

传统观点认为,通过预训练视觉Transformer(ViT)可以学习有用的表示,从而提升下游任务的性能。但这是真的吗?我们对这一问题进行了研究,发现预训练过程中学到的特征和表示并不是必不可少的。令人惊讶的是,仅利用预训练中的注意力模式(即指导信息在不同token之间的流动方式),就足以让模型从零开始学习高质量特征,并在下游任务中取得可比的性能。
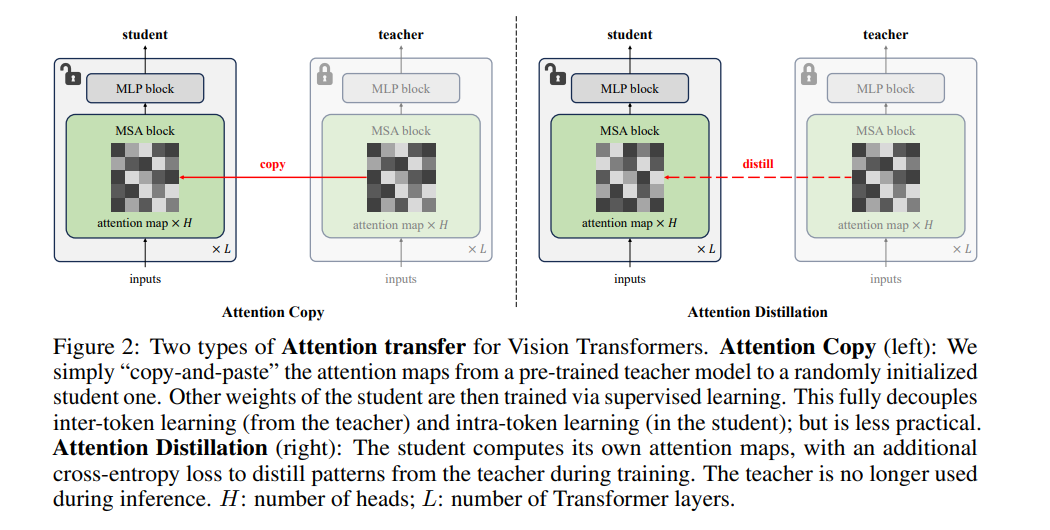
我们通过提出一种简单的方法——注意力迁移(attention transfer),验证了这一点。在这种方法中,仅从预训练的教师ViT中将注意力模式迁移到学生模型,迁移方式可以是直接复制或蒸馏注意力图。由于注意力迁移允许学生模型自行学习特征,将其与经过微调的教师模型进行集成还能进一步提高ImageNet上的准确率。
我们系统性地研究了注意力图充分性的各种方面,包括在分布转移(distribution shift)环境下的表现,在这些环境中,注意力迁移性能不如微调。我们希望这一探索能为预训练的作用提供更深入的理解,同时为微调的标准实践提供一个有用的替代方案。 复现我们结果的代码可在https://github.com/alexlioralexli/attention-transfer获得。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日