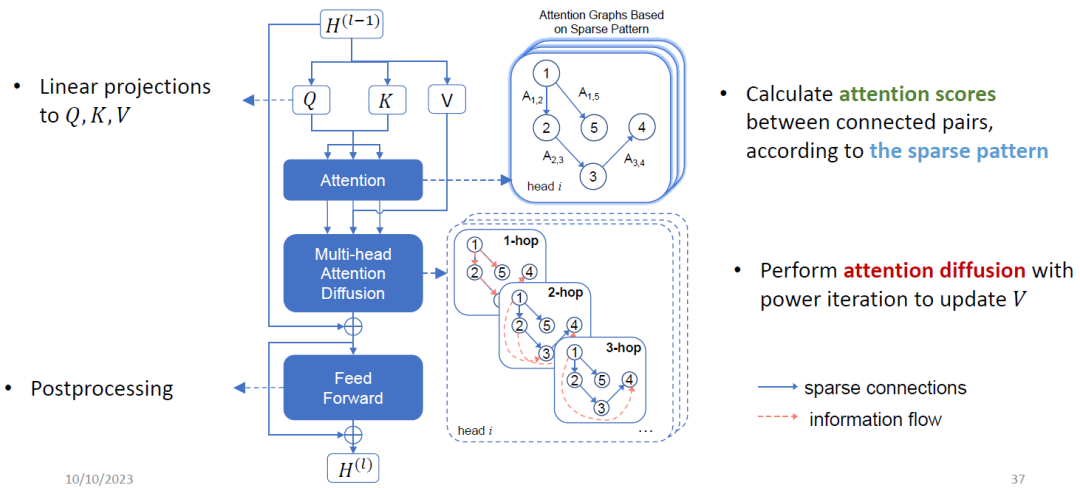
*2. 微调中的关系结构
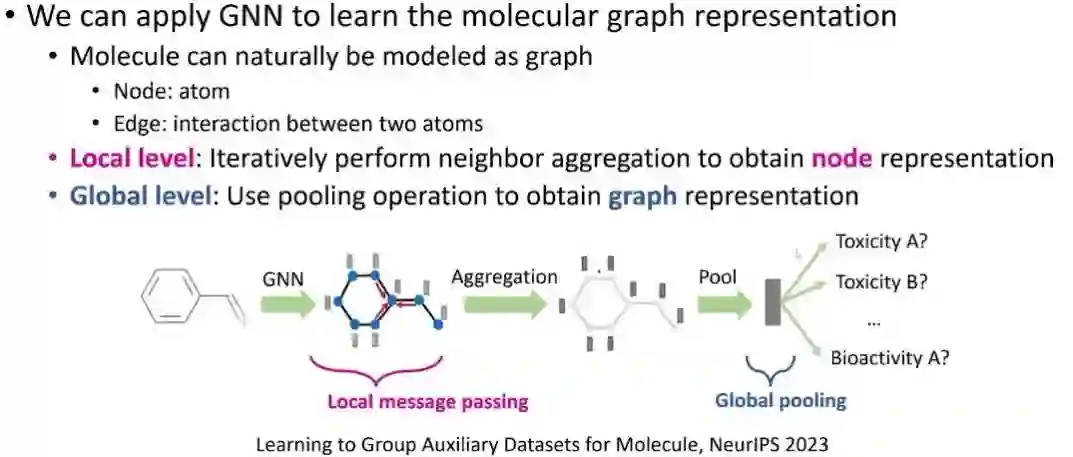
- GNN学习分子图表征
在做微调的时候也有一些有意思的技巧,这里关注分子结构的基础模型,怎样通过不同的任务和任务之间的相似度来增加模型微调的表现。这里介绍一篇最近发表在NeurIPS上面的论文。在分子结构上,我们可以有各种下游任务,例如可溶性、毒性或活性预测等,这是一个非常适合基础模型的场景。基本架构就是用GNN去编码一个分子输入,得到每个节点(原子)的嵌入,然后通过聚合或者池化操作得到分子的嵌入,然后预测各种分子级别的下游任务。Huang T, Hu Z, Ying R. Learning to Group Auxiliary Datasets for Molecule[J]. arXiv preprint arXiv:2307.04052, 2023.
