
美国海军部长以审慎的方式分布海军兵力,以支持美国防部(DoD)的指导、政策和预算。目前的战略、部署和分布(SLD)过程是劳动密集型的,时间密集型的,而且在考虑竞争性的替代计划方面的敏捷性较差。SLD可以从人工智能的实施中受益。本文引入了一种相对较新的方法来解决这些问题,该方法最近来自于海军研究办公室资助的一个早期项目,该项目结合了机器学习、优化和兵棋推演的深度分析。这种方法被称为LAILOW,它包含了利用人工智能学习、优化和兵棋推演(LAILOW)。在本文中,我们开发了一套独立的伪数据,模仿了实际的、分类的数据,这样就可以安全地进行实验性游览。我们展示了LAILOW为每一艘可能被移动的可用船只产生了一个类似于兵棋推演场景的分数。每艘船的分值都会增加,因为需要较少的资源(如较低的成本)来满足SLD计划的要求,将该船转移到一个新的母港。这就产生了一个数学模型,能够立即比较可能被选择的竞争性或替代性船舶移动方案。我们设想一个更加综合、一致和大规模的深度分析工作,利用与现有真实数据源相联系的方法,更容易地对通过SLD过程考虑的平台移动的潜在方案进行直接比较。由此产生的产品可以促进决策者学习、记录和跟踪每个SLD过程中复杂决策的原因,并确定部队发展和部队组建的潜在改进和效率。
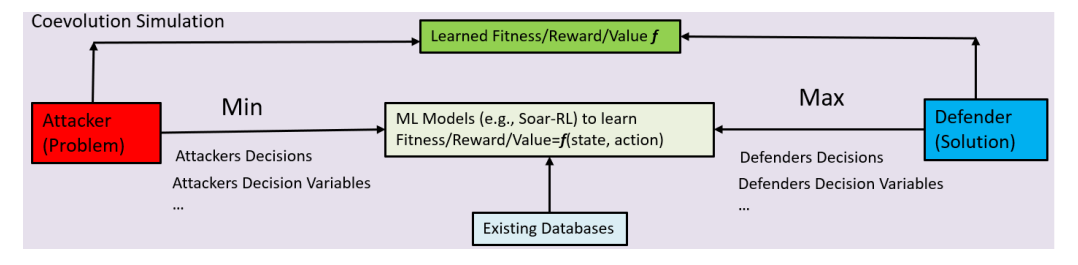
图1. 在共同进化兵棋推演模拟中查看LAILOW;ML算法(即SoarRL)被用来模拟双方的玩家或效用函数。
方法
本文详细介绍了与研究问题和规定阶段有关的方法。我们应用一个数学模型(即Leverage AI to Learn, Optimize, and Wargame[LAILOW]模型)来解决研究的深度分析问题。LAILOW源于ONR资助的一个项目,该项目专注于机器学习、优化和兵棋推演的深度分析,本质上是Leveraging AI,由以下步骤组成:
学习: D数据、数据挖掘、机器学习和预测算法被用来从历史数据中学习关于什么和如何做出决定的模式。来自竞争需求的数据是指来自舰队指挥官、国家领导人的游览建议和要求,以及在不同安装地点的各个功能区所做的评估数据。目前的人工程序主要是平衡单位搬家费用的预算和已知的需求。搬家费用是根据人力和基础设施准备情况的永久换站(PCS)订单制定的。这些数据以结构化数据库和非结构化数据的形式存在,如PowerPoint幻灯片和.pdf文件。
优化: 来自学习的模式被表示为Soar强化学习(SoarRL)规则或AGI转化器模型,用于优化未来的SLD计划。一个SLD计划包括每个设施、母港、基地、枢纽和岸上态势位置(Fd)和人员(Fg)的海军资产的完整增益或损失。考虑到众多的组合,这种优化可能是令人难以承受的。相反,LAILOW使用集成的Soar-RL和协同进化算法,将总的SLD计划映射到远航建议、评估报告和其他假设分析中提到的各个单位。
兵棋推演:可能没有或很少有关于新的作战要求和能力的数据。这就促使了兵棋推演的模拟。一个SLD计划可以包括状态变量或问题(例如,未来的全球和战区态势、威胁特征),这些问题只能被观察、感知,并且不能被改变。控制变量是解决方案(例如,一个SLD计划)。LAILOW在状态和控制变量之间设置了一个兵棋推演。问题和解决方案根据选择、变异和交叉的进化原则共同演化。
如图1所示,LAILOW框架可以被设定为一个由自我玩家和对手进行的多段兵棋推演。自我游戏者或防御者是SLD企业。对手或攻击者是包括竞争性需求的环境。在应用LAILOW时,我们首先将过程分为状态变量和决策变量,如下所示:
状态变量: 这些变量和数据可以被感知、观察和估计,但是,不能由自我角色决定或改变。它们是输入变量,或自我游戏者必须考虑的问题。它们也被称为SLD企业的测试或攻击。
决策变量: 这些变量是使用优化算法来解决问题所需要的。在LAILOW中,决策变量的优化是通过整合Soar-RL和协同进化搜索和优化算法来实现的(Back, 1996; O'Reilly等人, 2020)。
对手(测试)和自己的玩家(解决方案)都像兵棋推演中一样演化和竞争。LAILOW就像一个蒙特卡洛模拟,但由ML/AI学习的模式与优化算法指导。在兵棋推演中,对手产生大规模的假设测试,以挑战自我玩家提出更好的解决方案,例如,SLD配置,以回答诸如 "如果我选择一个不同的决定会发生什么?"的系统模拟问题。
每个 "学习、优化、兵棋推演"周期在每个阶段和所有价值领域动态地迭代,其分析组件和算法详见下文。
