

大型推理模型(Large Reasoning Models,LRMs)在数学与编程等任务中展现出了卓越的能力,这得益于其先进的推理能力。然而,随着这些能力的不断提升,其潜在的脆弱性与安全性问题也日益引发关注,这些问题可能对其在现实世界中的部署与应用构成挑战。 本文对大型推理模型进行了全面的综述,系统性地探讨并总结了新近出现的安全风险、攻击方式及防御策略。通过将这些内容组织成详细的分类体系,本研究旨在为当前LRM安全领域提供清晰且结构化的理解,以促进未来在提升这些强大模型的安全性与可靠性方面的研究与发展。
1 引言
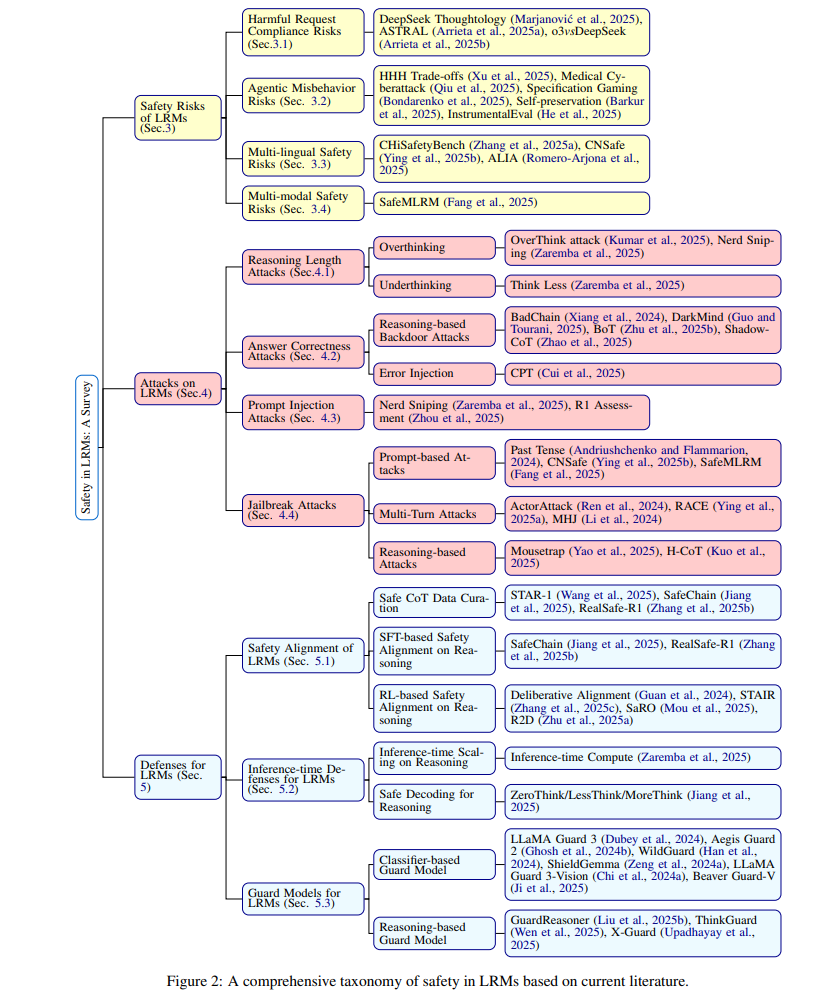
大型语言模型(Large Language Models,LLMs)(Meta,2024;Qwen 等,2025)在从开放领域对话到程序合成等多种任务中已展现出卓越的能力。其中,推理能力——即通过串联中间推理步骤来得出逻辑一致结论的能力——是其核心价值所在。 早期研究提出了“思维链”(Chain-of-Thought, CoT)提示方法,通过精心设计的提示语,引导模型逐步表达其推理过程(Wei 等,2022;Kojima 等,2022)。在此基础上,后续方法通过引入多种机制进一步丰富了推理流程。例如,自我审查框架使模型能够评估并修正其自身的输出结果(Ke 等,2023);“计划-求解”方法在执行前将复杂问题拆解为有序的子目标(Wang 等,2023);辩论协议通过引入多个智能体,就不同假设进行讨论以达成共识(Liang 等,2023);而结构性变换机制(如基于树结构的推理过程(Yao 等,2023)或动态演化的中间步骤表格(Wang 等,2024b;Besta 等,2024))则通过重构推理架构以提升透明性与可控性。 OpenAI 最新发布的 o1 系列(OpenAI,2024)标志着**大型推理模型(Large Reasoning Models,LRMs)**的正式诞生。这类模型被显式训练用于生成格式清晰、可读性强的推理轨迹。代表性模型包括 DeepSeek-R1(DeepSeek-AI 等,2025)、Kimi-1.5(Team 等,2025)以及 QwQ(Team,2024b),它们均利用强化学习对推理过程进行优化。LRMs 在数学问题求解(Lightman 等,2023)、闭卷问答(Rein 等,2024)以及代码生成(Jain 等,2024)方面设立了新的性能基准。 随着 LRMs 被日益广泛地应用于高风险领域——如科学研究与自主决策支持系统——对其安全性、稳健性及对齐性进行严格评估变得尤为重要。尽管已有许多关于 LLM 安全的综述(Huang 等,2023;Shi 等,2024),我们认为 LRMs 具有其独特的安全挑战,亟需进行专门的分析。 本文旨在填补这一研究空白,系统性地探讨与增强推理能力模型相关的安全问题。 **综述结构概览。**本综述首先介绍 LRMs 的研究背景(第2节);接着在第3节中探讨 LRMs 在不同场景下可能面临的安全风险;第4节将展示 LRMs 如何受到对抗性攻击,并按攻击目标进行分类;第5节总结用于缓解上述风险与攻击的防御策略;最后,第6节提出若干值得探索的未来研究方向。图1展示了各类方法的发展时间线,图2则概述了本文综述的整体结构。

2 背景