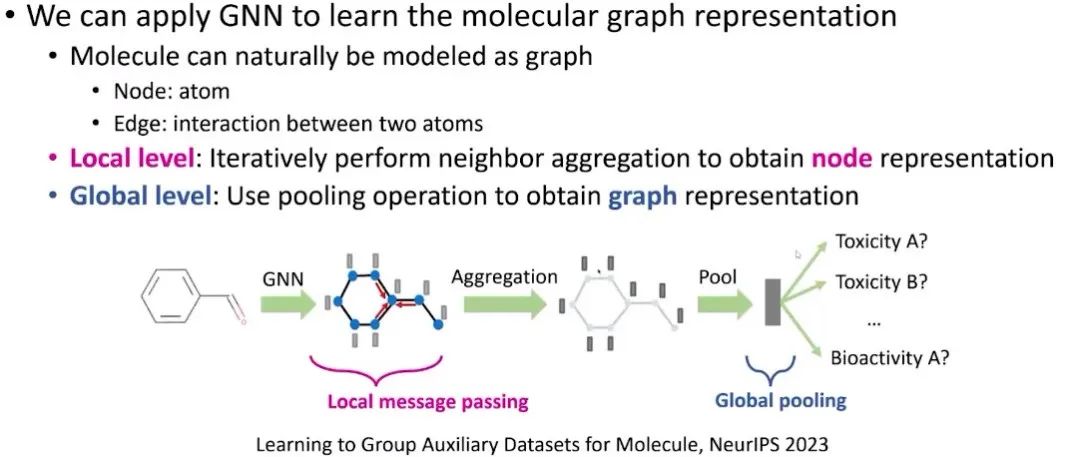
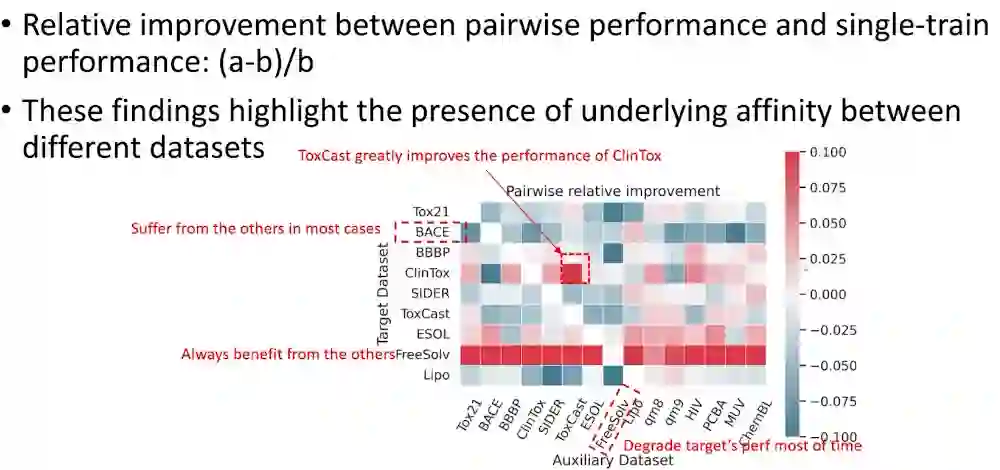
图上的预训练任务通常可以是生成式任务也可以是对比式任务,但对于分子结构来说仍然是一个非常有挑战性的话题。首先,有标注的数据集很少,往往需要昂贵的领域知识来建立。然后往往它们用的分子也都是不一样的。一个比较自然的想法是说,因为这些下游任务都非常小,所以我们能不能结合多个下游任务,比如把几个毒性相关的下游任务和数据放在一起来做微调。通过从基础模型微调的形式去改进可能会是一个更加有效的策略。但这样做有一个问题就是很容易出现负迁移。我们观察一个数据集是否能帮助另一个数据集,红色表示提升很明显。我们可以看到有些规律,例如几乎所有数据集都可以帮助FreeSolv数据集。
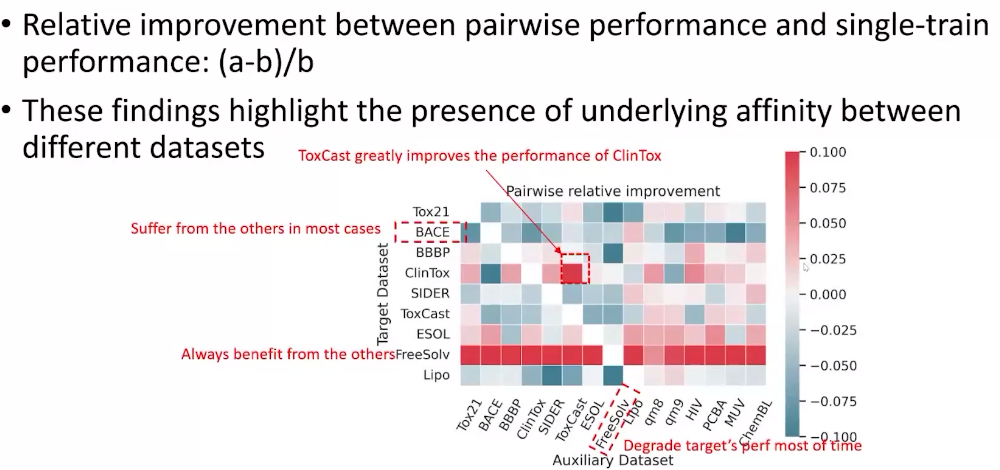
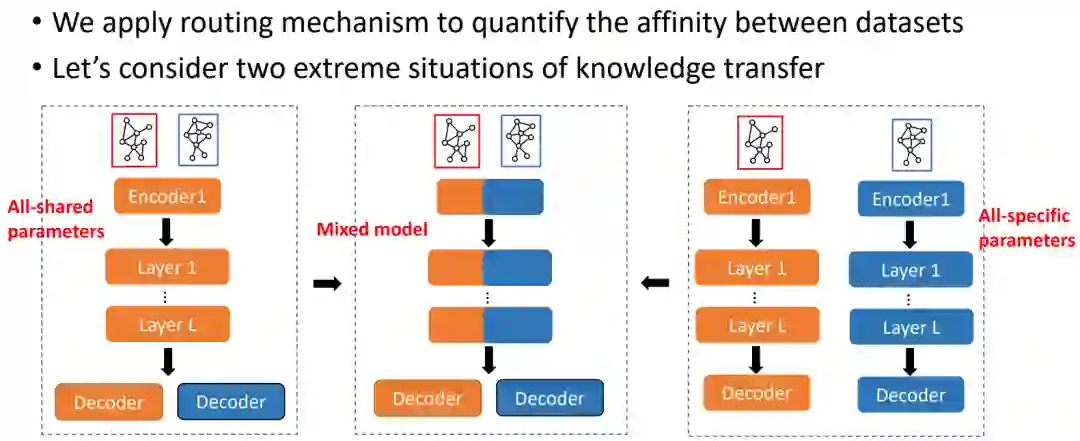
那么能否找到对某个数据集有帮助的数据集呢?我们觉得两个数据集之间的关系分为两种,一种是结构的相关性,另一种是任务的相关性。描述这两种相关性的方式很多,这里不展开讨论。基于这些相关性,我们就可以把单个任务转化成一组任务。