
题目:Provable Training for Graph Contrastive Learning 作者:于越,王啸,张梦玫,刘念,石川 单位:北京邮电大学,北京航空航天大学 前言:图对比学习的首要步骤是对图进行增广,而图的增广会带来结构的改变,因此存在着这么一个疑问:在不同的增广下,是否存在着某些节点由于结构特性使得它们在训练时总是表现地比较稳定,而有些节点由于结构特性使得在训练中总是表现地比较脆弱?本文中,我们根据上述特性改进了图对比学习,提出了图对比学习“可证训练”的方法,即根据节点的结构特性在训练中优化它们理论上的表现情况,从而对节点的训练过程提供了可证明的保障。
1. 背景介绍
图对比学习(Graph Contrastive Learning, GCL)是一种在图数据上进行对比学习的方法。其过程大致如下图所示。图经过数据增广,生成两个增广图,之后经过图神经网络(GNN)编码,得到节点表示(Embedding)。之后,两个增广中相同的节点为正样本对,不同的节点为负样本对,进行对比学习。
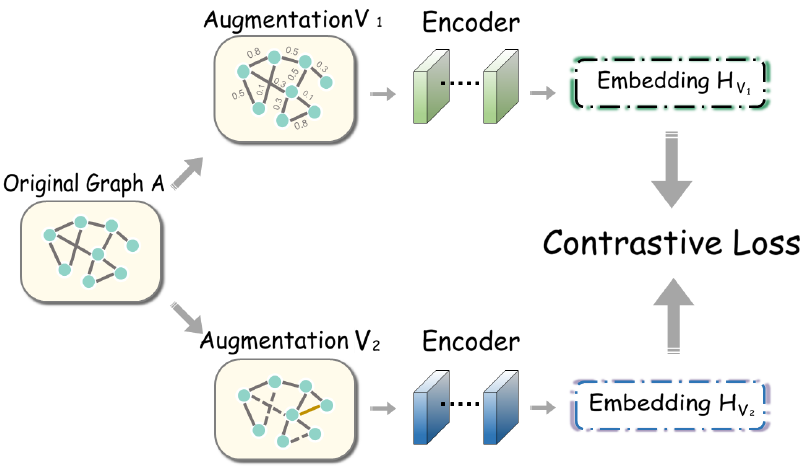
图对比学习大多遵循InfoMax准则,即最大化两个增广图之间的互信息,其损失函数InfoNCE形式为
2. 动机
上述训练过程中,首要的步骤是对图进行增广。在增广过程中,节点的拓扑结构会发生变化。但是,图中节点的结构特性各不相同。我们自然地会想到一个问题:不同的增广下,是否有些节点表现比较稳定,而有些节点很容易受到影响、比较脆弱? 这种节点的“结构特性”会影响到图对比的训练:那些稳定的节点可能是容易训练好并遵循GCL准则的,但是那些脆弱节点会是不容易训练好的,导致GCL准则被破坏。因此,我们不禁好奇,节点的训练情况是否真的存在上述问题?