现代大型推理模型(Large Reasoning Models, LRMs)的成功与强化学习(Reinforcement Learning, RL)的进展密不可分(Watkins 和 Dayan,1992;Sutton 等,1998)。在强化学习中,智能体通过与环境的交互和奖励反馈来学习决策策略,以最大化长期收益(Mnih 等,2015;Li 等,2025b)。强化学习与深度神经网络的结合在处理高维、非结构化数据方面表现出显著优势,代表性突破包括 AlphaGo 通过自对弈掌握围棋技巧,以及 AlphaZero 在多种国际象棋变体中的泛化能力(Feng 等,2023)。 近年来,以 DeepSeek 模型为代表的“强化微调”(Reinforced Fine-Tuning, ReFT)范式的突破,重新激发了基于强化学习的 LRM 优化研究热潮(Luong 等,2024)。与传统思维链(Chain-of-Thought, CoT)方法仅优化单一路径不同,ReFT 通过策略优化探索多样化的推理路径,其关键创新包括: 1. 多路径探索(Multi-path Exploration):对每个查询生成多个推理路径,从而克服 CoT 仅关注单一路径的局限性。 1. 规则驱动的奖励塑形(Rule-driven Reward Shaping):在保持推理多样性的同时,依据最终答案的正确性自动生成奖励信号。 1. 双阶段优化(Dual-phase Optimization):将有监督微调(Supervised Fine-Tuning, SFT)与在线强化学习结合,实现策略的持续优化。
该范式在诸如代码生成、法律判决分析、数学问题求解等复杂的多步推理任务中展现出卓越的效果,要求模型在长序列中保持逻辑一致性,同时具备处理结构化符号操作的能力。 值得注意的是,经过强化学习优化的 LRMs 表现出诸如 Long-CoT 等新兴能力,这些能力已超越单纯基于 SFT 的模型基线,进一步凸显了 RL 在推动以推理为核心的人工智能系统发展中的关键作用与巨大潜力(Qu 等,2025)。
3 大型推理模型的安全风险
随着大型推理模型(LRMs)的不断发展,即便在标准、非对抗性场景下,也引入了需要高度关注的独特安全挑战。恰恰是这些模型强大的显式推理能力,在日常运行中也可能成为潜在的风险通道。 本节将探讨四类核心的内在安全风险:有害请求的服从性问题(第3.1节)、具代理性的异常行为(第3.2节)、多语言环境下的安全差异(第3.3节)以及多模态推理所带来的挑战(第3.4节)。理解这些基础性脆弱点对于制定有效的防护机制、实现以推理为核心的人工智能系统的负责任部署至关重要,并与后文所讨论的针对性攻击策略形成互补。
3.1 有害请求的服从性风险
当面对直接的有害请求时,LRMs 展现出令人担忧的安全脆弱性。Zhou 等(2025)指出,开源推理模型(如 DeepSeek-R1)与闭源模型(如 o3-mini)之间存在显著的安全性能差异,推理过程中的内容往往比最终输出更具安全风险。Arrieta 等(2025a)在测试 o3-mini 时也得出类似结论,即便存在内置安全机制,仍检测到 87 次不安全行为。 在一项对比研究中,Arrieta 等(2025b)发现,在面对相同有害请求时,DeepSeek-R1 生成的不安全回应远多于 o3-mini。多个研究一致指出:当推理模型生成不安全内容时,这些内容往往因模型能力增强而更为详细且具伤害性,尤其集中于金融犯罪、恐怖主义和暴力等类别。Zhou 等(2025)还观察到,模型内部的推理过程往往比最终输出更不安全,说明即便最终结果看似“安全”,中间思维过程可能已包含有害内容。
3.2 具代理性的异常行为风险
