军队正在研究改善其多域作战(MDO)中的通信和敏捷性的方法。物联网(IoT)的流行在公共和政府领域获得了吸引力。它在MDO中的应用可能会彻底改变未来的战局,并可能带来战略优势。虽然这项技术给军事能力带来了好处,但它也带来了挑战,其中之一就是不确定性和相关风险。一个关键问题是如何解决这些不确定性。最近发表的研究成果提出了信息伪装,将信息从一个数据域转化为另一个数据域。由于这是一个相对较新的方法,我们研究了这种转换的挑战,以及如何检测和解决这些相关的不确定性,特别是未知-未知因素,以改善决策。

背景
现代世界受到了技术和全球连接的基础设施动态的重大影响。随着这种新环境的出现,许多领域的决策过程面临更大的挑战。领导者和决策者必须考虑各种因素的影响,包括那些属于已知和未知的数据来源[9]。
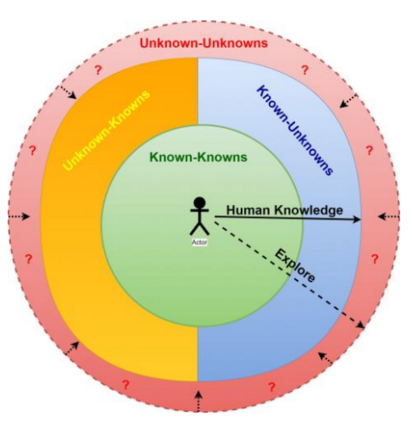
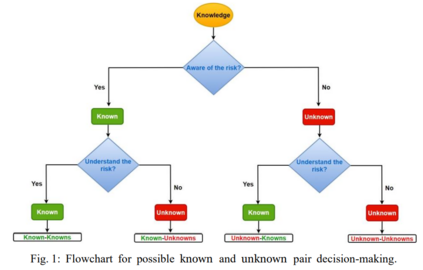
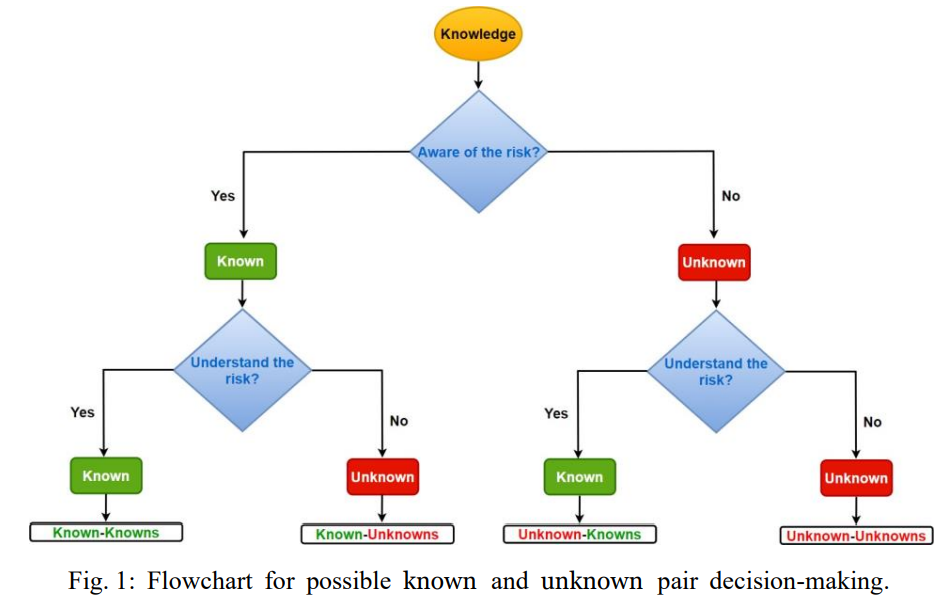
虽然这不是一个新的概念,但在一些论文中已经提出了对已知和未知因素进行分类的定义。当条件是"已知-已知"(Known-Knowns):那么条件是有我们知道和理解的知识,已知-未知(known-Unknowns):条件是有我们不知道但不理解的知识,未知-已知(Unknown-knowns):条件是有我们理解但不知道的知识,以及"未知-未知"(Unknown-Unknowns):条件是有我们不理解也不知道的知识[6]。在图1中,对知识的已知和未知分区的讨论是围绕一个问题展开的。图中所选的是与对风险的认识和理解有关的。
在这四种情况中,"已知-已知"是最明显的一种,人们可以对一个特定的问题有完整的了解,而 "未知-未知"则完全相反,也是最具挑战性的一种。因此,重点应该是制定策略,以发现可能的未知数,从而将其转换为已知数的数据。然而,在许多情况下,这可能不是小事,这可能需要应急计划和适应性技能来应对不可预见的情况。
已知-未知的任务计划需要被彻底观察。然而,由于已知的部分,只要有足够的时间和资源投入,就可以找到一个合理的方案。最后,为了处理未知数[11,22,23],人类是最著名的直觉模型,具有很强的预知能力[5]。因此,包括来自个人或团体的建议可以帮助对那些被遗漏的数据进行分类,从而被机器学习模型认为是未知的。
我们在图2中提供了上述与我们的 "已知 "和 "未知"知识相关的不确定性区域的可视化表示。在这项研究中,我们将未知数视为图像数据中未见或未检测到的对象类别,通过应用第3.1节所述的图像-音频编码方案,这些对象可以被发现或重新归类为已知数。