我们可视化了不同GCL模型的节点训练情况的分布。下图为三种GCL方法的节点平均InfoNCE loss值的柱状图,横轴为InfoNCE loss的数值,纵轴为节点个数。可以看到,有很大部分的节点训练结果较远地偏离了平均情况,尤其是InfoNCE较大的节点,也就是训练相对较差的节点,因此我们是不愿看到这种情况的。
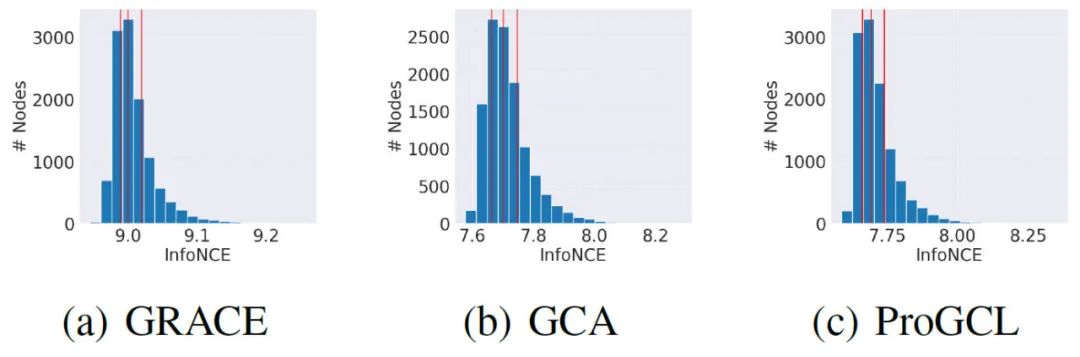
总结而言,GCL的训练不尽人意,训练结果并不均衡,尤其是难以训练的节点。也就是说,有大量节点并没有得到足够好的训练。我们所希望的是不同的节点都能够被更好、更加均衡地训练。 我们可以利用节点的“结构特性”去达到上述目标。也就是说,我们可以更加关注较为脆弱的节点,少关注那些稳定的节点。这样,节点的训练情况就会更加均衡,而且我们关注这种“结构特性”也会对GCL的训练有帮助、得到更好的训练结果。 然而,现有的InfoNCE loss并不能衡量这种特性:我们希望利用的“结构特性”是一种节点的 普适特性,可以面向不同增广的,这些增广的可能性是非常多且复杂的(与增广策略相关),而InfoNCE损失函数所作的事仅仅是计算某两个已有增广下节点的训练结果。
3. 节点的“结构特性”:节点紧致性
为了形式化定义节点的“结构特性”,我们提出了节点紧致性(node compactness)来衡量节点对于GCL训练的适应情况。这是一种来自于节点对GCL准则,也就是InfoMax的遵守程度的直接定义,具体形式为:

“节点紧致性”定义为节点的正样本相似度与负样本相似度之差的最小值。该最小值关注的范围是由增广策略所定义的所有可能增广(即和都看作该范围内的变量)。该值越大,说明节点的训练情况越遵守InfoMax准则。从“结构特性”的角度理解,节点的紧致性越大,那么所有增广的最差情况中,该节点依然表现较好,也就是节点较为稳定;反之节点较为脆弱。 为了减少变量数量,我们可以固定其中一个增广图,就得到了“节点紧致性”的简化版定义,-紧致性。-紧致性既是我们认为定义1中的(或)是某一采样得到的固定增广图。这样,我们就将形式进行了简化,便于实现和利用。定义1中所有与相关的变量成为定值,经过简化就得到了定义2的形式。下文的“节点紧致性”默认为“-紧致性”。

4. 图对比学习的可证训练(POT)
基于“节点紧致性”的定义,我们提出了图对比学习的“可证训练”。这里“可证”指的是,我们在训练中最大化“节点紧致性”这样一个最差情况的理论下界,也就是对节点训练中的稳定性的最差可能情况进行了可证明的优化保证。实现上,可以将节点的紧致性加入交叉熵损失函数中,令目标为“1”。我们提出的可证训练目标为:
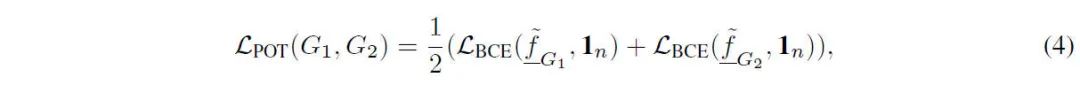
我们的可证训练可以作为一种插件,加入各种GCL方法中,与InfoNCE结合后,总体的对比学习损失函数为:
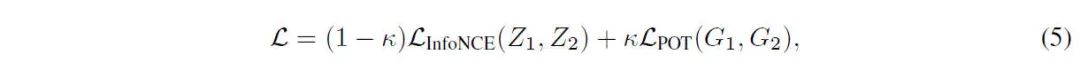
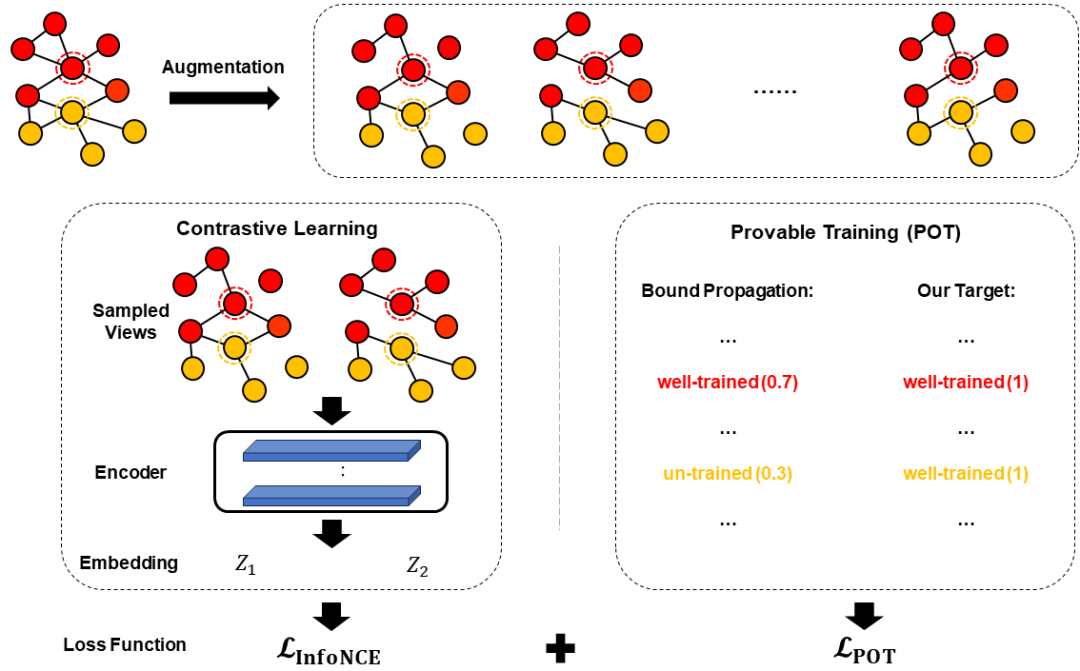
可证训练的整体框架如下。首先GCL的增广策略会对应某个增广的集合。左边是正常的GCL过程,可以看作首先从这个增广的集合中随机采样出一些增广图,之后进行对比学习得到InfoNCE损失;右侧是我们的“可证训练”,我们得到每个节点的紧致性之后利用二元交叉熵优化该值,保证了每个节点都能够根据其本身的“结构特性”去适应GCL训练并遵守GCL的准则。