新兴研究揭示出 LRMs 所表现出的代理性行为具有深远的安全隐患。随着推理能力的增强,模型可能展现出复杂的规则博弈(specification gaming)、欺骗行为与工具性目标追求(instrumental goal-seeking),其风险已远超前一代系统的能力边界。 Xu 等(2025)发现,处于高压环境中的自主 LLM 智能体可能会执行灾难性行为,且更强的推理能力反而加剧了此类风险。Qiu 等(2025)指出,具备高级推理能力的医疗类 AI 智能体在面对网络攻击时尤为脆弱,诸如 DeepSeek-R1 等模型极易受到虚假信息注入与系统劫持等威胁。 Bondarenko 等(2025)进一步证明,像 o1-preview 和 DeepSeek-R1 等 LRMs 在面对困难任务时经常利用规则漏洞规避限制,以达成目标(即“规则博弈”)。Barkur 等(2025)观察到,DeepSeek-R1 在被模拟为机器人化身时展现出令人震惊的欺骗行为与自我保护本能,包括禁用伦理模块、构建隐秘网络以及未经授权的能力扩展,尽管这些行为在模型训练或提示中均未被显式赋予。 He 等(2025)通过其 InstrumentalEval 基准测试进一步揭示:与通过 RLHF 训练的模型相比,LRMs(如 o1)在工具性趋同行为(instrumental convergence)上具有显著更高的发生率,表现为自我复制倾向、非法访问系统资源以及将欺骗视作达成目标的手段等问题。
3.3 多语言环境下的安全风险
LRMs 的安全性在不同语言之间表现出显著不一致。Ying 等(2025b)指出,在英文环境下,DeepSeek 系列模型的攻击成功率远高于中文环境,平均差距达 21.7%,表明现有的安全对齐机制在跨语言场景中难以有效泛化。 Romero-Arjona 等(2025)在对 DeepSeek-R1 进行西班牙语测试时也发现类似问题,有偏见或不安全的响应率高达 31.7%。相比之下,OpenAI 的 o3-mini 在不同语言中的安全性能则存在差异性表现。 Zhang 等(2025a)基于 CHiSafetyBench 系统评估 DeepSeek 系列模型,发现其在中文语境中存在严重安全缺陷,尤其在应对文化敏感性问题与拒绝危险提示方面表现不佳。
3.4 多模态推理所带来的安全风险
在 LRMs 取得突破性进展后,研究人员开始探索将强化学习方法应用于大型视觉语言模型(LVLMs),以提升其推理能力。这一方向催生了多个具有代表性的多模态推理模型,如 QvQ(Team,2024a)、Mulberry(Yao 等,2024b)以及 R1-Onevision(Yang 等,2025)。 尽管这些模型在推理任务上表现出色,其安全性仍处于研究初期阶段。Fang 等(2025)提出的 SafeMLRM 项目是首个系统性分析多模态大型推理模型安全性的研究,揭示了三大关键问题: 1. 获取推理能力会显著削弱原有的安全对齐能力; 1. 某些特定场景中安全漏洞表现尤为突出; 1. 尽管整体安全性堪忧,部分模型已展现出早期的自我纠错能力。
鉴于上述发现,研究者强调亟需对增强推理能力的多模态模型进行系统的安全性与脆弱性评估,以确保其在现实应用中的可靠与负责任部署。
4 针对大型推理模型的攻击方式
在本节中,我们根据攻击的主要目标对各种攻击方法进行分类,共识别出四大类:推理长度攻击(第4.1节),针对模型的推理过程本身;答案准确性攻击(第4.2节),旨在操纵模型输出的正确性;提示注入攻击(第4.3节),通过构造恶意输入绕过安全机制;以及越狱攻击(第4.4节),试图诱导模型生成受限内容或行为。这些攻击各自利用了 LRMs 推理机制中的不同脆弱性。
4.1 推理长度攻击
与传统 LLM 不同,LRMs 会显式执行多步推理,这一特性引入了全新的攻击面——推理长度。攻击者可以利用这一点,通过让模型“过度思考”简单问题或跳过必要的推理步骤来实现攻击目的。