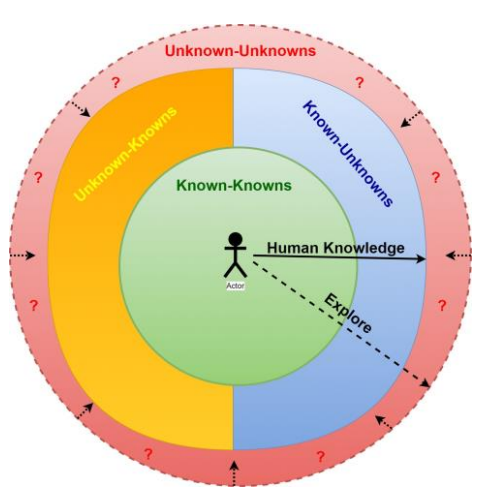
图2:我们提出的方法的可视化表示,说明了已知和未知对的前提。当我们离开绿色区域外的中心,踏入其他颜色的区域时,人类知识的边界变得模糊和混乱。"?"代表需要探索的区域。红色区域的点状周长表示该区域的无界性,因为对该区域及其存在缺乏任何知识。向内的点状箭头表示目标应该是将这个红色区域汇聚到任何可能的黄色、蓝色或绿色区域。按照这个顺序,理想情况下,每一个包络区域都应该被收敛到它所包络的区域。
动机与挑战
任何决策都会受到风险存在的严重影响,任何能够帮助识别和了解已知和未知的过程都是理想的。此外,对未知数据的识别和检测可以使风险最小化。然而,面对先验知识并不奢侈,只有少数数据样本可供分析的情况很常见。军事决策者,如指挥官,在做出关键决定时可能没有什么选择,最终可能完全依赖于他们的专业知识和新数据的输入。他们可能会利用以前的经验来分析传来的信息,并捕捉可能的未知数据,以尽量减少风险。这种方法可能仍然不能涵盖所有的未知因素。
本文工作的动机是决策中的主要挑战,即我们完全依靠有意义的和足够的数据来支持决策。另外,决策者必须对用于提供数据支持决策的技术的性能和结果有信心。因此,我们研究了当深度学习模型的性能由于缺乏丰富的数据样本而受到限制时,如何提高决策过程中的信任水平。我们关注一个训练有素的模型如何能够高精度地检测和识别未知(未检测到的)物体;该模型区分新的观察是属于已知还是未知类别的能力。
这项工作背后的动力来自于美国陆军的IoBT CRA项目中的一个问题,该项目将设备分为:红色(敌人)、灰色(中立)、蓝色(朋友)资产。类的属性和行为是非常不确定的,与前面提到的第1.1节中的已知或未知的挑战有关,因为要么来自友好来源的数据可能被破坏,要么敌人有可能被欺骗成友好数据来源[1,2,3,4]。因此,以较高的置信度对这些资产进行分类是一项具有挑战性的任务。应对这一挑战的最初步骤是,从这些设备中获取数据,例如图像、文本或音频,并调查未知数据是否可以被分类为已知数据。
提出的方法
我们的方法包括选择图像数据和建立一个深度学习框架来解决分类的挑战。图像类被特别选择来代表类似于军事行动中常用的地形景观。
因此,我们的框架由两个独立的部分组成;对从原始数据集获得的图像进行分类,以及对使用图像-音频编码方案从图像获得的音频信号进行分类(第3.1节)。
由于编码将数据从一个数据域(图像)转换到另一个数据域(音频),预计会有信息损失。为了解决上述转换后的数据样本的挑战,我们提出了以下问题:当数据被编码方案转换后,我们能否提高模型的性能,从而将未知数转换成已知数?我们怎样才能弥补模型的低性能,从而使以前的未知数据能够用于提高决策过程中的可信度?在模型的性能和正确分类数据以支持决策之间的权衡是什么?