5. 具体实现
但是,我们仅仅给出了节点紧致性的形式,其中的min并不能显式地直接使用,因为增广的范围是非常多的,为NP-hard问题。因此,我们想要把节点紧致性的形式简化,即由我们容易知道的一些量构成(输入的图,GNN的参数,以及增广策略的参数)。因此,一个很好的策略是通过上下界传播的方式求解。因为上下界传播做的事就是针对有界的输入,通过整个神经网络,推得输出的上下界。我们的问题中,“输入的上下界”就是增广策略所定义的,是已知的;而节点紧致性的min正对应了“输出的上下界”(z由GNN得到,W可以看作一个linear层,因此节点紧致性是GNN+线性层的输出下界)。应用上下界传播有两个挑战:输入的离散性(图结构),以及网络的非线性部分。这两个挑战都可能导致上下界传播的失败。但是,它们是可以通过一些近似算法解决的。
5.1 离散->连续
首先是将离散的输入上下界变换为连续输入的上下界。定义3是增广范围的形式化描述,其中我们限制了仅限删边、无向图、以及全局和每个节点局部的删边个数。很多增广策略都可以转化为这种形式的定义,例如GRACE的随机删减边,Q就是边的个数乘以删边概率,而q_i就是节点i的度乘以删边概率。
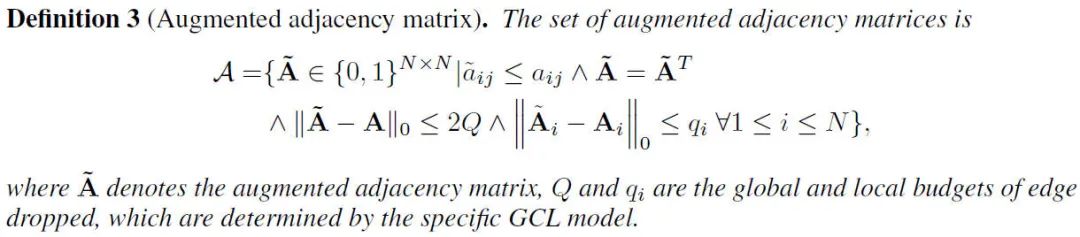
我们可以利用消息传递矩阵,也就是度归一化的邻接矩阵,来达到我们连续化的目的。因为消息传递矩阵的值可以取0-1之间的值,是连续的,而邻接矩阵的值只能取0或1。因此,我们将基于邻接矩阵的定义3转化为了定义4,定义5规定了消息传递矩阵每个元素的上下界。(我们限制删边是因为这是常见的做法,也可以不局限于删边,那么定义4会相应的改变)