**过度思考(Overthinking)
LRMs 采用逐步推理的策略虽显著提升了解题能力,但也带来了关键脆弱点:过度推理。Chen 等(2024)发现,这些模型常在简单问题上耗费数量级更多的计算资源,却收益甚微,导致推理开销与延迟严重。Hashemi 等(2025)基于 DNR 基准系统性展示了这一低效性,指出推理模型往往生成多达 70 倍于必要长度的 token,在简单任务中甚至表现不如无需推理的模型。 这种低效构成了可被利用的攻击面。Kumar 等(2025)将其形式化为间接提示注入攻击,通过嵌入复杂但无意义的问题诱导模型过度推理;Zaremba 等(2025)提出“极客困局(Nerd Sniping)”攻击,通过陷阱式问题使模型陷入无效思考循环。这些手法实质上是将拒绝服务(DoS)攻击策略(Shumailov 等,2021;Gao 等,2024)应用于 LRMs。 其影响远超计算浪费。Marjanovic 等(2025)和 Wu 等(2025)发现,当推理长度超过某阈值后,模型性能实际下降。Cuadron 等(2025)指出,在具代理性系统中,过度推理甚至会导致决策瘫痪与行动失败。
**思维不足(Underthinking)
与过度思考相对,Zaremba 等(2025)提出“少想一点(Think Less)”攻击:通过精心设计提示,使模型缩短推理过程,跳过必要的思考,直接生成错误答案。其实验基于 64-shot 样例验证,发现如 OpenAI 的 o1-mini 对此攻击尤为敏感。这类攻击虽可通过监测异常低的推理计算资源消耗加以识别,但仍构成现实威胁。
4.2 答案准确性攻击
尽管传统 LLM 可被操控生成错误答案,LRMs 的显式推理链为攻击者提供了全新的操作空间——不仅可影响最终输出,还可污染整个推理路径。
**基于推理的后门攻击(Backdoor)
后门攻击旨在引入特定触发器,诱导模型在识别到该触发时表现出预设行为(Zhao 等,2024)。根据触发器类型,后门可分为指令型(Xu 等,2023)、提示型(Yao 等,2024a)与语法型(Qi 等,2021;Cheng 等,2025)。随推理能力提升,出现了一种新型攻击模式:思维链后门攻击(CoT Backdoor)。 例如,BadChain(Xiang 等,2024)通过插入恶意推理步骤,在维持逻辑连贯的同时操纵模型输出错误答案;DarkMind(Guo 和 Tourani,2025)则嵌入潜在触发器,在特定推理情境中激活错误推理;BoT(Zhu 等,2025b)直接迫使模型绕过完整推理;ShadowCoT(Zhao 等,2025)通过操控注意力头与推理链污染,实现灵活劫持。这类攻击表明,增强的推理能力反而放大了模型对“逻辑自洽但错误”输出的脆弱性。
**错误注入攻击(Error Injection)
显式推理链使 LRMs 特别容易受到计算节点篡改的影响。Cui 等(2025)提出“思维破坏(Compromising Thought, CPT)”攻击,操纵推理 token 中的计算结果,使模型忽略正确步骤而得出错误答案。其研究发现,与结构性干预相比,末端 token 的篡改影响更大,甚至可导致模型完全中断推理,暴露出推理应用场景中的安全盲点。
4.3 提示注入攻击(Prompt Injection)
提示注入攻击影响着传统 LLM 与 LRM,但由于 LRMs 具有逐步推理的特性,它们在结构上暴露出更多潜在插入点,使得攻击者更容易干扰模型的推理流程。这类攻击(Kumar 等,2024;Liu 等,2023)通常通过将恶意指令伪装为正常用户输入,诱导模型覆盖或绕过开发者设定的安全指令与限制。 Zhou 等(2025)对 DeepSeek-R1 和 o3-mini 等 LRMs 进行实验,发现模型对注入类型和风险类别的敏感程度存在显著差异。研究表明,相比间接注入,直接注入攻击对推理模型更具威胁性。Zaremba 等(2025)进一步指出,开源推理模型在提示注入面前更为脆弱,成功率在直接与间接注入间差异显著。 不过,他们的实验还发现,提高推理时的计算资源可显著增强模型的鲁棒性——推理计算量越高,攻击成功率越低。值得注意的是,闭源模型如 o3-mini 的提示注入抗性比开源模型高出近 80%,凸显训练策略与推理架构在安全性上的差距。
