

在当今快速发展的军事领域,推进人工智能(AI)以支持兵棋推演变得至关重要。尽管强化学习(RL)在开发智能体方面大有可为,但传统的 RL 在处理作战模拟固有的复杂性方面仍面临局限。本文提出了一种综合方法,包括有针对性的观测抽象、多模型集成、混合人工智能框架和总体分层强化学习(HRL)框架。使用片断线性空间衰减的局部观测抽象简化了强化学习问题,提高了计算效率,并显示出优于传统全局观测方法的功效。多模型框架结合了各种人工智能方法,在优化性能的同时,还能使用多样化、专业化的个体行为模型。混合人工智能框架将 RL 与脚本智能体协同作用,利用 RL 进行高级决策,利用脚本智能体执行低级任务,从而提高了适应性、可靠性和性能。HRL 架构和训练框架将复杂问题分解为易于管理的子问题,与军事决策结构保持一致。虽然最初的测试并未显示出性能的提高,但获得了改进未来迭代的见解。这项研究强调了人工智能在兵棋推演中的革命性潜力,并强调了在这一领域继续开展研究的必要性。
兵棋推演中的 “半人马”概念
正如 CeTAS 报告所详述的那样,利用人工智能支持兵棋推演的方法有很多。不过,本文将重点关注人工智能在创建智能体方面的应用,这些智能体能够在现代作战建模与仿真 M&S 中典型的庞大而复杂的状态空间中做出理性决策。
然而,创建一个能够在游戏中获胜或超越人类表现的人工智能,仅仅是表明人工智能能够为兵棋推演者、作战规划者和军事领导人提供有意义的见解的开始。尽管如此,这些智能体是开发现代决策辅助和支持工具的基础,与传统工具相比,它们能为决策者提供更高的准确性、速度和敏捷性。当在多领域行动中与装备了人工智能的对手作战时,忽视这一步会带来巨大风险。
人机协作的概念,在文献中也被称为人机协同,最初是由利克利德在 1960 年提出的,但是前国际象棋世界冠军加里-卡斯帕罗夫(Garry Kasparov)在 1997 年被 IBM 的 “深蓝 ”击败后,提出了 “半人马国际象棋”(Centaur Chess)的概念--即人类在对弈过程中与计算机协作。尽管输给了人工智能,但卡斯帕罗夫倡导的理念是,不要将人工智能视为一种威胁,而应将其视为一种工具,在与人类能力相结合的情况下,可以取得非凡的成就。
在他的著作《深度思考》(Deep Thinking: 机器智能的终点和人类创造力的起点》[48]一书中,卡斯帕罗夫强调了利用人类和机器不同优势的重要性。他指出,计算机擅长暴力计算,每秒能分析数百万个局面,并计算出最佳的短期战术棋步,而人类则主要通过直觉,带来更深层次的战略理解、创造力和辨别棋步长期后果的能力[48]。卡斯帕罗夫认为,人类直觉与机器计算的结合往往会产生比顶尖特级大师或计算机单独发挥更强的棋艺。他观察到,在许多情况下,即使是计算机辅助下的低级棋手也能超越顶级特级大师。
卡斯帕罗夫还讨论了人类在这种 “半人马 ”伙伴关系中的角色是如何随着国际象棋人工智能的改进而演变的。最初,人类专注于战略,而计算机负责战术。然而,随着国际象棋人工智能的进步,人类越来越多地承担起 “质量控制 ”的角色,确保计算机建议的棋步符合更广泛的战略目标。他推测,国际象棋的未来可能并不取决于人类与机器的对决,而是取决于使用何种界面的人机团队能发挥出最佳水平。这种合作将机器的计算能力与人类提供上下文、理解和直觉的能力结合在一起,使双方的水平都超过了各自的能力。
最后,开发智能体是充分利用人工智能进行兵棋推演的基础,无论是作为对手部队、智能队友、战术顾问、COA 生成器、COA 分析器、COA 利用器、未来部队设计、战斗裁决、场景规划,还是仅仅为了深入了解潜在结果。虽然脚本化智能体迄今为止已被证明是有用的,并将继续有用,但现代战争的复杂性和不可预测性需要新水平的适应性和学习能力,而这只有 ML 才能提供。通过将超级智能体融入战斗模拟,相信兵棋推演最终可以从静态和可预测发展到动态和有洞察力,从而反映真实世界行动的不确定性。