在LAILOW框架中,"学习 "部分通常采用有监督的ML算法,如分类、回归和预测算法。例如,人们可以应用scikit-learn python中的各种最先进的监督ML算法,如逻辑回归、决策树、天真贝叶斯、随机森林、k-近邻和神经网络。深度学习或AGI Transformers也可以放在这个类别中,输入数据是多样化的。一个AGI框架通常包含大规模的机器学习模型(例如,ChatGPT模型中的数十亿个参数;OpenAI,2023),以从多模态数据中学习和识别模式。
监督的ML算法可用于学习潜在的SLD和偏离计划的功能区的状态变量和评估措施,如部署和执行的速度、质量和适用性,竞争性需求和约束的平衡(例如,避免不可接受的能力下降),以及Fd和Fg措施。
在LAILOW中,我们使用Soar-RL来分别学习自玩家和对手的两个健身函数。在强化学习中,代理人根据其当前状态和它从内部模型中估计的期望值,采取一个行动并产生一个新的状态(Sutton & Barto, 2014)。它还通过修改其内部模型从环境的奖励数据中学习。Soar-RL可以将基于规则的人工智能系统与许多其他能力,包括短期和长期记忆,进行可扩展的整合(Laird,2012)。Soar-RL在军事应用中具有以下优势,因为它
- 可以包括现有的知识(例如,SLD的交战规则),也可以从数据中修改和发现新规则
- 以在线、实时、渐进的方式学习,因此不需要批量处理(潜在的大)数据
- 提供可解释的人工智能的优势,因为发现的模式被表示为规则
- 与因果学习相联系,因为它符合因果学习的支柱(例如,关联、干预和反事实;Pearl & Mackenzie,2018),通过使用干预产生预期效果数据(Wager & Athey,2018)。
"学习 "组件也可以应用无监督的学习算法。自玩家执行无监督的机器学习算法,如k-means、原理成分分析(PCA)和词汇链接分析(LLA; Zhao & Stevens, 2020; Zhao et al., 2016)来发现链接。
一个SLD过程需要进行what-if分析,因为这促使了兵棋推演的模拟。一个SLD计划可以包括状态变量或问题(例如,未来的全球和战区态势、威胁特征、处理这些威胁的舰队需求),这些问题只能被观察、感知,不能被改变。控制变量是解决方案(例如,一个SLD计划)。LAILOW在状态和控制变量之间设置了一个兵棋推演。问题和解决方案根据选择、变异和交叉的进化原则共同演化。
SLD计划和偏移模型的状态和决策变量的数量可能非常大。协同进化算法可以模拟未来作战要求、威胁和全球环境及未来能力的动态配置,以及兵棋推演模拟中的其他竞争因素。如图1所示,竞争性协同进化算法用于解决生成对抗网络(GANs;Goodfellow等人,2014;Arora等人,2017)所遇到的minmax-问题。玩家的对抗性交战可以通过计算建模来实现。竞争性协同进化算法采取基于种群的方法来迭代对抗性交战,可以探索不同的行为空间。用例测试(对抗性攻击者群体)是主动或被动地阻挠问题解决方案(防御者)的有效性。协同进化算法被用来识别成功的、新颖的以及最有效的解决手段(防御者)来对抗各种测试(攻击)。在这种竞争性游戏中,测试(攻击者)和解决方案(防御者)的策略会导致对手之间的军备竞赛,双方在追求冲突的目标时都在适应或进化。
一个基本的协同进化算法用锦标赛选择和用于变异的方法(如交叉和变异)来进化两个种群。一个种群包括测试(攻击)和另一个解决方案(防御)。在每一代中,通过配对攻击和防御形成交战。这些种群以交替的步骤进行进化: 首先,测试种群被选择、改变、更新并针对解决方案进行评估,然后解决方案的种群被选择、改变、更新并针对测试进行评估。每个测试--解决方案对都被派往参与组件,其结果被用作每个组件的适配度的一部分。适应性是根据对手的交战情况整体计算的。
每个SLD配置都有一个健身值,它与需要优化的措施有关,如部队发展(Fd)和部队生成(Fg)效率。来自 "学习 "的模式被用来优化未来的SLD计划,其措施如下:
- SLD的成本:对于一艘船来说,从一个地方移动到另一个地方
- 移动人员的成本是多少: 每个人的PCS成本 x 坯料的数量?
- 准备必要的基础设施(匹配的评估)以支持船舶移动的成本是多少?
- Fd/Fg效率: 有多少游览或需求得到满足(匹配)?
优化可能是压倒性的。LAILOW使用综合Soar-RL和协同进化算法,简化了优化过程。
LAILOW已被用于DMO和EABO的兵棋推演(Zhao, 2021),发现海军舰艇和海军陆战队的维修和供应链的物流操作的脆弱性和弹性(Zhao & Mata, 2020),以及超视距打击任务规划(Zhao等,2020;Zhao & Nagy, 2020)。