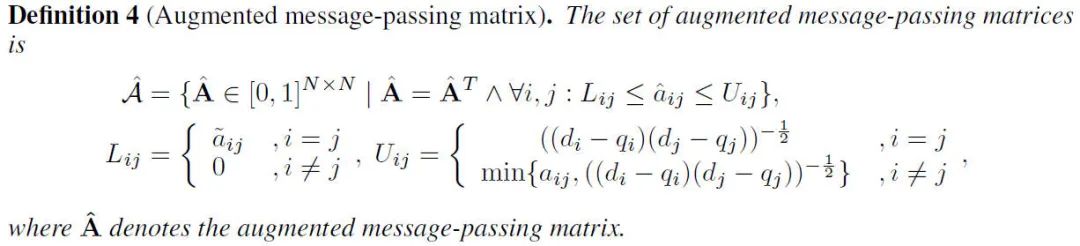
5.2 非线性激活->线性界
为了解决网络的非线性,也就是激活函数的问题,我们采用了定义5描述的线性上下界。因此,激活函数输出的上下界可以由激活函数输入的上下界的线性函数表示。α和β是线性上下界的参数,由的上下界计算得到。

之后,定理1给出了消息传递的上下界计算方式(也就是由上一层的embedding得到这一层激活函数前的上下界的方式)。

5.3 图对比学习可证训练的实现
有了上述的一些定义和定理,定理2给出了节点紧致性的计算的实现形式。通过上下界传播,我们成功化简了min,得到了可以通过一系列矩阵运算得到的形式,便于实现。

整体的算法流程如下。首先是通过GNN得到embedding,进而得到InfoNCE loss;之后我们根据定理2可以计算出节点紧致性,进而得到POT loss;把这两个loss加在一起,进行反向传播,就是POT+GCL的训练过程。

6. 实验
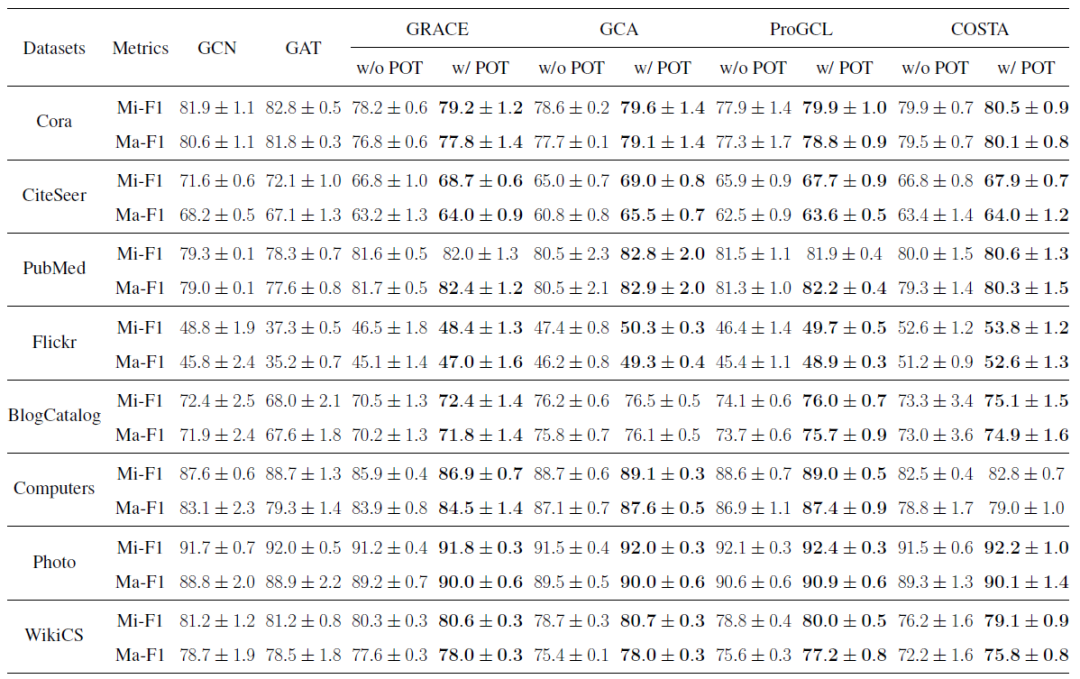
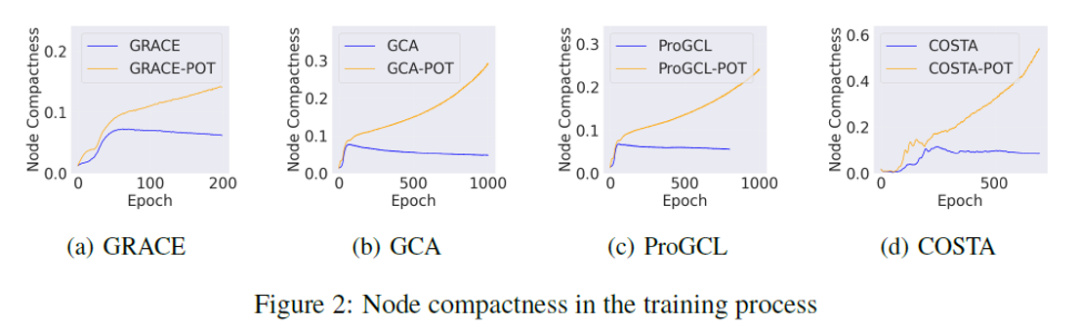
实验结果表明,我们的POT作为一种插件式增强,可以提升现有GCL的性能,并且能够与半监督方法相比或略微超过(之前的GCL很难做到) 我们还进行了一些可视化的实验来表明我们可证训练以及节点紧致性设计的合理性。首先是POT能够改进我们设计的节点紧致性,因为POT中显式地优化了这个指标。这也是比较意料之中的。
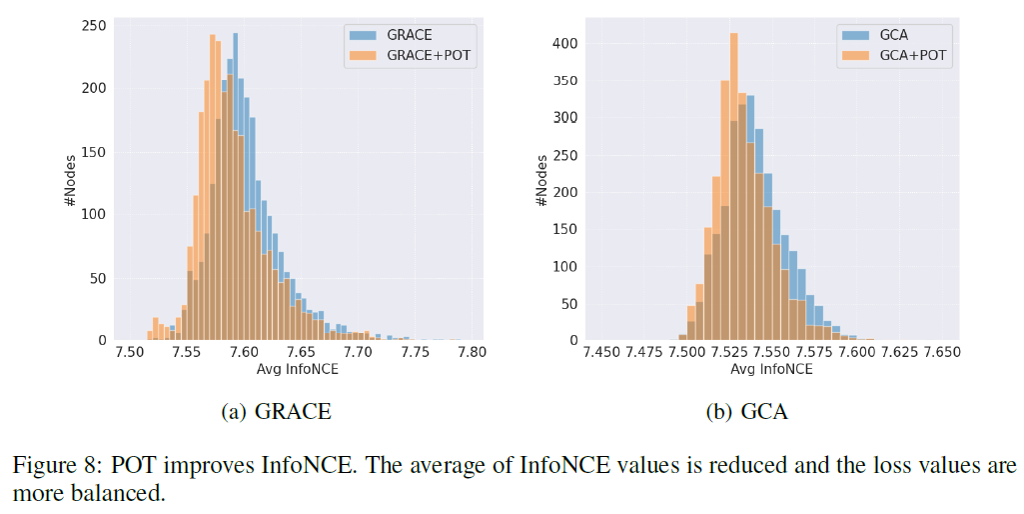