在训练的时候,我们就可以把这些数据放到一起算损失。假设这两个数据集关系非常紧密,辅助数据集是非常有用的,那就可以用同一套编码器,只用不同的解码器做不同的任务。另一个极端是,如果两个数据集或者下游任务完全无关,就应该使用两套编码器来训练,才能得到最好的效果。很多情况可能介于两种极端情况之间,他们的任务可能在分布上相似又有一定的区别,这就应该采用中间的混合形式,部分参数共享。
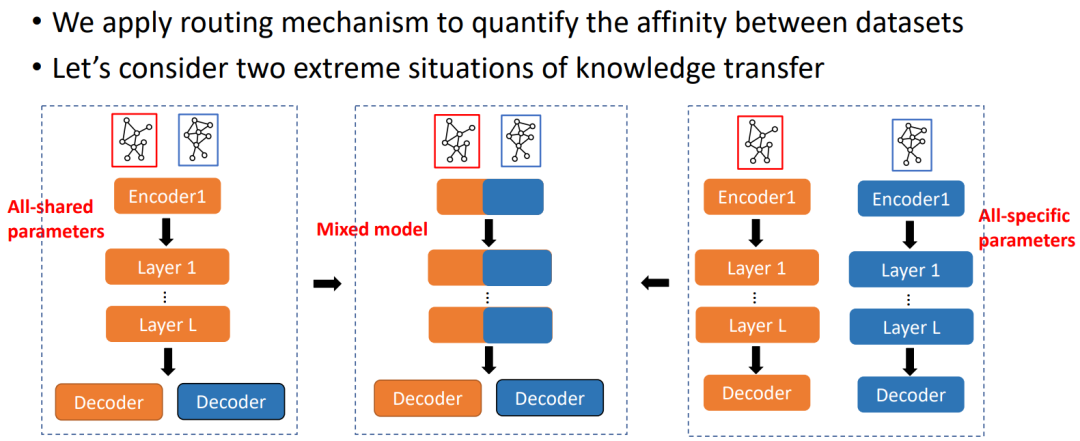
我们建议使用路由机制来动态分配每个辅助数据集对网络子层目标数据集的影响。路由机制的学习取决于辅助数据集的梯度如何影响目标数据集的性能。然而,以目标数据集感知的方式优化这种路由机制具有挑战性,因为它仅在辅助数据集的前向传递期间使用。为了解决这个问题,我们建议使用双层优化框架,并使用元梯度(meta gradients)来自动学习任务的相似度。双层优化框架分为两个步骤:首先,利用辅助任务的梯度更新除路由函数外的模型参数;其次,我们重用这个计算图并计算路由机制的元梯度。

3. 推理中的关系结构
- 思维传播:用大模型进行复杂推理
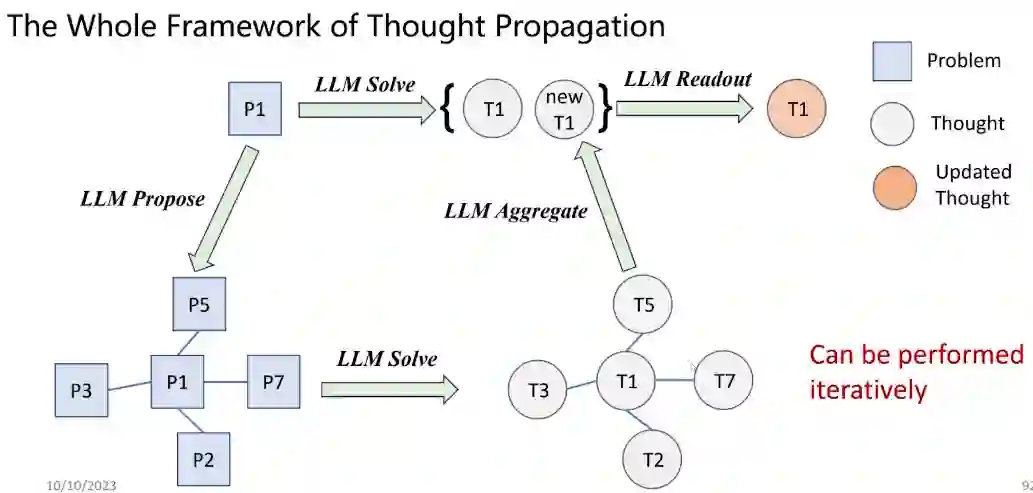
关系推理能否在大语言模型的推理阶段有所帮助呢?目前比较流行的方式是通过设计各种各样的提示(prompt)来使大语言模型更好地解决一些复杂问题,例如思维链(chain-of-thought)、思维树(tree-of-thought)和思维图(graph-of-thought)等,但这些方法还不够高效。鉴于目前的prompt是独立的,所以能否通过探索问题之间、解之间的关系来帮助模型有更强的推理能力,这种方式我们叫做思维传播(thought propagation)。
思维传播包含如下几个步骤。首先,LLM Solve使用基础的提示方法解决输入的问题。然后,LLM Propose是指提示LLM去提出一些相似的问题,这些问题都可以用LLM来解决。然后我们会分别得到一些解,这些解就是模型对于之前问题的回答。然后根据这些回答,我们进行聚合或者投票来得到当前问题的回答,这就叫 LLM Aggregate。最后的LLM Readout就是判断新的解和旧的解哪个更好,或者二者能否结合得到更好的解。Yu J, He R, Ying R. Thought Propagation: An Analogical Approach to Complex Reasoning with Large Language Models[J]. arXiv preprint arXiv:2310.03965, 2023.