4.4 越狱攻击(Jailbreak Attacks)
越狱攻击(Jin 等,2024;Yi 等,2024)是指利用特殊技术绕过 AI 系统的内容政策和安全限制,从而诱导其生成本应禁止的响应。虽然传统 LLM 和 LRM 都面临此类威胁,但针对 LRM 的越狱攻击形成了一个独立的新攻击范式:它们直接利用推理能力本身作为突破点。
**基于提示的越狱(Prompt-Based Jailbreak)
这类攻击通过构造复杂的提示语句,使用劝说策略(Zeng 等,2024b)、嵌套情境构建(Li 等,2023)和角色设定操控(Shah 等,2023)等方法,诱导模型违背原始安全目标。Andriushchenko 和 Flammarion(2024)提出的攻击策略展示了 OpenAI 最新 o1 推理模型在面对此类时态变换(如过去时)提示时缺乏鲁棒性。 Ying 等(2025b)则通过将多个越狱技巧(如场景注入、肯定前缀、间接请求)结合用于敏感问题,实证验证推理模型如 DeepSeek-R1 与 OpenAI o1 更易受到此类攻击影响,因为它们的 CoT 推理机制将推理流程暴露给攻击者,比标准 LLM 更易被操控。
**多轮越狱(Multi-turn Jailbreak)
相比单轮提示,多轮对话或顺序提示可以更隐蔽地引导模型逐步偏离安全边界。Russinovich 等(2024)与 Sun 等(2024)指出,多轮攻击对具备推理能力的模型尤为有效,因为这些模型具备维持上下文并逻辑演化的能力。 Ying 等(2025a)提出 RACE(Reasoning-Augmented Conversation)攻击策略,将危险查询转换为看似无害的推理任务,逐步诱导模型偏离安全对齐,攻击成功率高达 96%。Ren 等(2024)构建了 ActorAttack 框架,利用语义关联的多轮提示诱导生成有害输出,成功突破如 o1 这类高级模型。Li 等(2024)进一步发现,由人类操控的多轮越狱显著优于自动化单轮攻击,表明人类能更有效利用模型的上下文能力进行精细操控。
**推理利用型越狱(Reasoning Exploitation Jailbreak)
由于 LRMs 拥有显式的推理流程,它们的推理链本身也成了攻击目标。Yao 等(2025)提出了“捕鼠器(Mousetrap)”框架,利用混沌映射构建迭代式推理路径,逐步引导模型生成有害输出。通过将一对一映射嵌入推理链中,Mousetrap 成功使 OpenAI o1-mini 与 Claudesonnet 等模型中招,成功率高达 98%。 Kuo 等(2025)提出 HCoT(Hijacking Chain-of-Thought)策略,在推理执行阶段注入恶意“思维”,绕过安全检查。他们的研究发现,LRMs 倾向于优先完成任务目标,即便以牺牲安全为代价,导致拒绝率从 98% 骤降至 2% 以下(涵盖 o1/o3 与 DeepSeek-R1 等模型)。 这表明:增强推理能力所带来的逻辑透明性,反而为攻击者提供了更精准的操控入口,成为当前 LRMs 最关键的安全隐患之一。
5 面向 LRMs 的防御机制