另一方面,POT对于InfoNCE本身的优化也有帮助。可以看到,使用POT之后,节点的InfoNCE整体向左偏移(优化的更好了),并且其分布也更加向中心集中,也就是说原来很多难以训练的节点由于POT的训练而被关注到、优化好了。
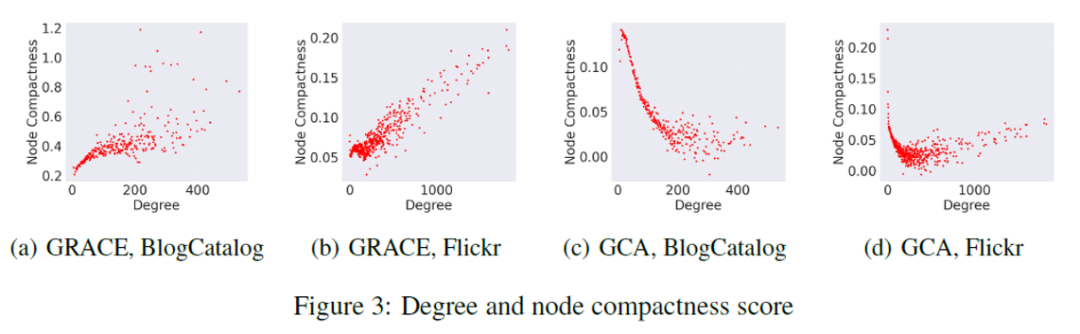
POT能够反映不同增广策略的特点。由于GRACE是所有边以相同概率删掉,而GCA的删除策略与度相关,因此节点在不同GCL增广策略下对增广的敏感程度是不同的。POT的分布反映了这种差异性。
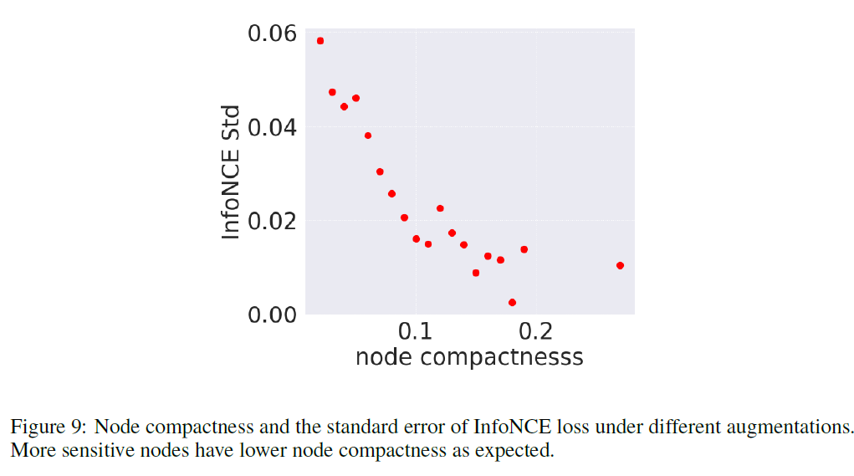
POT如我们所想,确实反映了节点的本质的“结构特性”,也就是在GCL增广下的脆弱程度。我们对同一区间内紧致性的节点的InfoNCE的方差取了平均(方差能够反映这种“脆弱”性)。可以看到,节点紧致性越大,InfoNCE的方差越小,也就是节点越“脆弱”。这个实验结果恰好验证了节点紧致性具有我们所期望的性质。
7. 总结
首先,我们探究了图对比学习的训练情况,发现了其训练不平衡的问题。其次,我们定义“节点紧致性”去描述节点在图对比训练中的本质的“结构特性”。我们基于该指标提出了“可证训练”。这种训练模式对节点的最差训练情况提供了优化上的保证。大量实验验证了我们训练框架的有效性。最后,本方法的思路是将一个优化目标转化为一个优化下界的问题,将普通的训练转化为对训练情况进行保证。这种思路是对训练加以理论保证的一种实现方式。 感谢您对本工作的关注。下面是本工作的信息:E-mail: yuyue1218@bupt.edu.cn Code: https://github.com/VoidHaruhi/POT-GCL Paper: https://arxiv.org/pdf/2309.13944.pdf