章节
- 第 2 章
本章介绍了开发智能体的基本背景概念,如搜索方法、博弈论、脚本代理、强化学习和分层强化学习。这些核心要素对于全面理解后续章节的研究至关重要。
- 第 3 章
在本章中,重点是介绍和验证一种新颖的方法,通过采用片断线性空间衰减的局部观测抽象,克服 RL 智能体在较大场景中面临的状态空间挑战。本章的核心内容已被第 16 届国际 MODSIM 世界大会接受发表。所介绍的方法通过将智能体的观测结果抽象为更紧凑、更易于计算管理的形式,简化了智能体的感知状态空间,同时保留了关键的空间信息。该研究通过一系列实验证明,在不同的场景复杂度下,具有片断线性空间衰减的局部观测抽象始终优于传统的全局观测方法。这表明,这些类型的观测简化可以为在复杂环境中扩展 RL 提供计算成本更低的卓越解决方案,而这一直是该领域的重大挑战。这些发现有助于推进 RL 观察抽象的研究,并说明此类技术有潜力促进 RL 在复杂真实世界环境中的更广泛应用,特别是在军事模拟和兵棋推演领域。
- 第 4 章
本章介绍并验证了多模型框架,该框架利用脚本模型和强化学习(RL)模型的组合,根据游戏的当前状态动态采用最佳模型来提高性能。本章的核心内容已接受在 2024 年 SPIE 国防与商业传感会议上发表。
这种多模型框架显著提高了性能,最全面的多模型(即包含最多单个行为模型的多模型)优于所有单个模型和较简单的复合模型。这表明,即使是表现较差的单个模型也能在特定情况下做出积极贡献,突出了模型库中多样性和专业化的价值。研究结果强调了多模型系统在增强军事模拟等典型的复杂、动态环境中的决策能力方面的潜力,提倡战略性地融合人工智能模型和技术,以克服训练单一通用模型所固有的挑战。
- 第五章
本章介绍并验证了一种混合分层人工智能框架,该框架将 RL 代理与脚本代理整合在一起,以优化大型作战模拟场景中的决策。传统的脚本代理虽然具有可预测性和一致性,但由于其僵化性,在动态场景中往往会失败。与此相反,RL 智能体虽然在大型模拟环境和不透明的决策制定过程中举步维艰,但却能提供适应性和从互动中学习的能力。
开发了一种新颖的方法,在这种方法中,分层结构采用脚本智能体进行常规、战术级决策,采用 RL 智能体进行战略、更高级决策。脚本模型的一致性和 RL 模型的适应性之间的协同作用大大提高了性能,在利用这两种方法的优势的同时似乎也减轻了它们的弱点。这种整合产生了一个更有效的人工智能系统,它可以应对军事模拟中更广泛的战略和战术挑战。
- 第 6 章
本章是论文工作的顶点部分,概述了设计、开发以及将整个论文中讨论的方法整合到新型 HRL 架构和训练框架中的过程。通过将不同层次的观测抽象和多模型方法整合到所提出的框架中,探索了这一 HRL 方法在复杂决策环境建模中的潜在优势和局限性。通过评估这些技术对学习过程和决策效率的影响,与传统的脚本和RL方法相比,旨在进一步了解构建和训练HRL系统的动态和挑战。
- 第七章
最后一章介绍了论文的核心研究成果。讨论了研究的理论和实践意义,强调了研究的优势和局限性,概述了对人工智能和作战 M&S 领域的贡献,并回答了本章提出的研究问题。此外,还利用整个 HRL 实验的结果来激励和明确未来的工作。
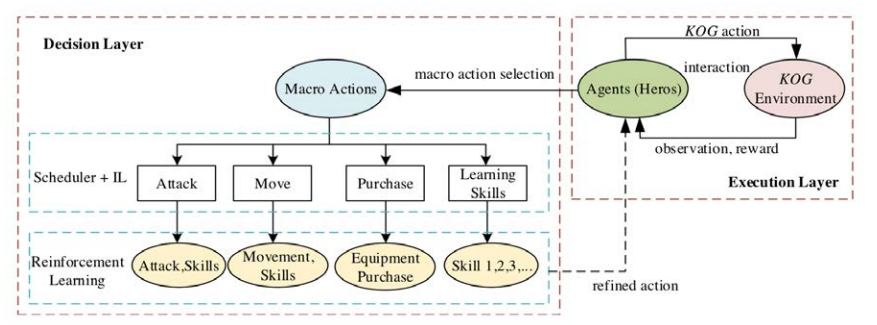
图 6.12. MOBA 智能体分层架构。分层架构由宏观战略和微观操作组成。