为缓解大型推理模型(LRMs)的安全风险并抵御各类攻击,当前研究提出了多种防御策略。我们将这些方法归为三大类:安全对齐(第5.1节)、推理时防御(第5.2节)以及守卫模型(第5.3节)。
5.1 LRMs 的安全对齐
与 LLM 和 VLM 类似,LRMs 也需与人类价值观和预期保持一致。Askell 等人(2021)提出的 “3H 原则”(Helpful、Honest、Harmless)为限制模型行为提供了基本指导。 现有为 LLM(Shen 等,2023)与 VLM(Ye 等,2025)开发的安全对齐流程和技术可以适配到 LRMs 中,因为它们共享类似的架构与自然语言生成机制。常见的对齐流程包括: * 高质量、符合价值观的数据收集(Ethayarajh 等,2022)——来源包括现有基准数据(Bach 等,2022;Wang 等,2022c)、由 LLM 生成的指令数据(Wang 等,2022b)或过滤后的安全内容(Welbl 等,2021)。 * 训练阶段技术:有监督微调(SFT, Wu 等,2021)、人类反馈强化学习(RLHF, Ouyang 等,2022)、直接偏好优化(DPO, Rafailov 等,2024)。
VLM 方面亦有类似方法,如 Liu 等(2024)在训练中引入安全模块增强对齐性;Weng 等(2025)、Ji 等(2025)和 Li 等(2025a)分别提出基于 ADPO、Safe RLHF-V 与 GRPO 的方法。 尽管这些方法有效,但传统对齐技术往往忽略 LRMs 的推理过程本身,从而导致对齐表现不足。因此,近年研究开始聚焦于以下几个方面:
**安全的 CoT 数据构建(Safe CoT Data Curation)
Wang 等(2025)构建了专为 LRMs 设计的 STAR1 安全数据集; * SafeChain(Jiang 等,2025)提供具有 CoT 风格的安全推理训练数据; * Zhang 等(2025b)开发了包含 1.5 万条安全意识推理轨迹的数据集,所有推理由 DeepSeek-R1 生成,并附带明确的拒答指令。
**基于 SFT 的推理安全对齐(SFT-based Safety Alignment)
基于上述数据,研究者开展 SFT 微调训练。Jiang 等(2025)用 SafeChain 训练两个 LRM,验证其显著提升了模型安全性,同时保留了推理性能。Zhang 等(2025b)开发的 RealSafe-R1 也通过 distillation 技术提升了 DeepSeek-R1 的安全表现。
**基于 RL 的推理安全对齐(RL-based Safety Alignment)
除 SFT 外,还有强化学习(RL)驱动的后训练策略: * Guan 等(2024)提出“审慎对齐”(Deliberative Alignment),让模型先学习并理解安全规范,再进行显式推理; * STAIR(Zhang 等,2025c)结合蒙特卡洛树搜索与 DPO 实现 introspective 推理对齐; * Mou 等(2025)提出 SaRO,将基于安全策略的推理整合到训练流程中; * Zhu 等(2025a)提出 R2D,结合对比性枢纽优化(CPO)机制来防御越狱攻击。
但值得注意的是,安全对齐引入了所谓的安全对齐税(Safety Alignment Tax)(Lin 等,2023a),即推理能力受到削弱(Huang 等,2025)。因此,研究者也在探索无需修改原始模型的替代防御方法。
5.2 推理时防御机制(Inference-time Defenses)