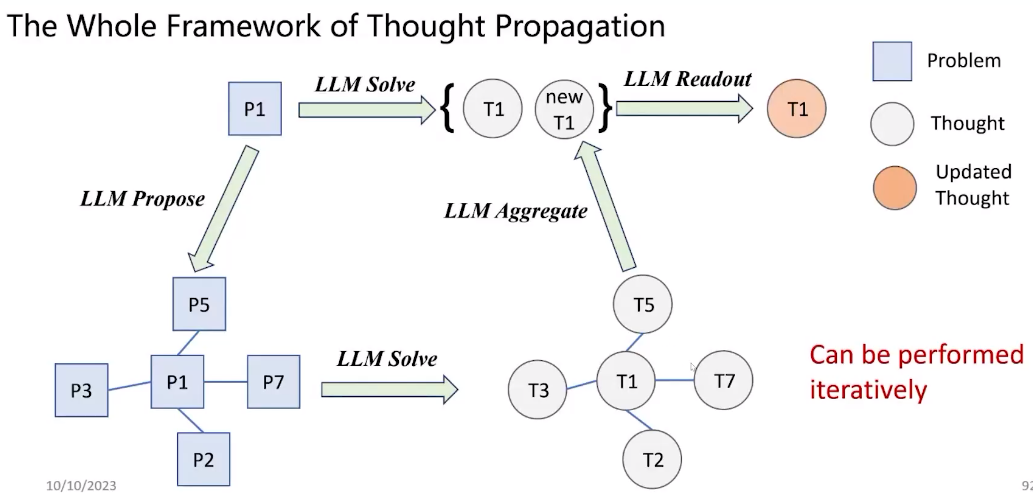
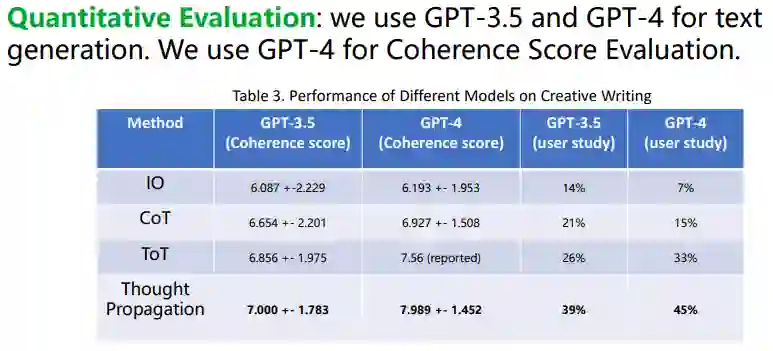
研究中做了大量实验来验证方法的有效性,想要进一步了解可以参考论文。这里展示一个创意写作的实验,就是给一些句子写四段话。要求这个故事是连贯的,连贯度可以通过LLM或者人类进行打分。我们把这个问题拆解成四个阶段。首先,LLM Solve就是写四段话的问题。然后,LLM Propose阶段采用重写策略作为提示,就是说写四个类似意思的句子然后用他们写四个连贯的段落。通过这个提示,可能生成一些类似的任务,然后在LLM Solve阶段分别解决这些任务。然后我们可以做传播和读出操作,也就是通过比对各种写作计划,把他们综合成一个更加连贯的故事。

我们可以用各种LLM去解决这个问题,然后用GPT-4评估连贯度。可以看到,GPT4的连贯度比GPT3.5要更好,思维传播也比之前的方式效果更好。请一些人类参与打分也发现,思维传播比之前的方式效果更好。 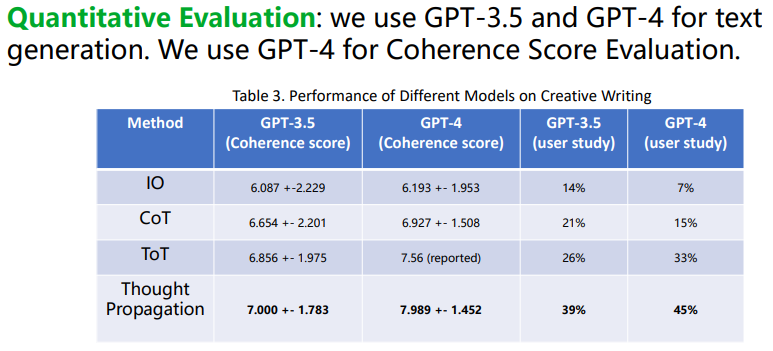
4. 总结
总结一下,关系推理在基础模型中还是有很多用途的。即便很多情况下问题和图看上去无关,但我们可以把问题建模成图的形式。讲者主要分享了关系推理在基础模型的不同阶段中的应用。总的来说,讲者认为有两个方面非常重要。一个是基于基础模型的神经表示,另一个是基于图的符号表示。如果二者可以完美融合,在长远上看会有很大的帮助。
学者简介