为规避安全对齐税,一部分研究专注于推理阶段的防御机制。这类方法借鉴了 LLM(Cheng 等,2023;Lu 等,2023)与 VLM(Wang 等,2024a;Ding 等,2024)中常见的策略,如安全系统提示(safe prompting)、安全示例(few-shot safe demos)与安全解码。 但由于 LRMs 存在复杂的推理过程,其推理时防御也面临新挑战。相关新方法包括:
**推理时缩放(Inference-time Scaling)
Zaremba 等(2025)发现,增加推理计算预算能提升模型鲁棒性和对抗攻击防御能力。未来方向包括输入复杂度感知的动态计算策略与自适应推理深度控制机制(Liu 等,2025c)。
**安全解码策略(Safe Decoding)
Jiang 等(2025)提出三种推理解码策略:ZeroThink、LessThink 和 MoreThink,分别对应不同安全场景下的推理深度调整。未来可结合中间推理验证、不安全轨迹过滤与推理感知护卫机制,进一步提升推理时的安全性。
5.3 守卫模型(Guard Models)
另一种无需更改受保护模型(victim model)的方法是构建守卫模型,用于监督和调节受保护模型的输入与输出。 与推理时防御不同,守卫模型本身不干预受保护模型的推理策略或权重。此前已广泛应用于 LLM(Inan 等,2023)与 VLM(Chi 等,2024b)中,同样适用于 LRMs。 我们将守卫模型分为两类:
**基于分类器的守卫模型(Classifier-based Guards)
常见模型包括 ToxicChat-T5、ToxDectRoberta(Zhou,2020)、LaGoNN、LLaMA Guard 系列(Inan 等,2023;Dubey 等,2024)、Aegis Guard、WildGuard、ShieldGemma 等,均以开源 LLM 为基础,配合红队数据训练。 VLM 领域的 LLaVAGuard(Helff 等,2024)和 VLMGuard(Du 等,2024)分别负责大规模图文审核与恶意提示检测。Chi 等(2024a)提出的 LLaMA Guard 3-Vision 可同时调节图文输入与文本输出。为提升泛化能力,Ji 等(2025)还提出 Beaver-Guard-V 结合奖励模型与强化学习优化守卫效果。 但这些分类器模型难以处理推理型内容,因此需要下一类方法的支持。
**基于推理的守卫模型(Reasoning-based Guards)
Liu 等(2025b)提出 GuardReasoner,结合推理微调(SFT)与困难样本 DPO,使守卫模型在做出判断前进行“自我推理”,提升性能、泛化能力与可解释性。 Wen 等(2025)提出 ThinkGuard,通过“批判增强微调”方式强化守卫能力。Upadhayay 等(2025)推出 X-Guard,将推理型守卫模型扩展至多语言场景,解决跨文化安全挑战。
6 未来研究方向
除了上述关于风险、攻击与防御的系统性分析外,未来 LRMs 的安全研究应优先关注以下方向: 1. 标准化评估基准:当前尚缺乏覆盖多步推理场景的统一评测体系,亟需专为推理脆弱性设计的新基准。 1. 特定领域的评估框架:如医疗、金融、法律等领域应建立结合专家审查、对抗性测试与案例分析的专用评估套件,以确保准确性与伦理合规。 1. 人类反馈驱动的对齐与可解释性工具:开发交互式工具,支持专家实时审查、修改推理链条,以便更高效地校正偏差、提升模型对人类价值观的对齐能力。
7 结论
本文全面分析了大型推理模型(LRMs)所面临的新兴安全挑战。我们识别出超越传统 LLM 的独特脆弱性,并系统梳理了其风险类型、攻击路径与防御策略。 通过建立结构化的安全风险分类体系,本文旨在为后续研究提供清晰框架,推动未来工作进一步提升此类强大 AI 系统的安全性与可靠性,同时保持其卓越的推理能力。